



Max-Former团队 投稿
量子位 | 公众号 QbitAI
脉冲神经网络(SNN)不用再纠结二进制短板了。
靠补全高频细节,Max-Former精度提升还省电。
香港科技大学(广州)等单位的研究团队发表于NeurIPS 2025的论文揭示,SNN性能不佳的根源并非二进制激活本身,而在于频率偏置问题。

团队发现,脉冲神经元本质上会抑制高频成分,并倾向于传播低频信息。这种频域上的不平衡,才是导致SNN特征表示能力退化的「罪魁祸首」。
怎么说?
SNN被忽视的频率缺陷
一直以来脉冲神经网络(SNN)因其类脑的计算方式和事件驱动的特性,被寄予实现超低功耗智能计算的厚望。
然而,其性能往往落后于传统人工神经网络(ANN)。一个被广泛接受的解释是:SNN中传递信息的只有0/1的二进制脉冲,这导致了严重的信息损失。
因此,长期以来,学界普遍将SNN的性能差距归因于“二值激活带来的信息损失”。
但该研究指出,这一主流观点存在一个未被深入剖析的盲区:在标准深度学习研究中,低比特乃至二值网络同样能取得逼近全精度的性能。
更重要的是,SNN在时间轴上运行,单个时间步的脉冲虽为二值,但跨越多个时间步的脉冲序列理论上至少可编码 log(n)-bit 的精度的信息。因此,二进制本身不应成为性能瓶颈。
那么,真正的瓶颈究竟何在?
研究团队将视角转向了频域。他们通过理论分析与大量实验对这一问题提供了新的见解:脉冲神经元在网络层面上,本质上是一个低通滤波器。
这就像人眼散光,导致无法看清局部的、高频的细节。
正是这种特性,使得网络在处理信息时,难以捕捉关键的细节和纹理(高频信息),从而限制了其性能上限。
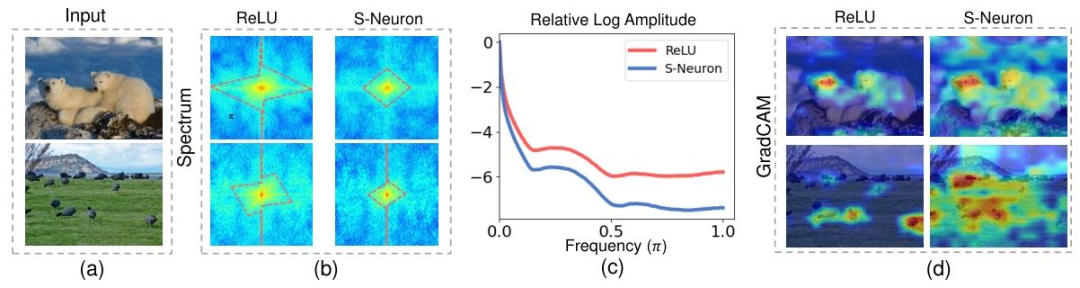
如上图所示,团队通过直观的傅里叶频谱分析表明,在“输入→激活→加权”的完整信息流中,与ReLU等传统激活函数会扩展信号的频率带宽不同,脉冲神经元会导致高频成分的快速消散(b-c),进而导致特征模糊(d)。
反直觉发现:脉冲神经网络中,高频算子表现优于低频
为了验证这一发现,研究者进行了一个简单而直接的对照实验:在脉冲Transformer中,分别采用平均池化(Avg-Pool,低通)和最大池化(Max-Pool,高通)作为token混合器。
