




梦晨 发自 凹非寺
量子位 | 公众号 QbitAI
新架构,再次向Transformer发起挑战!
核心思想:将RNN中的隐藏状态换成可学习的模型。
甚至在测试时都可以学习,所以该方法称为TTT(Test-Time Training)。
共同一作UC伯克利的Karen Dalal表示:我相信这将从根本上改变语言模型。

一个TTT层拥有比RNN表达能力更强的隐藏状态,可以直接取代Transformer中昂贵的自注意力层。
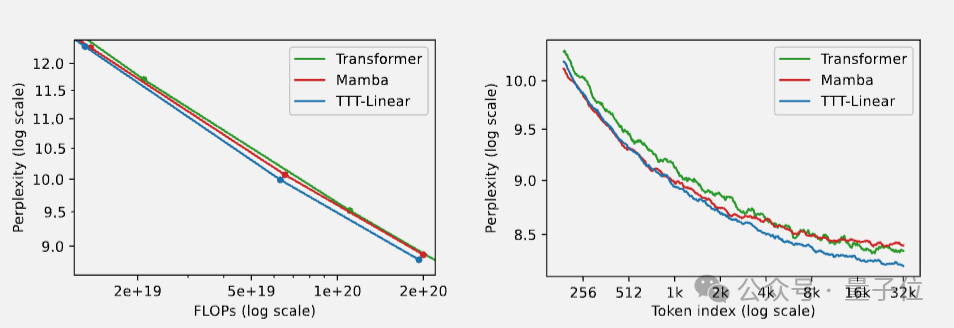
在实验中,隐藏状态是线性模型的TTT-Linear表现超过了Transformer和Mamba,用更少的算力达到更低的困惑度(左),也能更好利用长上下文(右)。
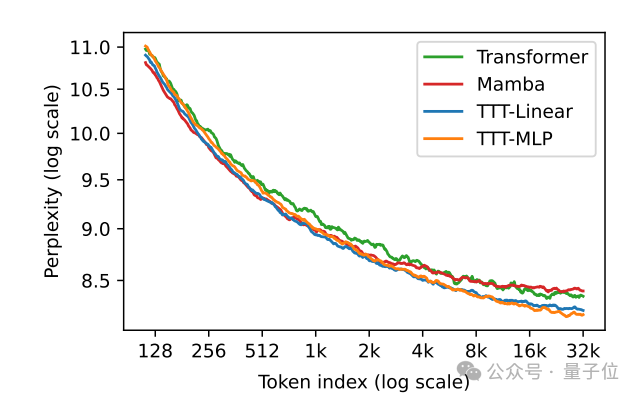
此外,隐藏状态是MLP模型的TTT-MLP在32k长上下文时表现还要更好。
Karen Dalel还指出,理论上可学习的隐藏状态可以是任意模型,对于更长上下文来说,可以是CNN、甚至可以是完整的Transformer来套娃。
目前刚刚出炉的TTT论文已经在学术界引起关注和讨论,斯坦福博士生Andrew Gao认为,这篇论文或许能成为下一篇Attention is all you need。

另外有人表示,众多新架构能否真正击败Transformer,还要看能不能扩展到更大规模。
Karen Dalel透露,马上就会推出7B模型。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 27
27

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









