







- 01 hudi 1.0.1源码编译(常见问题处理)
- 02 hudi 命令大全
1. hudi命令大全
1.1. 命令大全
注意:各个命令详细参数可以查看org.apache.hudi.cli.commands对应的class
归档提交命令
- trigger archival: 触发归档
- show archived commits: 从归档文件读取提交并显示详情
- show archived commit stats: 从归档文件读取提交并显示文件组详情
引导命令
- bootstrap run: 为当前 Hudi 表运行引导操作
- bootstrap index showmapping: 显示引导索引映射
- bootstrap index showpartitions: 显示引导索引分区
内置命令
- help: 显示可用命令的帮助信息
- stacktrace: 显示上一个错误的完整堆栈跟踪
- clear: 清除Shell屏幕
- quit, exit: 退出Shell
- history: 显示或保存之前运行的命令历史
- version: 显示版本信息
- script: 从文件中读取并执行命令
清理命令
- cleans show: 显示清理记录
- clean showpartitions: 显示清理的分区级别详情
- cleans run: 运行清理
聚类命令
- clustering run: 运行聚类
- clustering scheduleAndExecute: 运行聚类。首先制定一个集群计划并立即执行该计划
- clustering schedule: 调度聚类
提交命令
- commits compare: 与另一个 Hoodie 表比较提交
- commits sync: 与另一个 Hoodie 表同步提交
- commit showpartitions: 显示提交的分区级别详情
- commits show: 显示提交
- commits showarchived: 显示归档的提交
- commit showfiles: 显示提交的文件级别详情
- commit show_write_stats: 显示提交的写入统计信息
压缩命令
- compaction run: 为给定的时刻运行压缩
- compaction showarchived: 显示特定压缩时刻的详细信息
- compaction scheduleAndExecute: 调度压缩计划并执行该计划
- compaction repair: 重命名文件以使其与Hoodie元数据所要求的时间线一致。用于当压缩未调度失败部分时。
- compaction schedule: 调度压缩
- compaction show: 显示特定压缩时刻的详细信息
- compaction unscheduleFileId: 取消调度某个文件ID的压缩
- compaction validate: 验证压缩
- compaction unschedule: 取消调度压缩
- compactions show all: 显示所有在活跃时间线上的压缩
- compactions showarchived: 显示指定时间窗口的压缩详情
差异命令
- diff partition: 检查文件在一系列提交中的差异。仅用于分区表。
- diff file: 检查文件在一系列提交中的差异
导出命令
- export instants: 从时间线导出快照及其元数据
文件系统视图命令
- show fsview all: 显示整个文件系统视图
- show fsview latest: 显示最新的文件系统视图
HDFS Parquet导入命令
- hdfsparquetimport: 将Parquet表导入Hoodie表
Hoodie日志文件命令
- show logfile records: 从日志文件读取记录
- show logfile metadata: 从日志文件读取提交元数据
Hoodie同步验证命令
- sync validate: 通过计数记录数量来验证同步
Kerberos认证命令
- kerberos kdestroy: 销毁Kerberos认证
- kerberos kinit: 执行Kerberos认证
标记命令
- marker delete: 删除标记
元数据命令
- metadata stats: 打印元数据的统计信息
- metadata list-files: 打印某个分区中所有文件的列表
- metadata list-partitions: 列出元数据中的所有分区
- metadata validate-files: 验证元数据中的所有分区的所有文件
- metadata delete: 删除元数据表
- metadata delete-record-index: 从元数据表中删除记录索引
- metadata create: 创建元数据表(如果不存在)
- metadata init: 从创建以来更新元数据表
- metadata set: 设置元数据表的选项
修复命令
- repair deduplicate: 去除包含重复项的分区路径,并生成修复文件以替换
- rename partition: 重命名分区。用法:rename partition --oldPartition --newPartition
- repair overwrite-hoodie-props: 用提供的文件覆盖hoodie.properties。风险操作,请小心进行!
