



 腾讯AILab和南洋理工大学的研究者提出了一种免调优方法FreeNoise,可让预训练视频模型生成长达17秒的视频,且支持多文本输入。FreeNoise通过重新调度噪声解决现有模型的帧数限制和单一文本生成问题,提高了性能和效率。
腾讯AILab和南洋理工大学的研究者提出了一种免调优方法FreeNoise,可让预训练视频模型生成长达17秒的视频,且支持多文本输入。FreeNoise通过重新调度噪声解决现有模型的帧数限制和单一文本生成问题,提高了性能和效率。
丰色 发自 凹非寺
量子位 | 公众号 QbitAI
想要AI生成更长的视频?
现在,有人提出了一个效果很不错的免调优方法,直接就能作用于预训练好的视频扩散模型。
它最长可支持512帧(假设帧率按30fps算,理论上那就是能生成约17秒长的作品了)。

可应用于任何视频生成模型,比如AnimateDiff、LaVie等等。
以及还能支持多文本生成,比如可以让骆驼一会跑一会停:

(提示词:”A camel running on the snow field.” -> “…… standing ……”)
这项成果来自腾讯AI Lab、南洋理工大学以及港科大,入选了ICLR 2024。

值得一提的是,与此前业内性能最佳的同类方法带来255%的额外时间成本相比,它仅产生约17%的时间成本,因此直接可以忽略不计。
可以说是成本和性能两全了~
具体来看看。
通过重新调度噪声实现
该方法主要解决的是两个问题:
一是现有视频生成通常在有限数量的帧上完成训练,导致推理过程中无法生成高保真长视频。
二是这些模型还仅支持单文本生成(即使你给了“一个人睡在桌子上,然后看书”这种提示词,模型也只会响应其中一个条件),而应用到现实中其实是需要多文本条件,毕竟视频内容是会随时间不断变化的。
在此,作者首先分析视频扩散模型的时间建模机制,并研究了初始噪声的影响,提出免调优、实现更长视频推理的FreeNoise。
具体而言,以VideoLDM模型为例,它生成的帧不仅取决于当前帧的初始噪声,还取决于所有帧的初始噪音。
这意味着,由于临时注意力层负责促成整个交互,所以对任何帧的噪声重新采样都会显著影响其它帧。
产生的问题就是我们要想保持原视频主要内容的同时引入新东西就很难。
在此,作者检查VideoLDM的时间建模机制发现,其中的时间注意力模块是顺序无关的,而时间卷积模块是顺序相关的。
实验观察表明,每帧噪声是决定视频整体外观的基础,而它们的时间顺序会影响建立在该基础上的内容。
受此启发,作者提出了FreeNoise,其关键思想是构建一个具有长程相关性的噪声帧序列,并通过基于窗口的融合对其进行时间关注。
它主要包括两个关键设计:局部噪声去除和基于窗口的注意力融合。
通过将局部噪声混洗应用于固定随机噪声帧序列以进行长度扩展,作者实现了具有内部随机性和长程相关性的噪声帧序列。
同时,基于窗口的注意力融合使预先训练的时间注意力模块能够处理任何较长的帧。
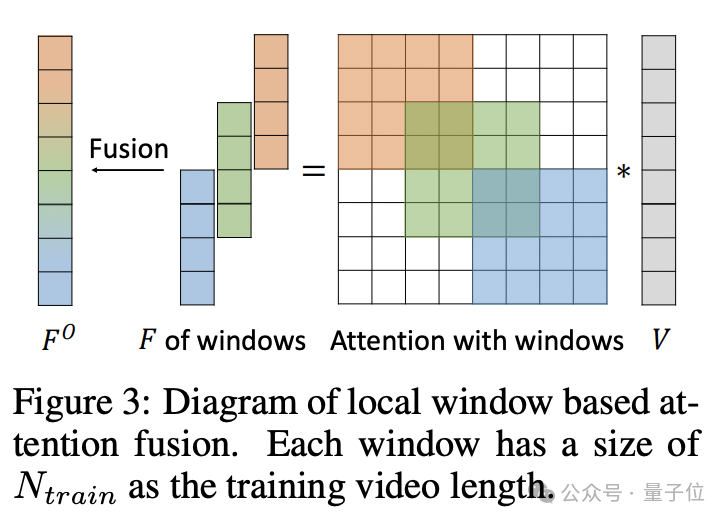
并且最重要的是,重叠窗口切片和合并操作只发生在时间注意力上,而不会给VideoLDM的其他模块带来计算开销,这也大大提高了计算效率。
接下来,为了解决多文本条件问题,作者则提出了动作注入(Motion Injection)方法。
其核心利用的是扩散模型不同步骤在去噪过程中恢复不同级别信息(图像布局、物体形状和精细视觉细节)的特性。
在模型完成上一个动作之后,该方法就在与物体形状相关的时间步长内逐渐注入新的运动。
这样的操作,既保证多提示长视频生成,又具备很好的视觉连贯性。
超越此前最先进的无调优方法
首先来看长视频生成的结果。
可以看到,FreeNoise诠释“宇航服吉娃娃”和“熊猫吃披萨”这两个场景最为连贯自然。
相比之下,直接推理的(最左列)的狗有严重伪影且没有生成背景,Gen-L-Video(此前最先进的无调优方法)则由于无法保持长距离的视觉一致性,存在明显内容突变。

