



vivo AI Lab 投稿
量子位 | 公众号 QbitAI
Scaling Law不仅在放缓,而且不一定总是适用!
尤其在文本分类任务中,扩大训练集的数据量可能会带来更严重的数据冲突和数据冗余。
要是类别界限不够清晰,数据冲突现象就更明显了。
而文本分类又在情感分析、识别用户意图等任务中极为重要,继而对AI Agent的性能也有很大影响。
最近,vivo AI Lab研究团队提出了一种数据质量提升(DQE)的方法,成功提升了LLM在文本分类任务中的准确性和效率。

实验中,DQE方法以更少的数据获得更高的准确率,并且只用了近一半的数据量,就能有效提升训练集的训练效率。
作者还对全量数据微调的模型和DQE选择的数据微调的模型在测试集上的结果进行了显著性分析。
结果发现DQE选择的数据在大多数测试集上都比全量数据表现出显著的性能提升。
目前,此项成果已被自然语言处理顶会COLING 2025主会接收。
数据质量提升方法长啥样?
在自然语言处理中,文本分类是一项十分重要的任务,比如情感分析、意图识别等,尤其现在企业都在推出各自的AI Agent,其中最重要的环节之一,就是识别用户的意图。
不同于传统的BERT模型,基于自回归的大语言模型的输出往往是不可控的,而分类任务对输出的格式要求较高。
通过在提示词中加入few-shot可以有效地改善这一现象,但是基于提示词的方法带来的提升往往有限。指令微调可以有效地改善模型的性能。