- repair migrate-partition-meta: 将当前以文本格式存储的所有分区元文件迁移为基础文件格式。参见HoodieTableConfig#PARTITION_METAFILE_USE_DATA_FORMAT。
- repair addpartitionmeta: 如果不存在,则向表添加分区元数据
- repair deprecated partition: 修复已弃用的分区("default")。将数据从已弃用的分区写入__HIVE_DEFAULT_PARTITION__。
- repair show empty commit metadata: 显示失败的提交
- repair corrupted clean files: 修复损坏的清理文件
还原命令
- show restore: 显示还原的详细信息
- show restores: 列出所有还原时点
回滚命令
- show rollback: 显示回滚的详细信息
- commit rollback: 回滚提交
- show rollbacks: 列出所有回滚时点
保存点命令
- savepoint rollback: 保存一个提交的保存点
- savepoints show: 显示保存点
- savepoint create: 创建一个保存点
- savepoint delete: 删除保存点
Spark环境命令
- set: 将spark launcher环境设置为cli
- show env: 按键显示spark launcher环境
- show envs all: 显示所有spark launcher环境
统计命令
- stats filesizes: 显示文件大小的统计信息
- stats wa: 写入放大。上插入的记录数量与实际写入的记录数量之比
表命令
- table change-table-type: 将Hudi表类型更改为目标类型:COW或MOR。注意:在更改为COW之前,默认情况下该命令将执行所有待处理的压缩,并在需要时执行完整的压缩。
- table update-configs: 使用提供的文件更新表配置。
- table recover-configs: 从中途失败的更新/删除中恢复表配置。
- create: 如果不存在,则创建Hoodie表
- refresh, metadata refresh, commits refresh, cleans refresh, savepoints refresh: 刷新表元数据
- table delete-configs: 从表中删除提供的表配置。
- fetch table schema: 获取最新的表模式
- connect: 连接到Hoodie表
- desc: 描述Hoodie表的属性
临时视图命令
- temp_query, temp query: 对创建的临时视图进行查询
- temps_show, temps show: 显示所有视图名称
- temp_delete, temp delete: 删除视图名称
时间线命令