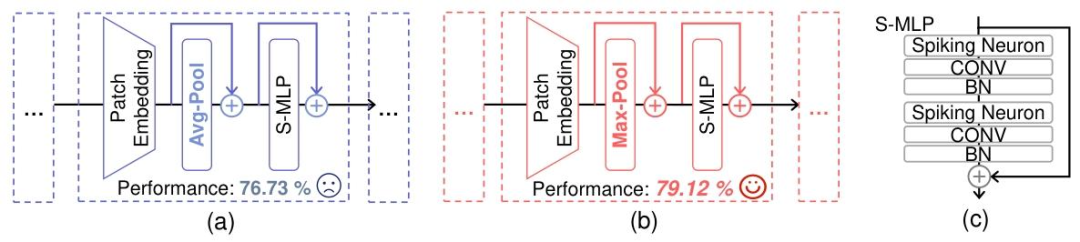 △使用平均池化和最大池化的脉冲Transformer架构示意图
△使用平均池化和最大池化的脉冲Transformer架构示意图
结果显示,在CIFAR-100数据集上,使用Avg-Pool的性能为76.73%,而将其替换为Max-Pool后,性能跃升至79.12%,提升了2.39%。
这与此前非脉冲Transformer的研究结论截然相反。
在ANN Transformer,如PoolFormer中,倾向于捕捉全局模式(低频)的Avg-Pool是更常见的选择。
但在脉冲Transformer中,能够保留局部细节(高频)的Max-Pool反而表现更佳。
脉冲神经元是「低通滤波器」
因此,研究团队从理论上证明了脉冲神经元的低通滤波特性。
通过分析脉冲神经元充电过程的传递函数,他们发现其本质上是一个一阶无限脉冲响应低通滤波器。
论文中形象地指出,尽管单个脉冲在频谱上看似乎是「全通」的,但其波形所产生的高频成分是虚假的,无法在网络中有效传播。
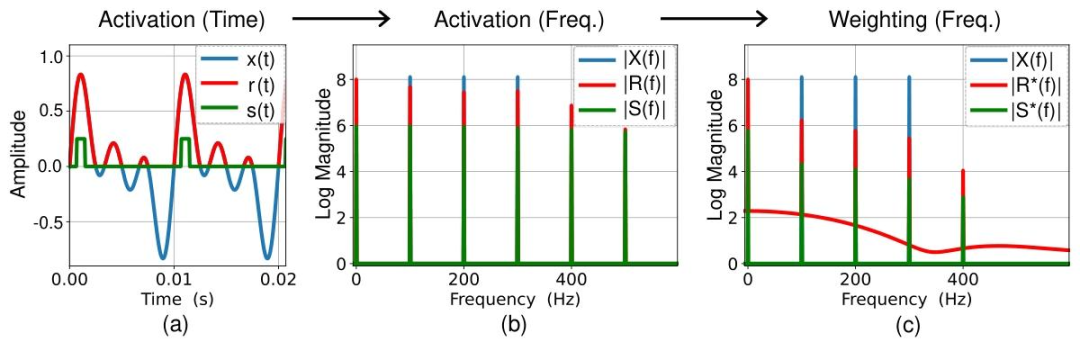 △时频域分析表明,脉冲神经元波形产生的高频信息无法向后传递(b),使得网络中高频信息逐渐消散(c)
△时频域分析表明,脉冲神经元波形产生的高频信息无法向后传递(b),使得网络中高频信息逐渐消散(c)
论文作者解释道:
当这一过程在网络中逐层串联时,其低频偏好会被急剧放大,这正是网络深层特征退化的根源。
Max-Former:针对频率偏置的脉冲Transformer新架构
基于这一核心洞察,研究者提出了名为Max-Former的新型脉冲Transformer架构。旨在通过两个轻量级的“频率增强镜片”,来补偿这种天生的「低频偏好」
这两个算子分别是:
Patch Embedding中的额外Max-Pool:在信息输入的源头,就通过高通算子主动注入高频信号。
用深度卷积(DWC)替代早期阶段的自注意力:自注意力机制计算复杂且倾向于平滑特征,而深度卷积能有效保留局部的高频细节,同时其计算复杂度远低于自注意力。
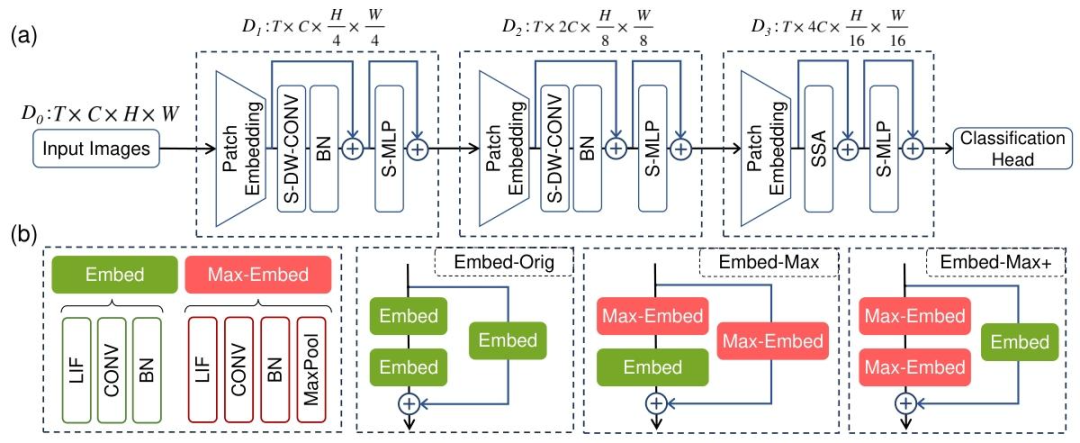 △Max-Former网络架构图
