



BeanFactory实现
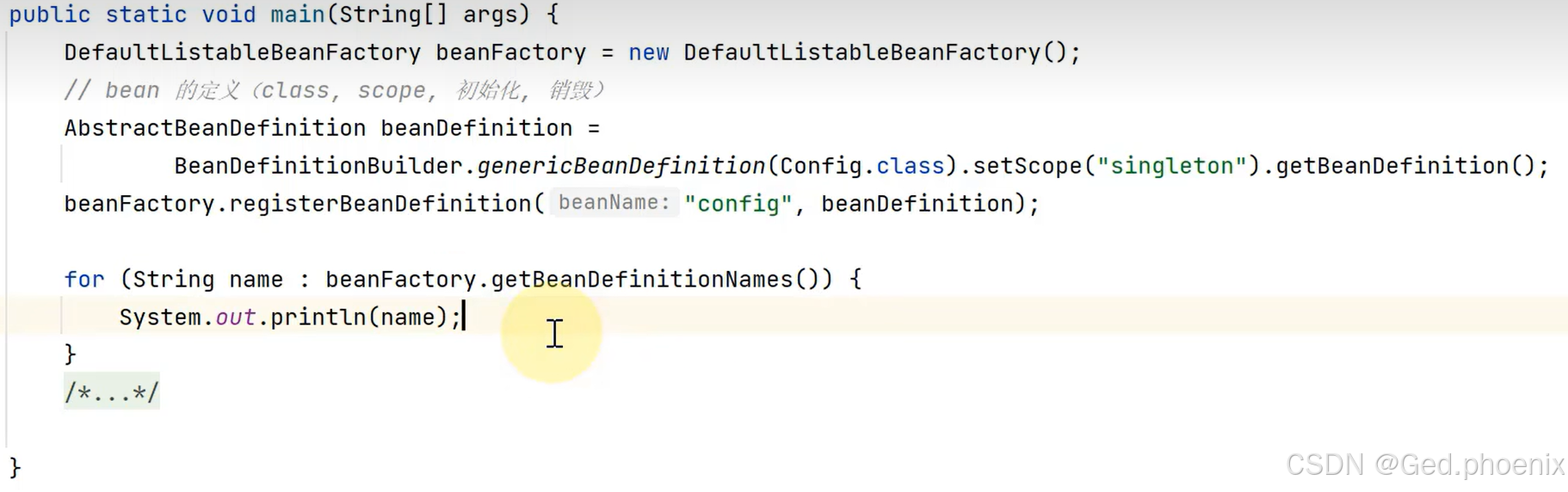
我们先创建一个BeanFactory的实现类, 然后去给这个beanFactory生成一个bean的定义器,声明bean的类型,单例还是多例模式,初始化方法,销毁方法等等,方便让beanFactory通过Bean定义器去生成bean,此时容器内是没有任何bean的。
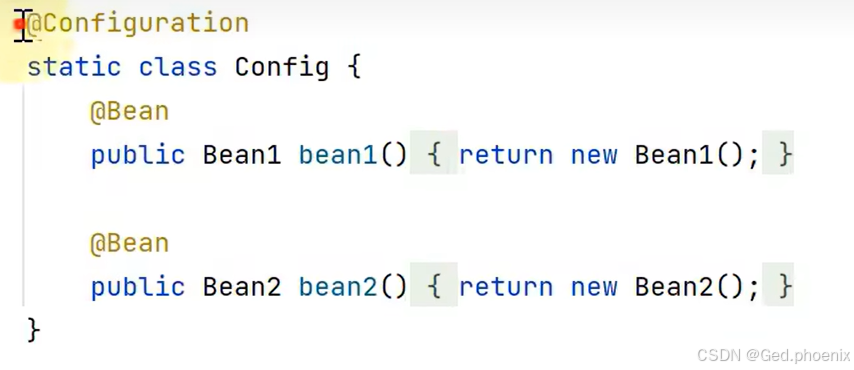
我们想要通过编程的方式想要来加入上述bean,需要给beanFactory注册了一个bean的定义器。
但是在最后只加入了config一个bean,并没有把我们想要的bean给加载到容器当中,也就是说注@Configuration,@Bean注解并没有生效,那这是为什么呢?