- metadata timeline show incomplete: 列出元数据表的活跃时间线中的所有未完成时刻
- metadata timeline show active: 列出元数据表的活跃时间线中的所有时刻
- timeline show incomplete: 列出活跃时间线中的所有未完成时刻
- timeline show active: 列出活跃时间线中的所有时刻
升级或降级命令
- downgrade table: 降级某个表
- upgrade table: 升级某个表
工具命令
- utils loadClass: 加载一个类
1.2. 常用命令
# 启动客户端
sh {HUDI_HOME}/hudi-cli/hudi-cli.sh
# 查看命令帮助
help
# 查看hudi版本
version
# 连接到Hoodie表
connect --path hdfs://cmccprdhadoop/apps/hive/warehouse/hudi_test.db/hudi_rbs_rbscmfprd_cmf_clm_claim_headers_cdc_test
# 查看表的描述信息
desc
fetch table schema
# 查看提交信息,在比较少时可以使用,默认按照时间倒序排列
commits show
# 对提交信息排序
commits show --sortBy "Total Bytes Written" --desc true --limit 10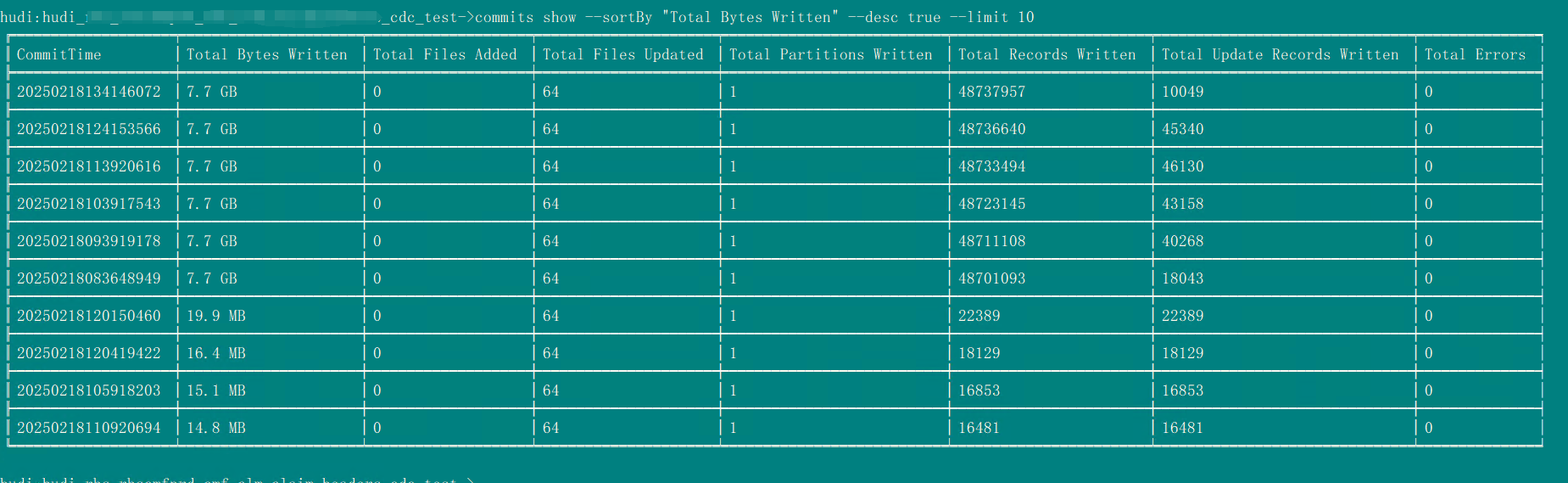
# 文件系统视图,分区由文件组组成,文件组包含按时间片提交的文件切片组成
show fsview all
show fsview latest --partitionPath "2018/08/31"
# 文件统计信息
stats filesizes --partitionPath 2016/09/01 --sortBy "95th" --desc true --limit 10
# 写入耗时
stats wa
# 查看待处理的压缩
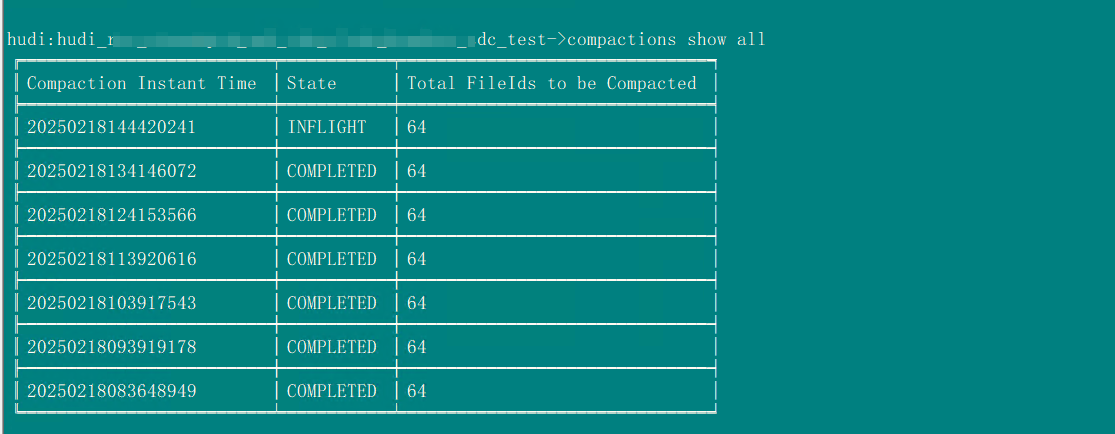
compactions show all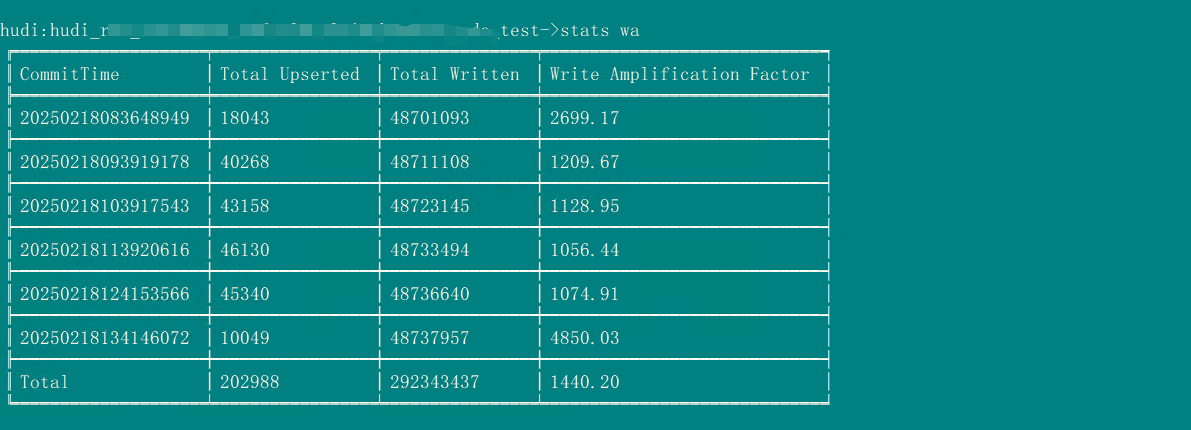
# 查看写入分区信息 20250218103917543 来自 stats wa 命令结果
commit showpartitions --commit 20250218103917543 --sortBy "Total Bytes Written" --desc true --limit 10
# 写入到文件级别信息
commit showfiles --commit 20250218103917543 --sortBy "Partition Path"1.2.1. 重复文件修复命令
# 启动客户端
sh {HUDI_HOME}/hudi-cli/hudi-cli.sh
