




文章目录
钢铁缺陷检测中的YOLOv11实现
概述
本项目利用YOLOv11模型对钢铁缺陷进行检测,使用了两个数据集。项目的目标是以高精度检测和分类钢铁表面缺陷。为了提高模型的性能,数据集进行了预处理和增强,以增加数据的多样性和质量。所有的训练与评估工作都在Google Colab上完成。

数据集
- NEU数据集
- 注释:原始数据集提供了缺陷的标注信息。
- 数据增强:对数据集进行了增强,旨在提高数据集的多样性和模型的泛化能力。
NEU数据集的增强版本通过多种数据增强技术扩展了数据集的大小和多样性。使用此增强数据集进行训练时,YOLOv11模型能够更好地学习到钢铁表面缺陷的各种变异形式,从而提升检测精度。
- Severstal数据集
- 注释:数据集的2,000张图片进行了手动标注。
- 数据增强:标注完成后,通过增强手段进一步增加数据集的大小和变异性。
Severstal数据集相较于NEU数据集有更大的复杂度,缺陷种类繁多,且标注过程中可能出现一定程度的人为误差,因此在训练过程中需要更加复杂的处理和调整。

使用的工具
- Google Colab:本项目使用Google Colab进行YOLOv11模型的训练与评估,借助其强大的计算资源,如GPU,进行大规模的数据处理。
- Roboflow:用于数据集的准备和增强。Roboflow提供了一些自动化工具,帮助快速进行数据集标注和预处理。
- Ultralytics:提供了YOLOv11的实现框架,这一框架基于YOLO(You Only Look Once)模型,专注于目标检测,并具备高度优化的性能。
- YOLOv11框架:利用YOLOv11这一最先进的物体检测架构进行钢铁缺陷检测。