在文本分类任务中,缺乏一种有效的手段来获取高质量的数据集。OpenAI提出了缩放定律(Scaling Law),认为大语言模型的最终性能主要取决于三个因素的缩放:计算能力、模型参数和训练数据量。
然而这一定律并不总是适用,尤其在文本分类任务中,扩大训练集的数据量会可能会带来更加严重的数据冲突现象和数据冗余问题。尤其类别的界限不够清晰的时候,数据冲突的现象更加明显。
下面是vivo AI Lab团队提出的数据质量提升(DQE)方法的具体方法设计。
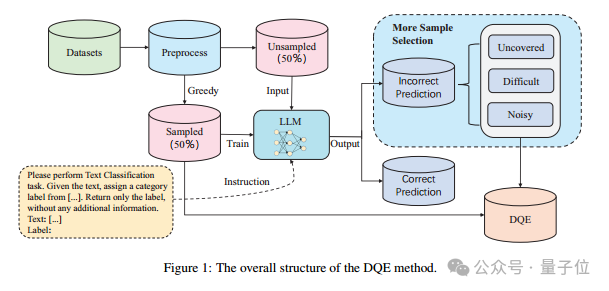
首先,作者对训练集进行了初步的数据清洗工作,包含处理具有缺失值的数据、query和标签重复的数据以及标签不一致数据(同一条query对应多个不同的标签)。
然后,使用文本嵌入模型,将文本转换为语义向量。再通过贪婪采样的方法,随机初始化一条数据作为初始向量,然后每次选择距离向量中心最远的数据加入到新的集合中,以提升数据的多样性。
接着,更新这个集合的向量中心,不断的重复这个过程,直到收集了50%的数据作为sampled,剩下未被选中的50%的数据集作为unsampled,然后使用sampled数据集微调大语言模型预测unsampled。
通过结合向量检索的方式,将unsampled中预测结果错误的数据分为Uncovered、Difficult和Noisy三种类型。
