 糗事百科爬虫实战
糗事百科爬虫实战





 本文介绍了一个简单的糗事百科爬虫实现过程,包括确定URL、分析页面结构、构造正则表达式等步骤,最终实现了自动抓取热门段子的发布者、内容及点赞数。
本文介绍了一个简单的糗事百科爬虫实现过程,包括确定URL、分析页面结构、构造正则表达式等步骤,最终实现了自动抓取热门段子的发布者、内容及点赞数。
糗事百科是不需要登录的,所以也没必要用到Cookie,另外,也不需要传数据到后台,所以也不用data.
好,现在我们尝试抓取一下糗事百科的热门段子吧.
我们需要爬取每个段子的发布者,内容和点赞数
1.确定URL并抓取页面代码
首先我们确定好页面的URL是 http://www.qiushibaike.com/hot/page/1
我们先来尝试获取一下糗事百科的网页,看能不能成功获取.
from urllib import request
import re
if __name__ == '__main__':
# 糗事百科的网址
url = "https://www.qiushibaike.com/hot/page/1/"
# headers
headers={}
headers["User-Agent"] = "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36"
req = request.Request(url, headers=headers)
response = request.urlopen(req)
# 获取html代码
html = response.read().decode("utf-8")
print(html)从获取结果来看,可以看出我们已经成功获取了糗事百科热门页面的html代码了.
2, 分析页面html代码
打开网页的调试模式,看看我们所需要的数据是在哪些div里.
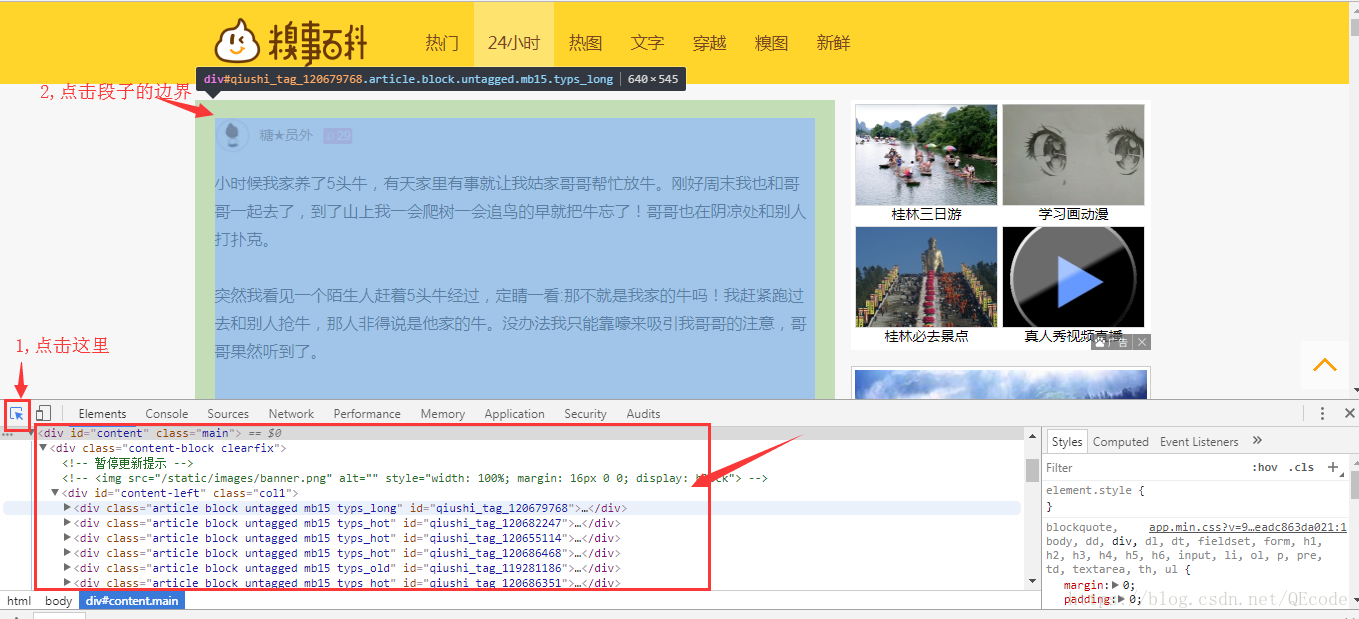
打开里面的一个div可以分析出每一个段子都是div class=”article block untagged mb15″ id=”…”>…/div>”包裹的内容,接下来再分析我们所要获取的发布人,内容和点赞数在哪个标签里:
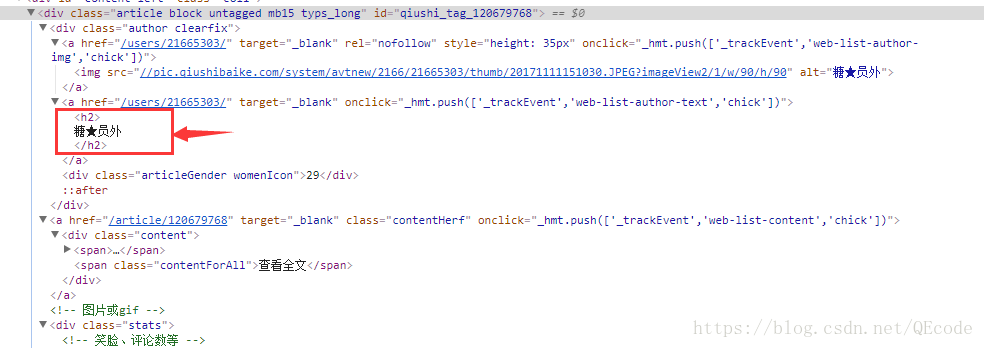
我们可以看见发布人是在h2标签里的.
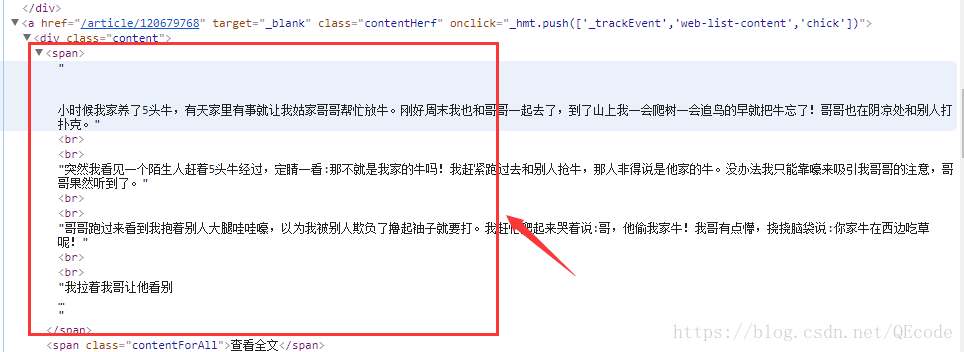
我们可以看见内容是在span标签里的.
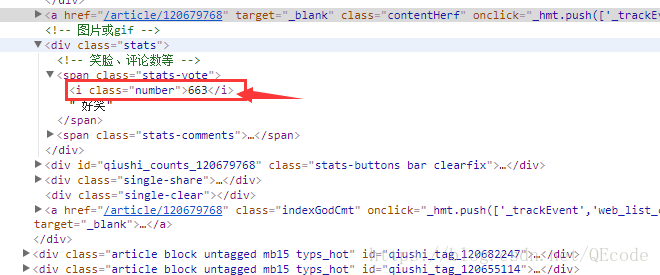
我们可以看见点赞数是在i标签里的.