这是因为我们beanFactory并不负责注解解析的功能,要想实现注解的解析,我们需要给BeanFactory添加后处理器,让后处理器来解析注解,而其中负责注解解析的后处理器就是internalConfigurationAnnotationProcessor后处理器,并且不光要添加,还要去挨个执行我们的BeanFactory后处理器才可以。运行后,就能实现我们下述的效果。
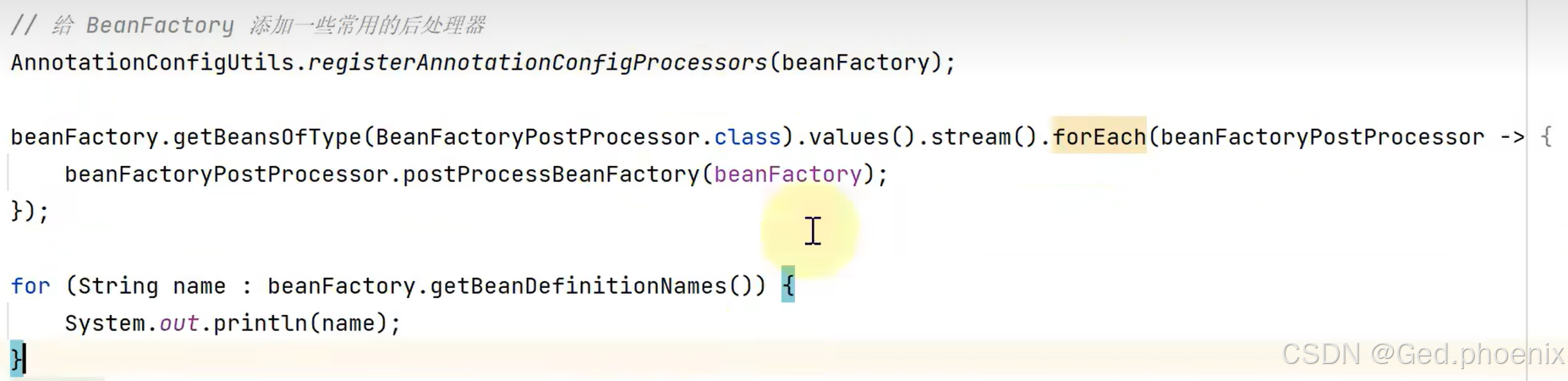
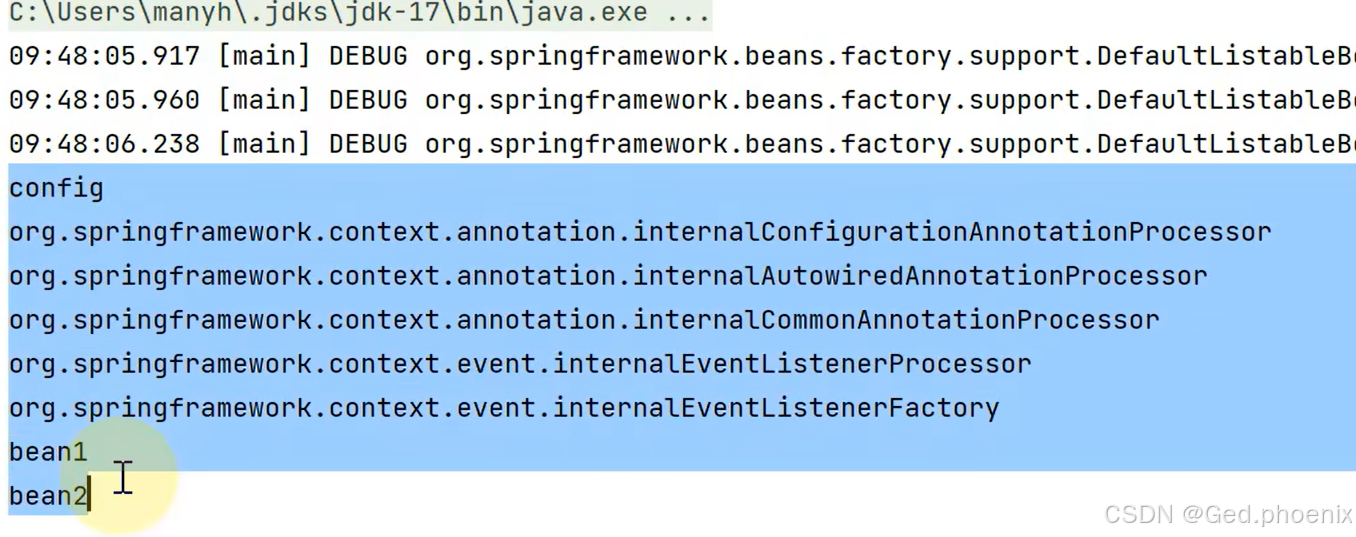
所以说我们的beanFactory功能并不是特别的齐全,还需要后处理器来做功能上的补充和扩展。
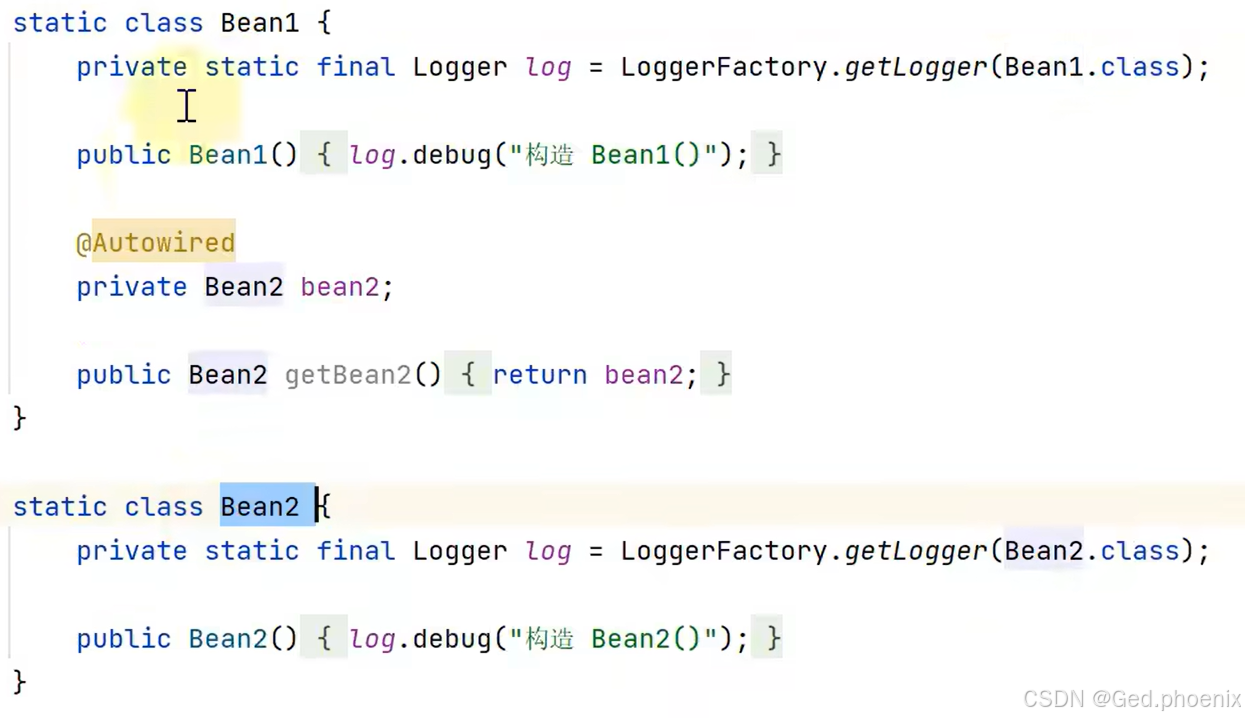
既然已经把对象加入到容器当中了,接下来我们就需要使用了,我们调用getBean方法去获取Bean
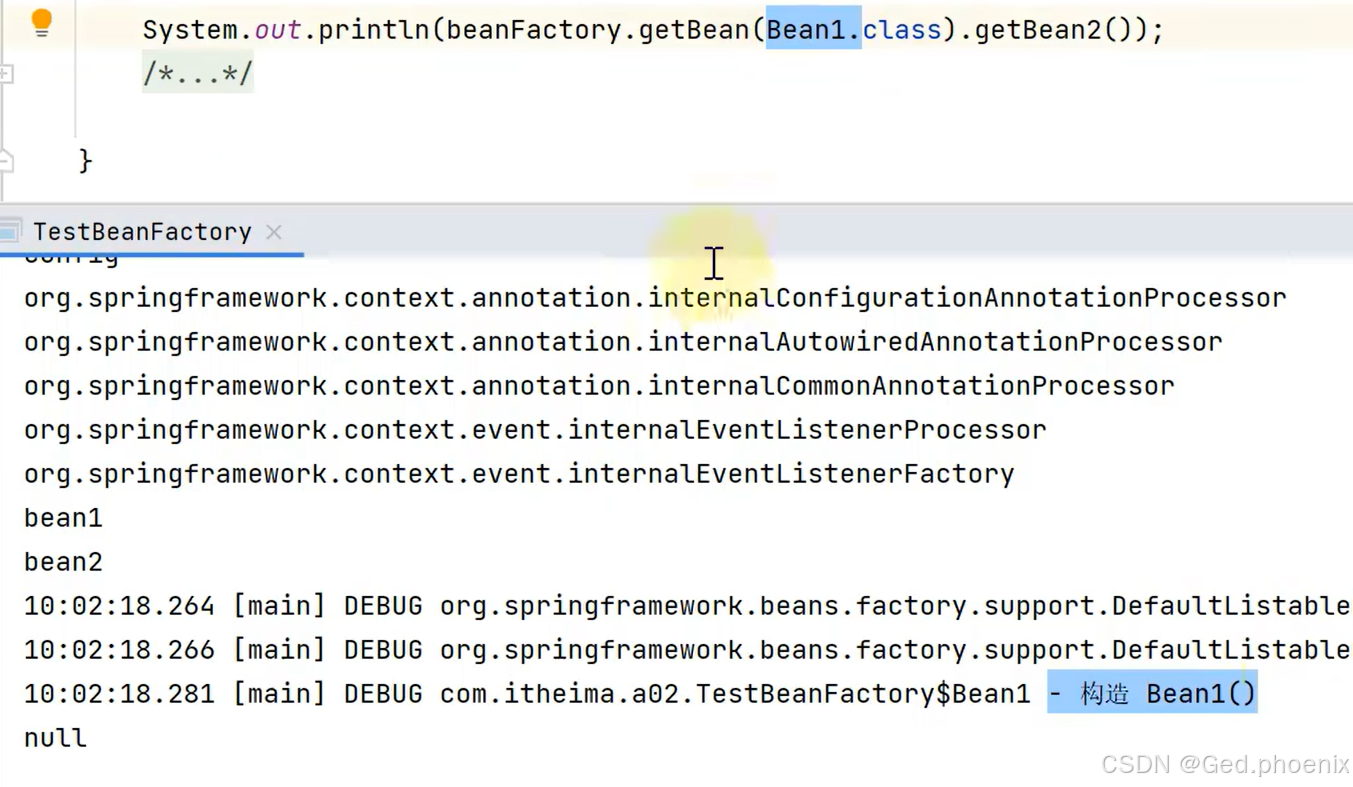