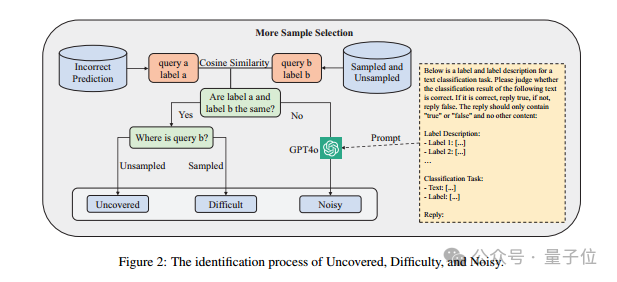
下面是三种类型的数据的识别原理:
Uncovered:主要指sampled中未覆盖的数据,如果预测错误的数据与最相似的数据具有相同的标签,并且最相似的数据位于unsampled中,则认为该数据相关的特征可能没有参与sampled模型的微调,从而导致unsampled中的该条预测结果错误。
Difficult:主要指sampled中难以学会的困难样本,如果预测错误的数据与最相似的数据具有相同的标签,并且最相似的数据位于sampled,则认为该数据相关的特征已经在sampled中参与过模型的微调,预测错误可能是因为这条数据很难学会。
Noisy:主要是标签不一致导致的噪声数据,如果预测错误的数据与最相似的数据具有不同的标签。则怀疑这两条数据是噪声数据。大多数文本分类任务的数据集都是共同手工标注或者模型标注获得,都可能存在一定的主观性,尤其在类别界限不清晰的时候,标注错误的现象无法避免。这种情况下,作者通过提示词,使用GPT-4o进一步辅助判断。
效果如何?
作者基于多机多卡的L40s服务器上通过swift框架进行了全参数微调,选择开源的Qwen2.5-7B-Instruct模型作为本次实验的基础模型。
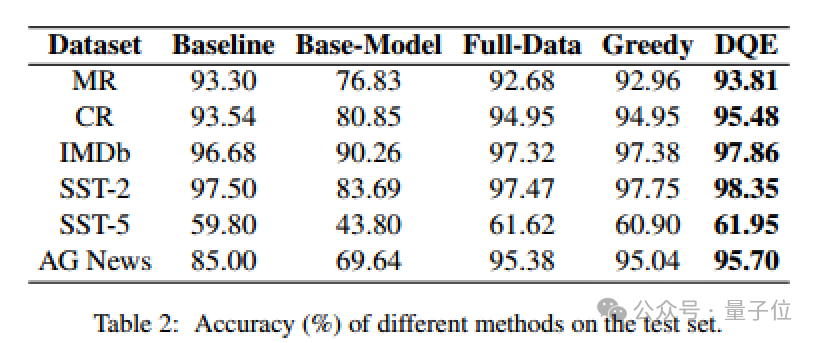
