




金磊 克雷西 发自 凹非寺
量子位 | 公众号 QbitAI
今年,AI大厂采购GPU的投入又双叒疯狂加码——
马斯克xAI打算把自家的10万卡超算扩增10倍,Meta也计划投资100亿建设一个130万卡规模的数据中心……
GPU的数量,已经成为了互联网企业AI实力的直接代表。
的确,建设AI算力,这种堆卡模式是最简单粗暴的,但实际上,AI集群却并非是卡越多就越好用。
GPU虽然计算性能好,但是在集群化的模式下依然有很多挑战,即便强如英伟达,也面临通信瓶颈、内存碎片化、资源利用率波动等问题。
简单说就是,由于通信等原因的限制,GPU的功力没办法完全发挥出来。
所以,建设AI时代的云数据中心,不是把卡堆到机柜里就能一劳永逸,现有数据中心的不足,需要用架构的创新才能解决。
最近,华为发布了一篇60页的重磅论文,提出了他们的下一代AI数据中心架构设计构想——Huawei CloudMatrix,以及该构想的第一代产品化的实现CloudMatrix384。相对于简单的“堆卡”,华为CloudMatrix给出的架构设计原则是,高带宽全对等互连和细粒度资源解耦。
这篇论文干货满满,不仅展示了CloudMatrix384的详细硬件设计,并介绍了基于CloudMatrix384进行DeepSeek推理的最佳实践方案——CloudMatrix-Infer。

那么,华为提出的CloudMatrix384到底有多强?简单地说,可以概括成三个方面——
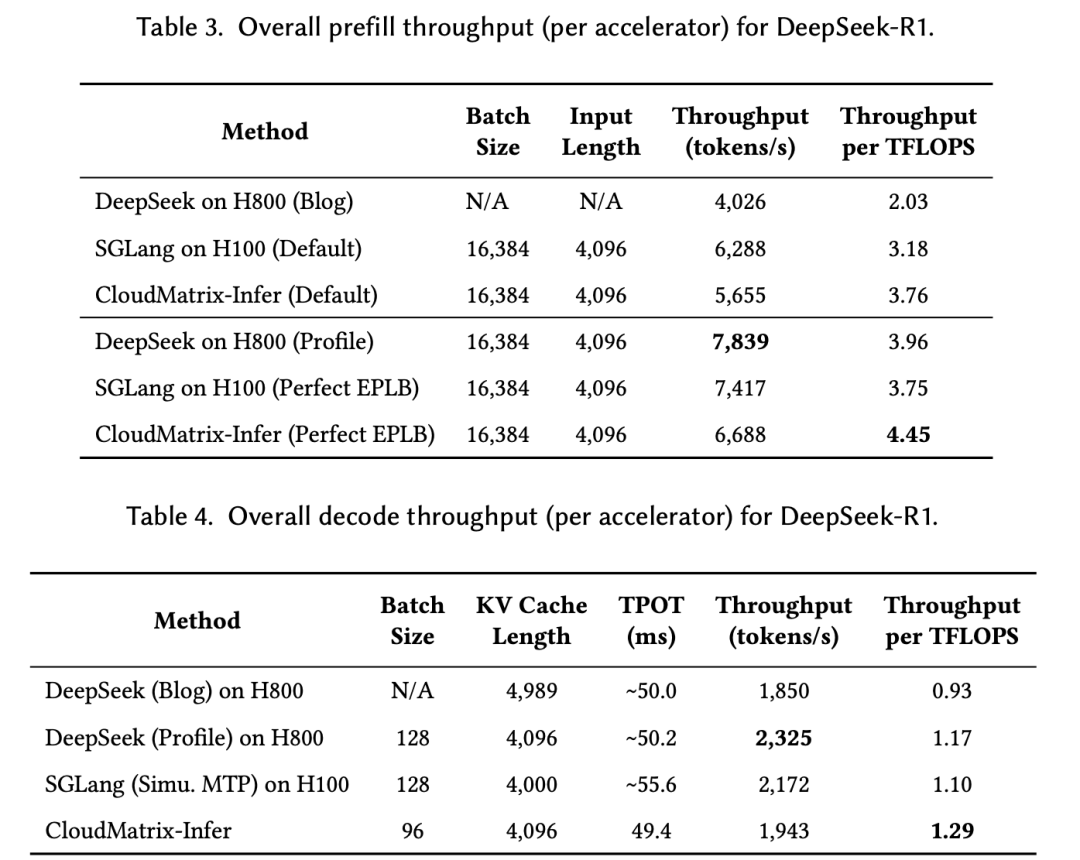
够高效:预填充吞吐量达6688 token/s/NPU,解码阶段1943 token/s/NPU;计算效率方面,预填充达4.45 token/s/TFLOPS,解码阶段1.29 token/s/TFLOPS,均超过业绩在NVIDIA H100/H800上实现的性能;
够准确:DeepSeek-R1模型在昇腾NPU上INT8量化的基准测试精度与官方API一致;
够灵活:支持动态调整推理时延SLO,在15ms严格延迟约束下仍维持538 token/s解码吞吐量。
AI数据中心架构,华为云提前迈出了一步
在深入剖析这篇重磅论文之前,我们有必要先来了解一下“Why we need CloudMatrix384”。
若是一句话来概括,就是满足不了当下AI发展的算力需求。
因为传统的AI集群,它内部运行的过程更像是“分散的小作坊”,每个服务器(节点)有种各玩各的感觉;算力、内存和网络资源等等,都是被固定分配的。
在这种传统模式下,AI集群一旦遇到超大规模的模型,就会出现各种问题,例如算力不够、内存带宽卡脖子、节点间通信慢如蜗牛等等。
而华为在这篇论文中要做的事情,就是提出一种新的模式,把这种“小作坊”改成“超级算力工厂”——
以CloudMatrix(首个
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 21
21

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









