




 本文探讨了如何使用Elasticsearch和Python实现对TMDB数据集的高效搜索,通过重构索引和利用QueryDSL来提高搜索质量。文章深入解析了TF-IDF、多字段搜索和排名函数的构建,以及如何通过用户反馈调整相关性函数,最终设计出以相关性为核心的应用。
本文探讨了如何使用Elasticsearch和Python实现对TMDB数据集的高效搜索,通过重构索引和利用QueryDSL来提高搜索质量。文章深入解析了TF-IDF、多字段搜索和排名函数的构建,以及如何通过用户反馈调整相关性函数,最终设计出以相关性为核心的应用。
三、调试我们的第一个相关性问题
使用Elasticsearch
TMDB数据集在https://github.com/o19s/relevant-search-book中tmdb.json
python实现函数
reindex函数,重建Elasticsearch索引,并放入其中。
Query DSL领域特定查询语言
TF-IDF
四、驾驭token
文本分析所生成的token不仅代表查询的特征,也代表文档的特征
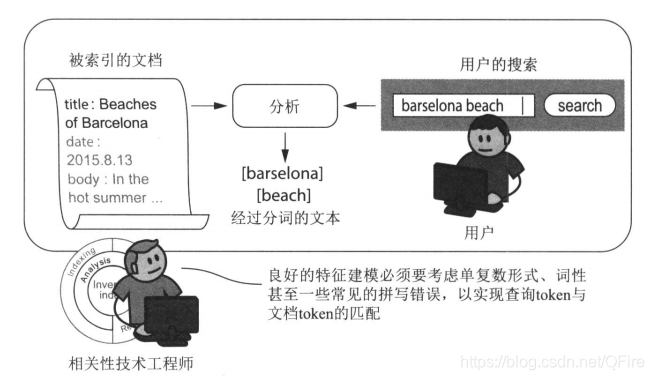
带着意图和语义来进行分析,会极大地提升搜索的相关性。
五、多字段搜索基础
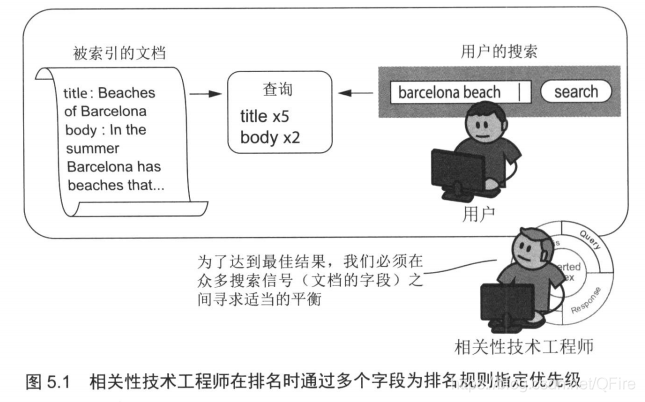
排名函数
对于多个字段的评价--即多个信号---需要被合并成一个总的相关性评价才行,这样才能平衡所有对用户或业务而言的重要因素。这就是排名函数的目标。
源数据
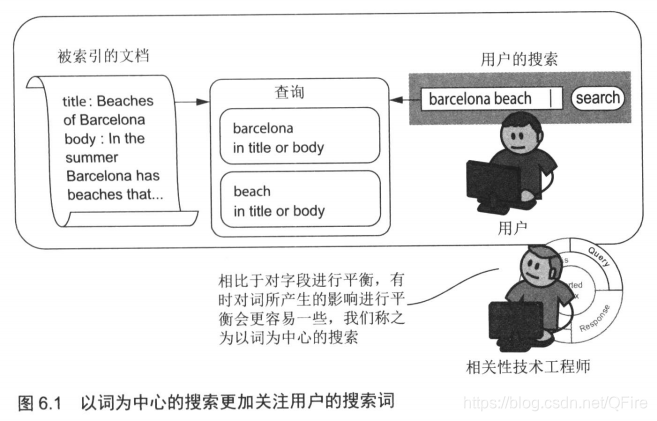
六、以词为中心的搜索
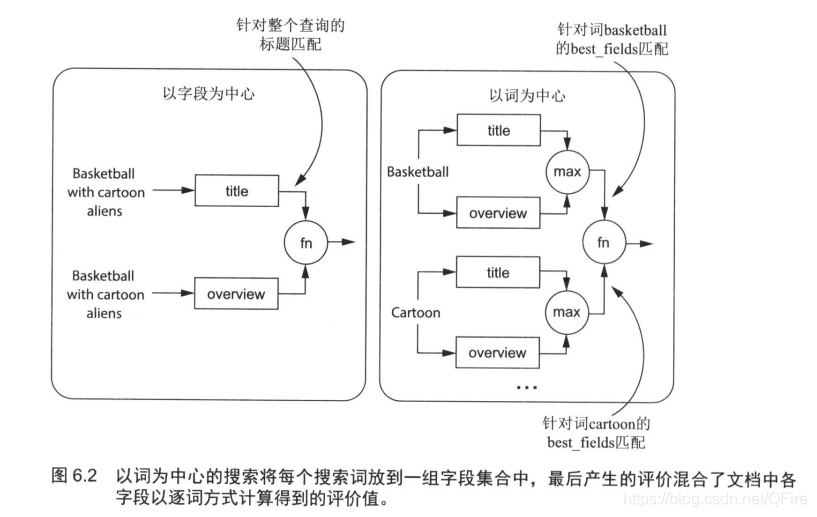
七、调整相关性函数
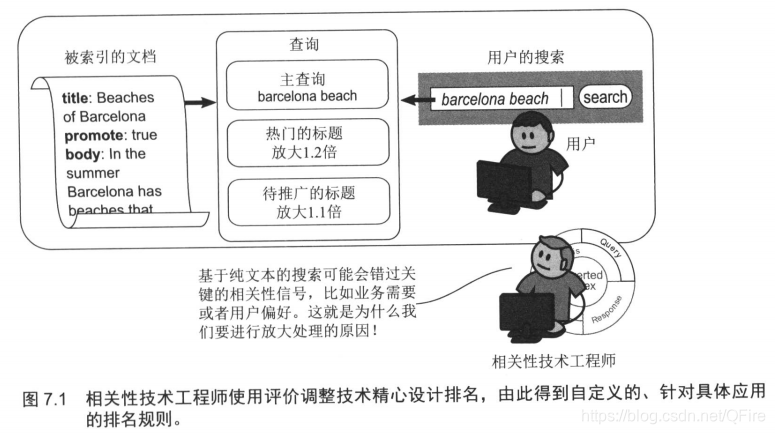
构造排名函数
八、提供相关性反馈
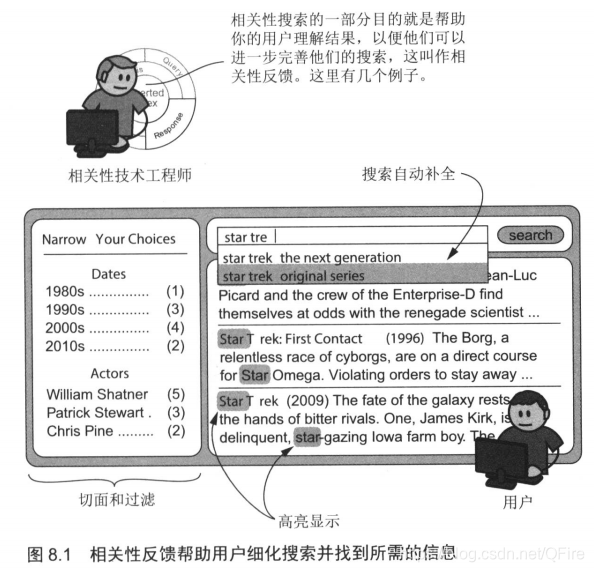
引导用户搜索