# 连接到Hoodie表
connect --path hdfs://cmccprdhadoop/apps/hive/warehouse/hudi_test.db/hudi_rbs_rbscmfprd_cmf_clm_claim_headers_cdc_test
# 修复表数据
# 非分区表
repair deduplicate --repairedOutputPath hdfs://cmccprdhadoop/apps/hive/warehouse/hudi_test.db/hudi_rbs_rbscmfprd_cmf_clm_claim_headers_cdc_test/ --dedupeType upsert_type --sparkMaster yarn --sparkMemory 8G
# 分区表 直接删除重复项
repair deduplicate --duplicatedPartitionPath cmf_clm_claim_headers --repairedOutputPath hdfs://cmccprdhadoop/apps/hive/warehouse/hudi_test.db/hudi_rbs_rbscmfprd_cmf_clm_claim_headers_cdc_test/cmf_clm_claim_headers --dedupeType upsert_type --sparkMaster yarn --sparkMemory 8G
# 分区表 删除重复项并将结果存储到另外的分区
repair deduplicate --duplicatedPartitionPath cmf_clm_claim_headers --repairedOutputPath hdfs://cmccprdhadoop/apps/hive/warehouse/hudi_test.db/hudi_rbs_rbscmfprd_cmf_clm_claim_headers_cdc_test/cmf_clm_claim_headers_bak --dedupeType upsert_type --sparkMaster yarn --sparkMemory 8G
# 确定修复后分区没有问题之后,删除旧分区,替换为新分区
# 删除之前的分区
hadoop fs -rm -r hdfs://cmccprdhadoop/apps/hive/warehouse/hudi_test.db/hudi_rbs_rbscmfprd_cmf_clm_claim_headers_cdc_test/cmf_clm_claim_headers
# 刷新元数据信息
# 重命名为之前的分区: rename partition --oldPartition --newPartition
rename partition cmf_clm_claim_headers_bak cmf_clm_claim_headers
# 查看分区
metadata list-partitions

















 458
458

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











