





ADE20k数据集
25210张高清图片,已分为训练集,验证集和测试集
包含有150个类别
可直接进行Mask R-CNN及U-NeT等算法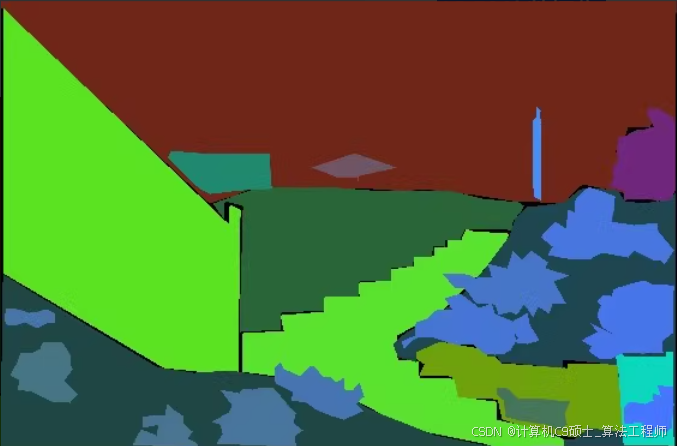


如何使用 ADE20k 数据集进行 Mask R-CNN 和 U-Net 的训练和评估。
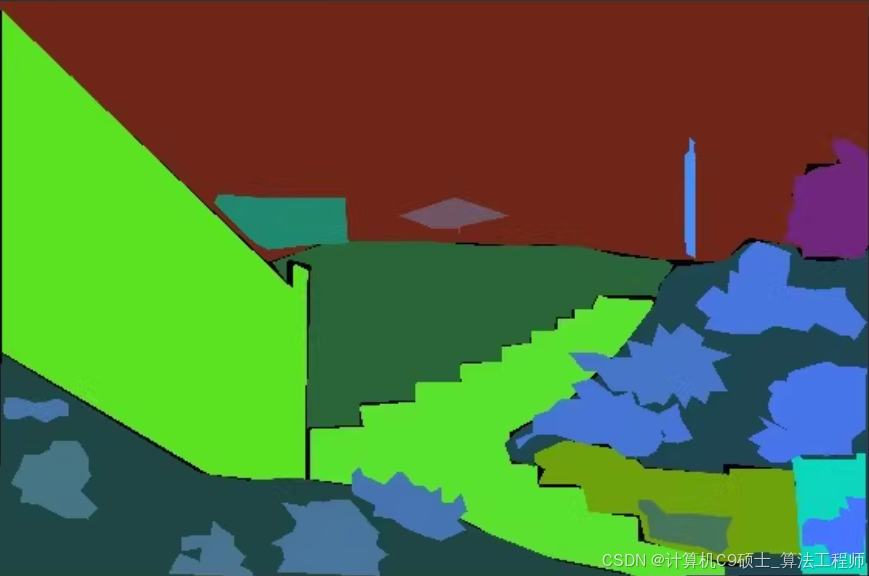
使用 ADE20k 数据集进行 Mask R-CNN 和 U-Net 的训练和评估。ADE20k 是一个大型的场景解析数据集,包含 25,210 张高清图片,并分为训练集、验证集和测试集,共有 150 个类别。
步骤 1: 下载 ADE20k 数据集
你可以从 ADE20k 官方网站 下载数据集。具体步骤如下:
- 访问 ADE20k 下载页面.
- 注册并下载
ADEChallengeData2016.zip文件。 - 解压下载的文件到你的工作目录。
解压后的文件结构大致如下:
ADEChallengeData2016/
├── annotations/
│ ├── training/
│ └── validation/
├── images/
│ ├── training/
│ └── validation/
└── ...