并获取Bean2,但是发现了问题,并且没有获取到Bean2,说明@Autowired并没有生效。
这是因为我们还缺少Bean的后处理器,来解析像@Autowired这样的注解。
那么Bean的后处理器和BeanFactory的后处理器有什么不一样呢?
Bean的后处理器是针对于Bean的生命周期的各个阶段来提供扩展功能,也就是针对Bean的创建,依赖注入,初始化这些阶段。
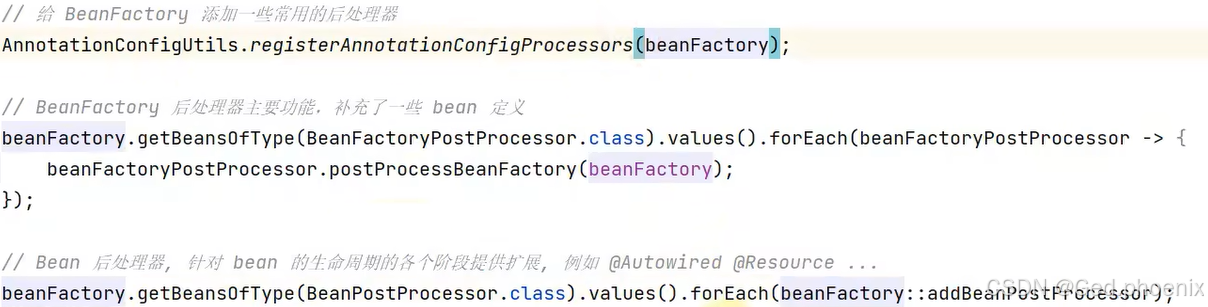
和刚才一样,再获取Bean的后处理器,依次去进行启动,其实也就是上面图中的这两个后处理器。一个是@Autowired的,一个是@Resource的。

那又有一个疑问了,为什么添加了两次处理器?
是这样子,第一次添加只是把后处理器加入到BeanFactory而此时并没有建立真正的联系,而后面的那次添加才是真正的去建立BeanFactory和后处理器的联系。
这里又有一个问题了,是Bean工厂创建完成后就立刻把所有单例Bean都创建好还是说等使用到哪个Bean再去创建呢?
其实是当我们使用的时候才会去进行实例化,在一开始并没有创建所有的Bean,只是去保存了一份Bean的描述信息。(注册到BeanFactory当中,根据我的理解,这其实就是默认打开了Spring的懒汉模式)
要想提前实例化所有的Bean对象,只需要执行下述代码。
![]()
总结
BeanFactory并不会主动的去添加并调用BeanFactory和Bean的后处理器,也不会主动的实例化单例对象,也不会解析beanFactory,当然也不会解析¥{},#{}。而ApplicationContext已经主动的将这些功能添加了,所以说对于开发者来说,BeanFactory并不是那么友好,更优的选择是ApplicationContext。

















 245
245

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