△Max-Former网络架构图
值得注意的是,与具有二次计算复杂度的自注意力相比,Max-Pool和DWC相对于序列长度仅需线性复杂度,且参数效率更高。
能效双丰收
Max-Former在多项基准测试中展现了卓越的性能:
在ImageNet上,Max-Former-10-768(4时间步)取得了82.39%的Top-1准确率,以更少的参数量(63.99Mvs66.34M)大幅超越Spikformer达7.58%。
在其他小规模数据集以及神经形态数据集上,Max-Former也均达到SOTA的性能。
并且,在实现性能突破的同时,能量消耗降低了超过30%。
这证明,用高通算子进行优化,可以实现性能与能效的兼得。
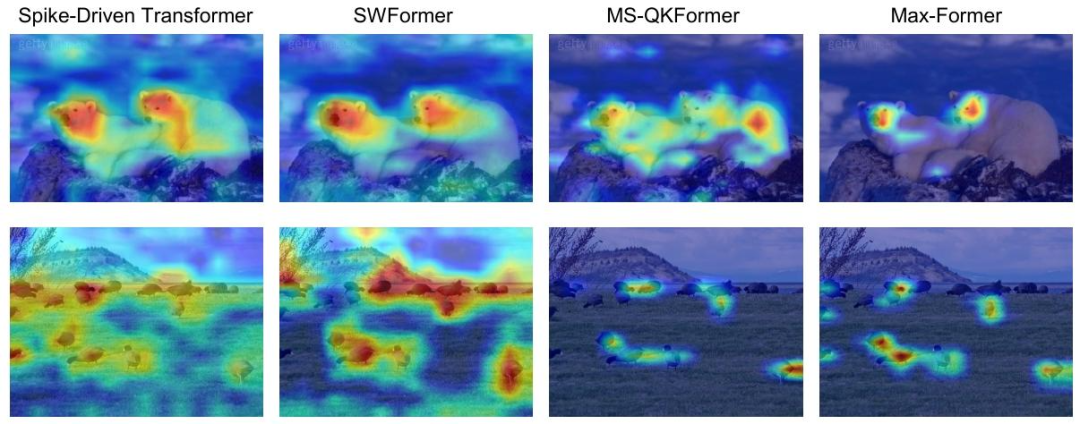 △Grad-CAM可视化表明,Max-Former中的频率增强算子有效矫正了”散光”现象
△Grad-CAM可视化表明,Max-Former中的频率增强算子有效矫正了”散光”现象
普适性验证:卷积架构同样受益
为了证明高频信息对SNN的重要性并非Transformer架构特有,研究者将这一洞察延伸到经典的卷积架构中,提出了Max-ResNet。
结果显示,仅通过添加少量Max-Pooling操作,Max-ResNet-18就在CIFAR-10上达到97.17%,在CIFAR-100上达到83.06%。
这意味着,相比基线模型,其准确率分别大幅提升了2.25%/ 6.65%,创造了卷积类SNN的新SOTA纪录。
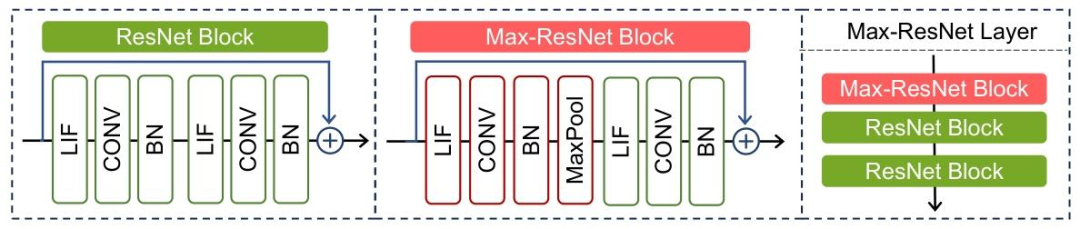 △Max-ResNet网络架构图
△Max-ResNet网络架构图
这项工作为理解SNN的性能瓶颈提供了全新的视角,SNN的优化路径或许不应是简单地模仿ANN的成功设计。
感兴趣的朋友可到原文了解更多细节~
论文链接: https://arxiv.org/pdf/2505.18608


















 209
209

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