3, 根据我们要获取的信息构造正则表达式
在了解了网页的html标签后,现在来构造一个正则表达式来获取我们所需要的信息
正则表达式如下:
<div.*?author.*?<a.*?<h2>(.*?)</h2>.*?<div.*?<span>(.*?)</span>.*?<div.*?<span.*?<i.*?>(.*?)</i>现在正则表达式在这里稍作说明
1).? 是一个固定的搭配,.和代表可以匹配任意无限多个字符,加上?表示使用非贪婪模式进行匹配,也就是我们会尽可能短地做匹配,在这里我们用了省略一些不必要的标签,免得正则表达式太长。
2)(.?)代表一个分组,在这个正则表达式中我们匹配了3分组,每一个分组的内容就是我们所需要的信息,在后面的遍历item中,item[0]就代表第一个(.?)所指代的内容,item[1]就代表第二个(.*?)所指代的内容,以此类推。
3)re.S 标志代表在匹配时为点任意匹配模式,点 . 也可以代表换行符。
这样我们就获取了发布人,发布时间,发布内容以及点赞数。
4, 利用正则表达式获取我们所需要的信息
from urllib import request
import re
if __name__ == '__main__':
# 糗事百科的网址
url = "https://www.qiushibaike.com/hot/page/1/"
# headers
headers={}
headers["User-Agent"] = "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36"
req = request.Request(url, headers=headers)
response = request.urlopen(req)
# 获取html代码
html = response.read().decode("utf-8")
构造正则表达式
zheng = "<div.*?author.*?<a.*?<h2>(.*?)</h2>.*?<div.*?<span>(.*?)</span>.*?<div.*?<span.*?<i.*?>(.*?)</i>"
pattern = re.compile(zheng, re.S)
items = re.findall(pattern, html)
for item in items:
print(item[0], " ", item[1], " ", item[2])
得到的结果如下:
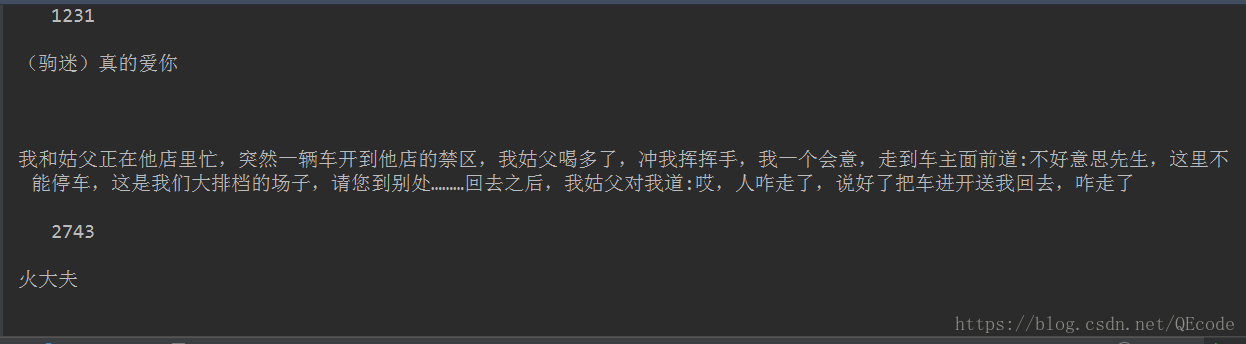
从结果来看,我们已经获取到了我们所需要的信息了.
5 ,完善一下界面和功能
from urllib import request
import re
class QSBK:
# 初始化变量
def __init__(self):
# 糗事百科的网址
self.url = "https://www.qiushibaike.com/hot/page/{}/"
# headers
self.headers = {}
self.headers["User-Agent"] = "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36"
# 读取第几页内容
self.pagenum = 1
# 构造每一次读取页面的url地址
def set_url(self):
# 把页面值传到地址里
url = self.url.format(self.pagenum)
# 页面值加一
self.pagenum += 1
return url
# 读取网页内容,获取其html代码
def get_html(self):
# 设置url
url = self.set_url()
req = request.Request(url=url, headers=self.headers)
# 获取网页内容
response = request.urlopen(req)
# 对网页内容进行解码
html = response.read().decode("utf-8")
return html
# 获取网页html并用正则表达式获取我们需要的内容
def getPage(self):
html = self.get_html()
# 构造正则表达式
zheng = "<div.*?author.*?<a.*?<h2>(.*?)</h2>.*?<div.*?<span>\s*(.*?)\s*</span>.*?<div.*?<span.*?<i.*?>(.*?)</i>"
pattern = re.compile(zheng, re.S)
items = re.findall(pattern, html)
return items
# 输出我们需要的内容
def prin(self):
items = self.getPage()
for item in items:
print("发布人:", item[0], "\n内容:\n ", item[1].replace("<br/>", ""), "\n点赞数:\n", item[2])
print("-"*30)
# 控制输出
def con(self):
while True:
# 输出内容
self.prin()
print("按回车查看新段子,Q退出")
# 等待用户输入
userIn = input()
# 如果输入Q则程序结束
if input == "Q":
print("退出糗事百科")
return
if __name__ == '__main__':
qs = QSBK()
qs.con()
效果图如下:


















 529
529

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