九、设计以相关性为核心的搜索应用

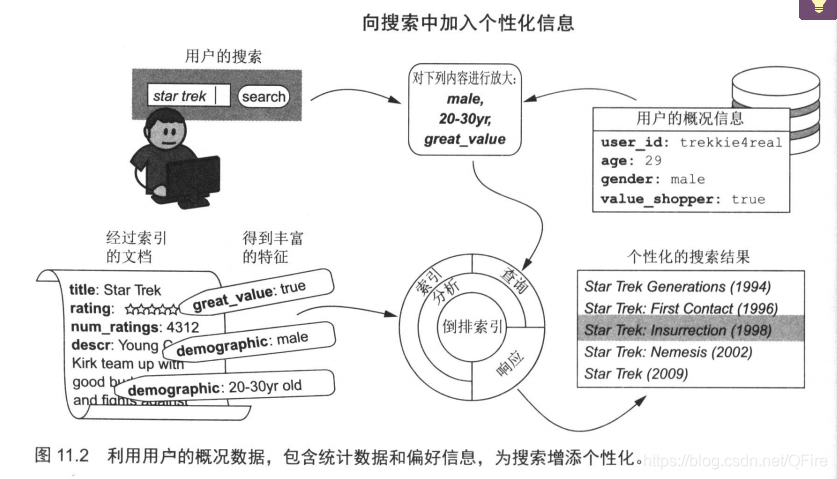
十一、语义和个性化搜索
引入推荐的概念。
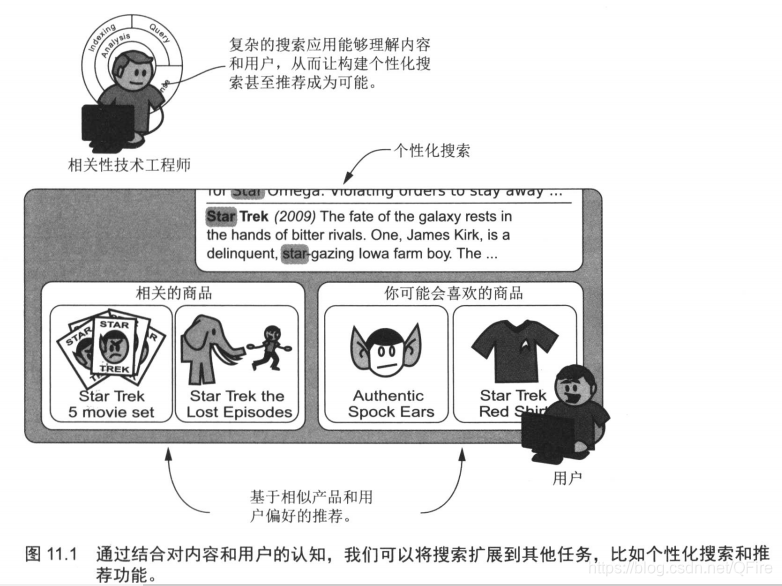
主要的不同之处在于,这里并不是只从文档中提取信息,我们还会将用户本身看作一种新的信息来源。


















 535
535

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