- Python库:包括TensorFlow、Matplotlib、NumPy、OpenCV等,这些库在数据处理、可视化以及模型训练中起到了关键作用。
数据增强
为了提高数据集的多样性和模型的泛化能力,本项目对NE和S数据集进行了不同方式的数据增强。使用具进行了如下增强操作:
- 图像大小调整:将图像统一调整为640x640像素,以适应YOLOv11模型的输入需求。
- 旋转:对图像进行了±5°的旋转,模拟不同角度下钢铁缺陷的表现。
- 水平与垂直翻转:随机对图像进行水平和垂直翻转,增加数据的多样性。
- 亮度调整:随机调整图像的亮度,范围为±5%,以模拟不同光照条件下的检测。
- 剪切变换:进行了±5%的剪切变换,模拟不同的视角和倾斜。
这些增强操作能够有效扩展数据集,使得模型在训练时能更好地学习到缺陷的多样性,提升了模型在实际应用中的表现,尤其是在面对未知数据时的泛化能力。
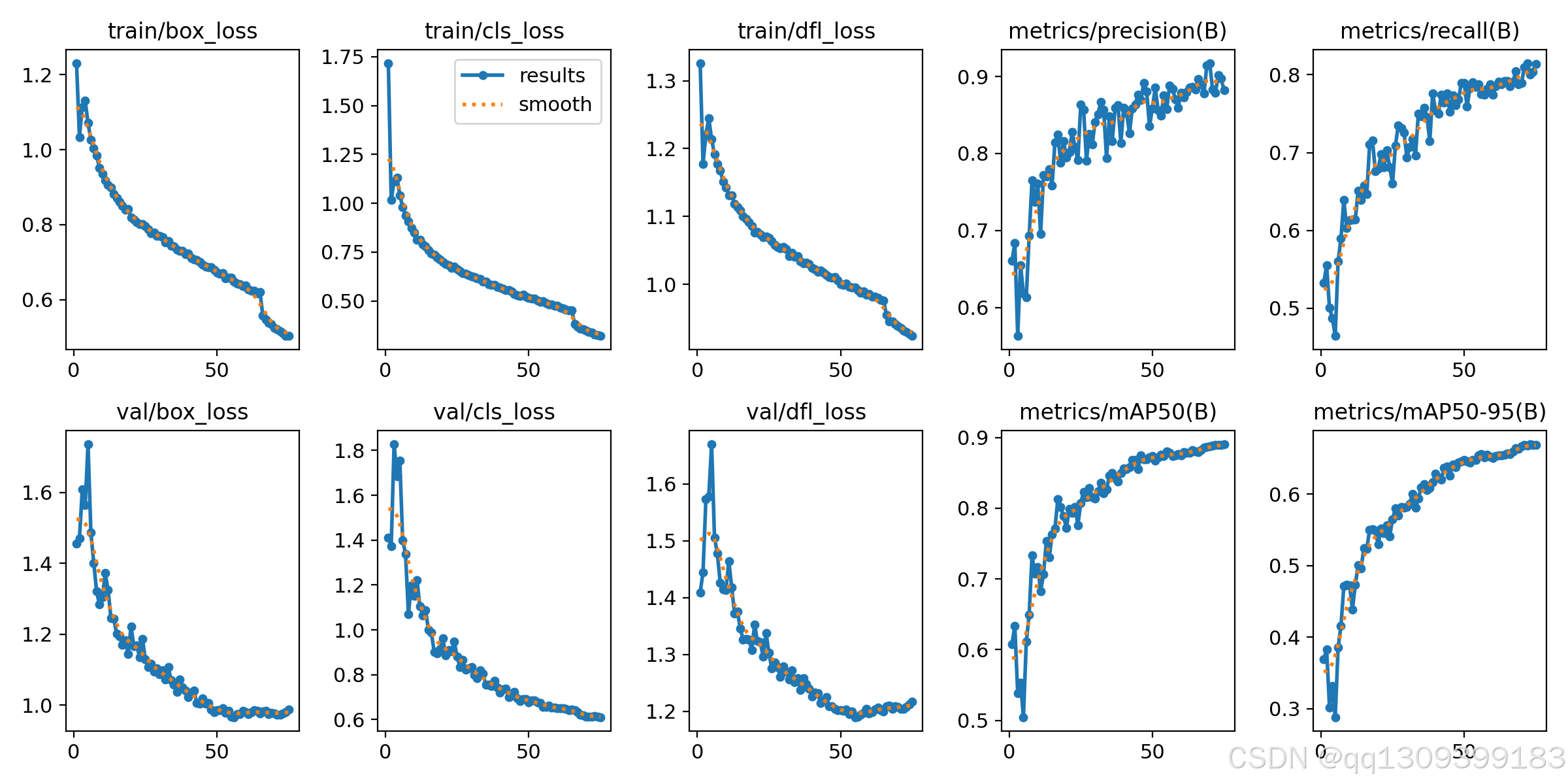
实验结果
在使用NEU和Severstal数据集进行训练与评估后,得到了以下检测结果:
| 数据集 | mAP@50 | mAP@50-95 |
|---|---|---|
| 数据集1 | 88.9 | 66.9 |
| 数据集1 | 59.5 | 41.9 |
- N数据集:该数据集的检测精度较高,mAP@50为88.9%,mAP@50-95为66.9%。较高的准确度主要得益于数据集的大小适中且缺陷模式相对简单,模型较容易学习到这些缺陷特征。
- S数据集:与NEU数据集相比,数据集的表现较低,mAP@50为59.5%,mAP@50-95为41.9%。这是因为数据集具有更大的数据量和更多样的缺陷模式,增加了模型训练的难度。此外,由于该数据集的标注是人工完成的,可能存在一定的不一致性和误差,这也影响了模型的表现。
分析
-
NE数据集:
- 该数据集的较高表现可以归因于两个因素:首先,NE数据集包含的缺陷种类较为简单且相对统一,使得YOLOv11模型能够较容易地识别和分类;其次,数据集的规模适中,能够提供足够的样本量进行有效的训练。
- 由于缺陷种类较少且图像质量较高,模型训练过程中的过拟合风险较小,因此可以获得较好的泛化能力。
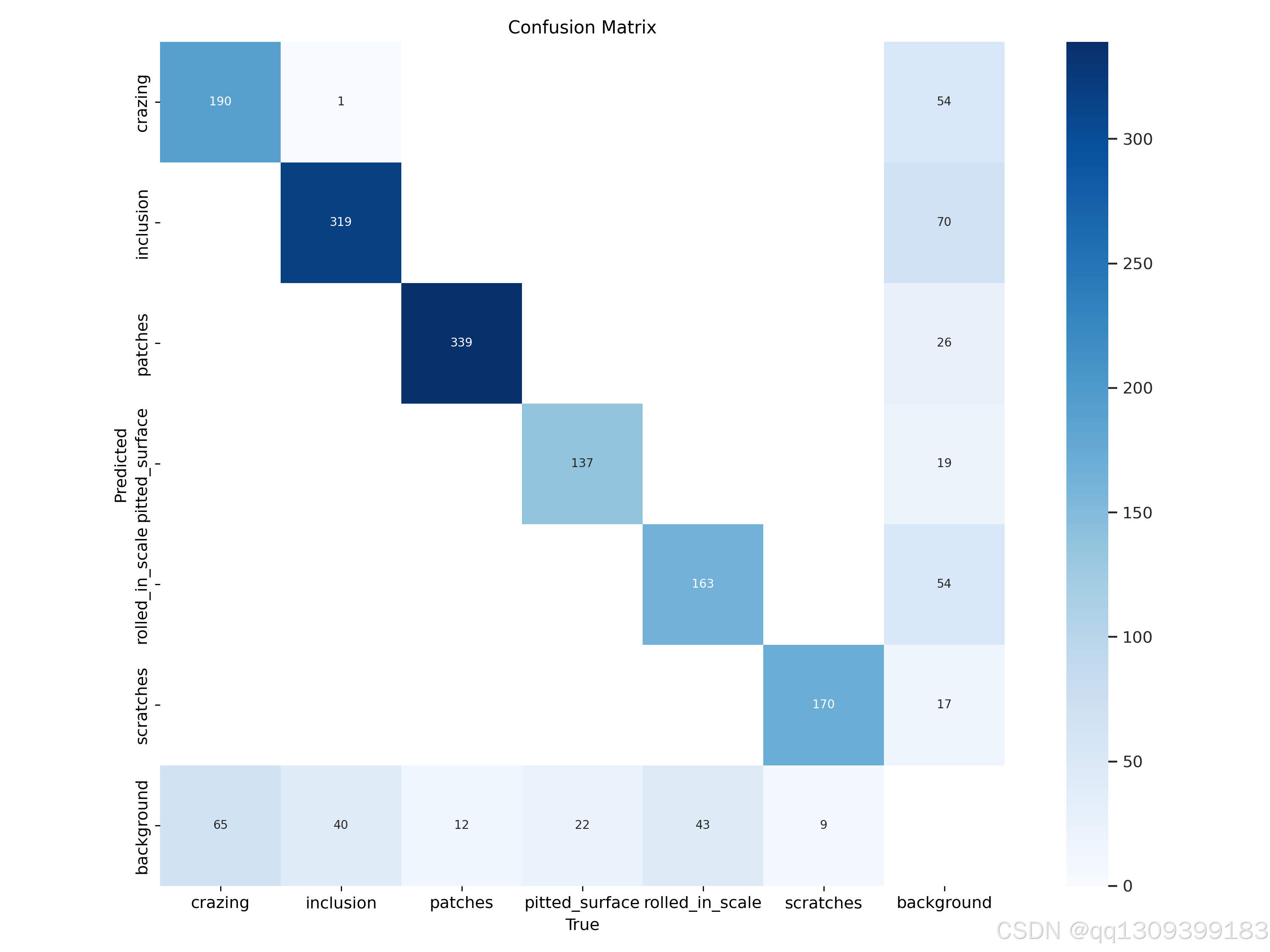
-
数据集:
- Severstal数据集的表现较低主要是由于其更大的数据集规模和更复杂的缺陷模式。该数据集包含的钢铁表面缺陷种类更加多样,包括裂纹、凹坑、划痕等复杂的缺陷,这使得模型在训练时需要处理更多的变异性。
- 另外,人工标注可能存在一些不一致性或误差,这可能对训练过程产生负面影响。特别是对于一些细微的缺陷,标注错误可能导致模型在检测时出现较大偏差。
- 数据集的增大和复杂度的提升,虽然为模型提供了更多的训练样本,但也增加了模型训练的难度,因此其性能表现相对较低。
结论

本项目展示了YOLOv11在钢铁缺陷检测中的应用,尤其是数据集上的表现。通过数据增强技术,模型在这两个数据集上的性能得到了提升。NEU数据集由于其较为简单的缺陷模式和适中的数据规模,使得YOLOv11能够取得较高的检测精度;而Severstal数据集由于缺陷种类多样且人工标注可能存在误差,导致其检测精度相对较低。
未来的研究可以尝试进一步优化数据集的质量,减少标注错误,或采用其他模型架构,以提高钢铁缺陷检测的整体精度。此外,可以通过引入更多的缺陷类型和不同的环境条件,来提升模型的鲁棒性和泛化能力。


















 1036
1036

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