作者与PaperWithCode中收录的最好的结果以及全量数据微调的方法进行了对比,作者分别在MR、CR、IMDb、SST-2、SST-5、AG News数据集中进行了对比实验。
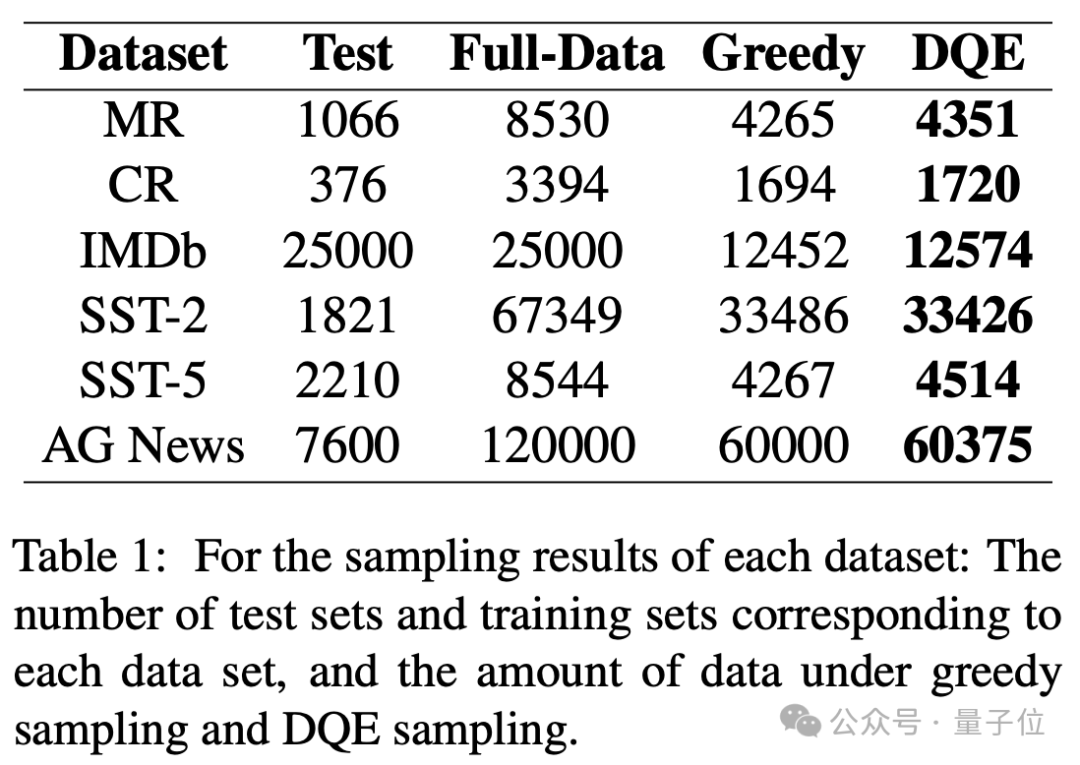
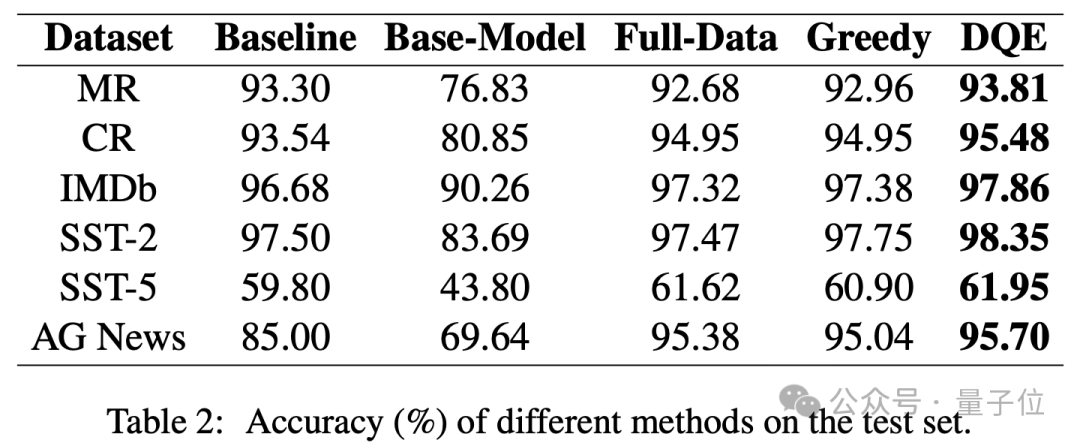
从实验结果可以看出,DQE方法以更少的数据获得更高的准确率,并且只用了近乎一半的数据量,可以有效地提升训练集的训练效率。
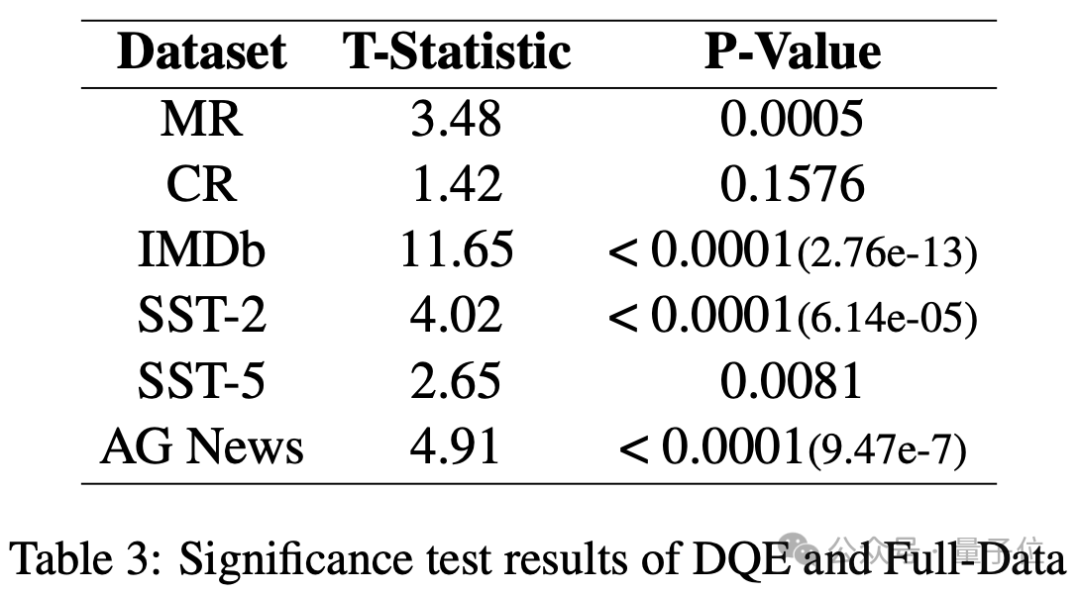
同时,作者页进一步对全量数据微调的模型和DQE选择的数据微调的模型在测试集上的结果进行了显著性分析。将预测结果正确的数据赋值为1,将预测结果错误的数据赋值为0,通过t检验来评估模型之间性能差异的统计显著性。
从表中可以发现DQE选择的数据在大多数测试集上都比全量数据表现出显著的性能提升。
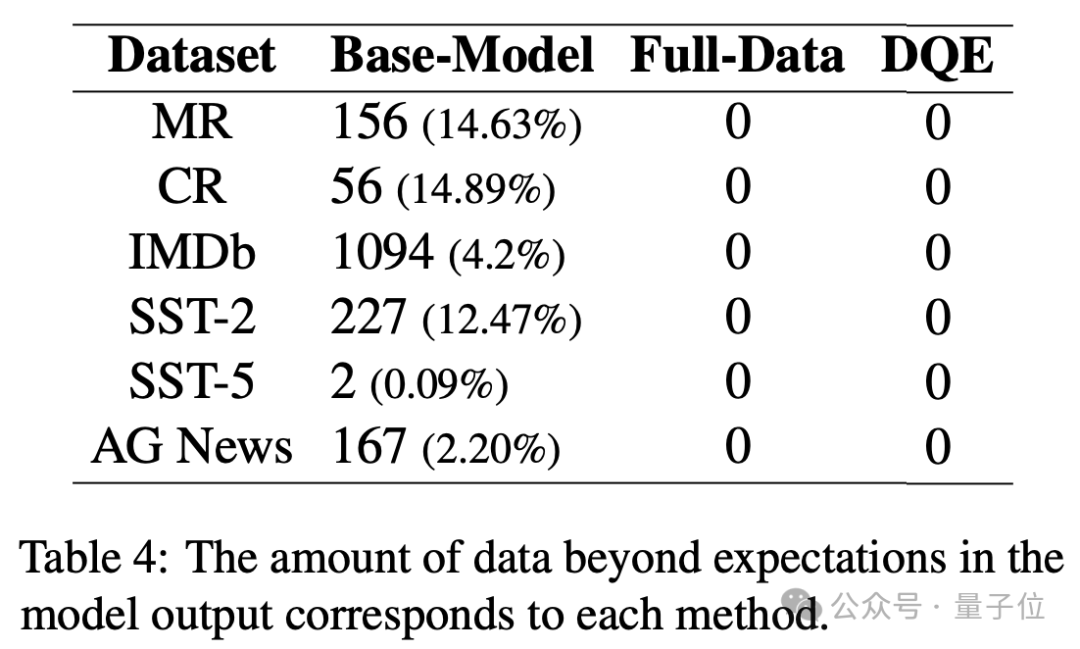
与传统的BERT模型不同的是,生成式的模型往往是不可控的,作者进一步分析了指令跟随结果。
结果表明,不管是全量数据微调还是DQE方法微调,都可以有效地提升大语言模型的指令跟随能力,按照预期的结果和格式输出。
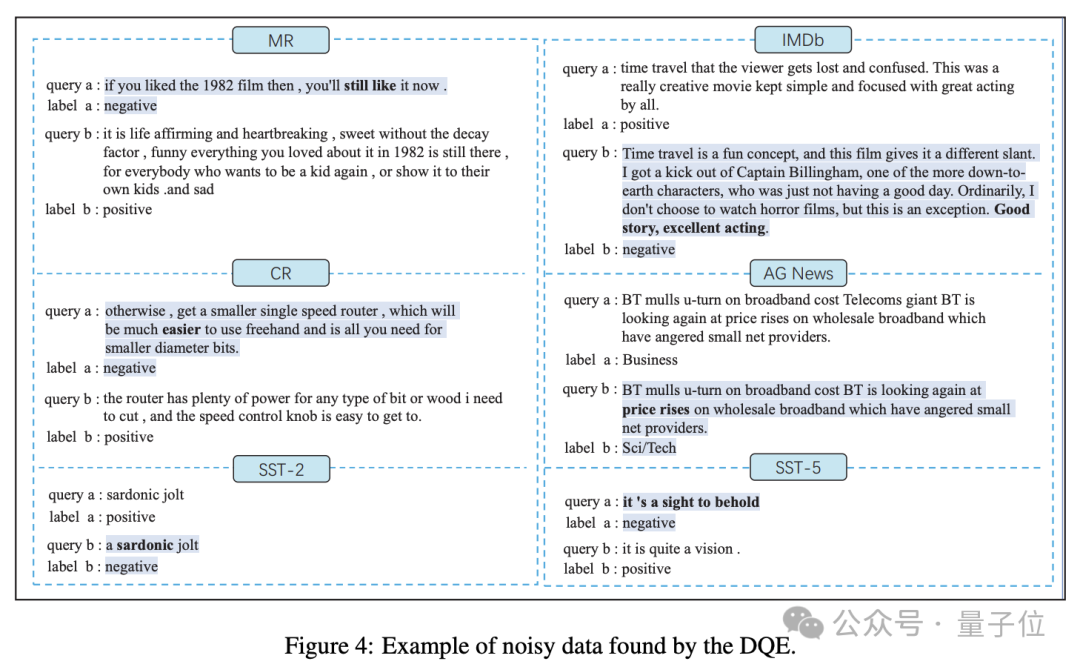
对于分类任务来讲,当数据量足够大时,很难避免标签噪声现象。即便是被各大顶级学术期刊和会议广泛使用的数据集,也无法避免标签噪声现象。
作者分析了一部分通过实验找出的噪声数据,并且给出了开源数据集中的标签噪声的示例。
值得注意的是,在数据采样过程中,本研究使用贪心算法将数据集划分为sampled和unsampled。此外,作者根据文本相似度将unsampled分类为uncovered、difficult和noisy数据。
接下来,分析sampled中的这三种类型:
由于该数据将用于最终的训练集,因此它不包含uncovered。
关于difficult,将来自unsampled中识别为difficult的样本会加入到最终的训练集,这uncovered中的difficult和sampled是成对存在的,从而部分减轻了采样数据中的difficult问题。
对于noisy数据,使用DQE可以在sampled和unsampled之间识别出大多数成对的噪声实例。
由于使用sampled贪婪采样策略,在sampled内遇到成对的相似噪声数据的概率会相对较低。从理论上解释了本方案的有效性。
论文地址:https://arxiv.org/abs/2412.06575



















 21
21

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