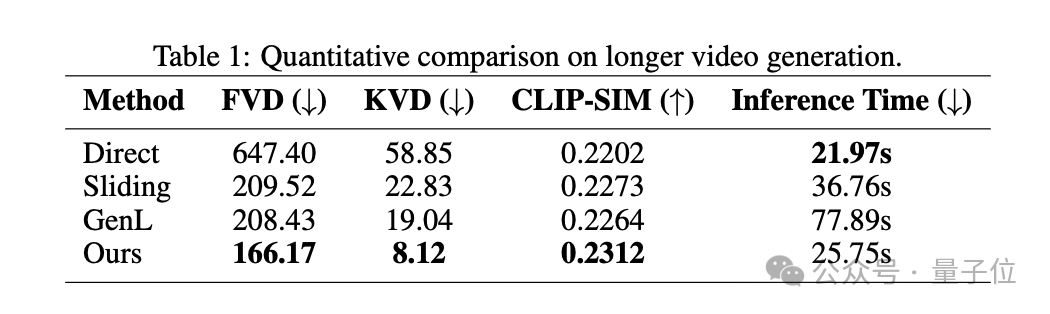
定性结果也用数据证明了FreeNoise的效果:
其中CLIP-SIM的得分代表该方法做到了良好的内容一致性。
其次是多文本条件生成效果。
可以看到该方法(中间列和最右列)可以实现连贯的视觉显示和运动:
骆驼从奔跑逐渐变为站立,远处的山脉一直保持同样的外观。

定性结果如下:
可以看到该方法在内容一致性、视频质量和视频文本对齐都实现SOTA,且与第二名拉开的差距几乎达到两倍之多。

最后,再给大家展示一下FreeNoise用在潜视频扩散模型AnimateDiff、LaVie上的效果。
AnimateDiff:
第一列为原效果,第二列为应用后的效果。

LaVie:

效果提升都是肉眼可见的~
哦对,还有生成的满打满算512帧的视频,大家觉得效果如何呢:
通讯作者之一是汤晓鸥弟子
本文一共7位作者。
一作为南洋理工大学计算机科学与工程学院博士生邱浩楠。
他的研究方向为AIGC、对抗性机器学习和深伪检测,本科毕业于港中文。

通讯作者有两位:
一位是腾讯AI Lab视觉计算中心研究员Menghan Xia。
他的研究方向为计算机视觉和深度学习,尤其是图像/视频的生成和翻译。
Menghan Xia博士毕业于港中文,本硕先后毕业于武汉大学的摄影测量与遥感学、模式识别与智能系统专业。

另一位是南洋理工大学计算机科学与工程学院助理教授刘子纬。
他2017年博士毕业于港中文,师从汤晓鸥教授和王晓刚教授。
毕业后曾在UC伯克利做博士后、港中文担任四年研究员。

论文:
https://arxiv.org/abs/2310.15169
Huggingface体验demo:
https://huggingface.co/spaces/MoonQiu/LongerCrafter
— 完 —
点这里👇关注我,记得标星哦~



















 31
31

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