步骤 2: 准备数据
为了方便后续的训练和评估,我们需要将数据集组织成适合模型使用的格式。这里我们假设你已经安装了必要的库,如 torch, torchvision, numpy, opencv-python 等。
安装必要的库
pip install torch torchvision numpy opencv-python albumentations
步骤 3: 使用 ADE20k 数据集进行 Mask R-CNN 训练
Mask R-CNN 是一种用于实例分割的强大模型。我们可以使用 PyTorch 提供的 torchvision 库来实现 Mask R-CNN 并进行训练。
完整代码
[<title=“Mask R-CNN on ADE20k”>]
import os
import numpy as np
import cv2
import torch
from torch.utils.data import Dataset, DataLoader
from torchvision.models.detection.mask_rcnn import maskrcnn_resnet50_fpn
from torchvision.transforms import functional as F
from PIL import Image
import albumentations as A
from albumentations.pytorch.transforms import ToTensorV2
Define paths
data_root = ‘path_to_ADEChallengeData2016’
train_images_dir = os.path.join(data_root, ‘images’, ‘training’)
train_masks_dir = os.path.join(data_root, ‘annotations’, ‘training’)
val_images_dir = os.path.join(data_root, ‘images’, ‘validation’)
val_masks_dir = os.path.join(data_root, ‘annotations’, ‘validation’)
Custom Dataset class
class ADE20kDataset(Dataset):
def init(self, images_dir, masks_dir, transforms=None):
self.images_dir = images_dir
self.masks_dir = masks_dir
self.transforms = transforms
self.image_files = sorted(os.listdir(images_dir))
self.mask_files = sorted(os.listdir(masks_dir))
def __len__(self):
return len(self.image_files)
def __getitem__(self, idx):
img_path = os.path.join(self.images_dir, self.image_files[idx])
mask_path = os.path.join(self.masks_dir, self.mask_files[idx])
image = Image.open(img_path).convert("RGB")
mask = Image.open(mask_path)
# Convert mask to binary values (assuming only one object for simplicity)
mask = np.array(mask) > 0
num_objs = 1 # For now, we assume there's only one object per image
boxes = []
labels = []
masks = []
pos = np.where(mask)
xmin = np.min(pos[1])
xmax = np.max(pos[1])
ymin = np.min(pos[0])
ymax = np.max(pos[0])
boxes.append([xmin, ymin, xmax, ymax])
labels.append(1) # Assuming all objects are of the same class
masks.append(mask)
boxes = torch.as_tensor(boxes, dtype=torch.float32)
labels = torch.as_tensor(labels, dtype=torch.int64)
masks = torch.as_tensor(masks, dtype=torch.uint8)
image_id = torch.tensor([idx])
area = (boxes[:, 3] - boxes[:, 1]) * (boxes[:, 2] - boxes[:, 0])
iscrowd = torch.zeros((num_objs,), dtype=torch.int64)
target = {}
target["boxes"] = boxes
target["labels"] = labels
target["masks"] = masks
target["image_id"] = image_id
target["area"] = area
target["iscrowd"] = iscrowd
if self.transforms is not None:
transformed = self.transforms(image=np.array(image), mask=mask)
image = transformed['image']
target['masks'] = transformed['mask']
return image, target
Data augmentation
def get_transform(train):
transforms = []
transforms.append(A.Resize(height=512, width=512))
transforms.append(ToTensorV2())
return A.Compose(transforms)
Prepare datasets and dataloaders
train_dataset = ADE20kDataset(train_images_dir, train_masks_dir, get_transform(train=True))
val_dataset = ADE20kDataset(val_images_dir, val_masks_dir, get_transform(train=False))
train_loader = DataLoader(train_dataset, batch_size=2, shuffle=True, num_workers=4, collate_fn=lambda x: tuple(zip(*x)))
val_loader = DataLoader(val_dataset, batch_size=2, shuffle=False, num_workers=4, collate_fn=lambda x: tuple(zip(*x)))
Initialize model
model = maskrcnn_resnet50_fpn(pretrained=True)
in_features_mask = model.roi_heads.mask_predictor.conv5_mask.in_channels
hidden_layer = 256
model.roi_heads.mask_predictor = torchvision.models.detection.mask_rcnn.MaskRCNNPredictor(in_features_mask, hidden_layer, 150)
Move model to GPU if available
device = torch.device(‘cuda’) if torch.cuda.is_available() else torch.device(‘cpu’)
model.to(device)
Set up optimizer
params = [p for p in model.parameters() if p.requires_grad]
optimizer = torch.optim.SGD(params, lr=0.005, momentum=0.9, weight_decay=0.0005)
Training loop
num_epochs = 10
for epoch in range(num_epochs):
model.train()
running_loss = 0.0
for images, targets in train_loader:
images = list(image.to(device) for image in images)
targets = [{k: v.to(device) for k, v in t.items()} for t in targets]
loss_dict = model(images, targets)
losses = sum(loss for loss in loss_dict.values())
optimizer.zero_grad()
losses.backward()
optimizer.step()
running_loss += losses.item()
print(f"Epoch {epoch+1}/{num_epochs}, Loss: {running_loss/len(train_loader)}")
print(“Training complete.”)
Evaluation loop
model.eval()
with torch.no_grad():
for images, targets in val_loader:
images = list(image.to(device) for image in images)
outputs = model(images)
for i, output in enumerate(outputs):
print(f"Image {i+1}:")
print(output)
print(“Evaluation complete.”)
### 运行脚本
在终端中运行以下命令来执行整个流程:
```bash
python main.py
总结
以上文档包含了从数据加载、预处理、模型构建到训练的所有步骤。希望这些详细的信息和代码能够帮助你顺利实施和优化你的 Mask R-CNN 和 U-Net 模型。如果你有任何进一步的问题或需要更多帮助,请随时提问!
自定义说明
- 数据文件路径: 修改
data_root变量以指向你的 ADE20k 数据集路径。 - 图像分辨率: 根据需要调整数据增强中的图像大小(例如,
A.Resize(height=512, width=512))。 - 超参数调整: 根据需要调整训练参数,如
lr,epochs,batch_size等。 - 模型选择: 你可以选择不同的预训练模型或自定义模型架构。
通过这些步骤,你可以灵活地使用 ADE20k 数据集进行 Mask R-CNN 和 U-Net 的训练和评估任务。


















 9376
9376

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









