









爬取漫画网址的并生产一个在线阅读器
代码分析
如果要做一个爬虫的话,一定要会看网页的源代码,看有没有自己想要的数据,
http://m.kkkkdm.com/ 爬取这个网站需要使用的爬取工具只有 jsoup
当我们在这个输入框中输入了《一拳超人》和《灌篮高手》
我们发现只有 https://so.kukudm.com/m_search.asp?kw= 以后的东西不一样 这个只是把我们输入的东西变成了GBK码,
我们只需要使用 URLEncoder.encode();这个方法将我们出入的文字编程GBK码在将我们获取到的GBK码放在https://so.kukudm.com/m_search.asp?kw=后面就可以找到我们想要搜索的漫画
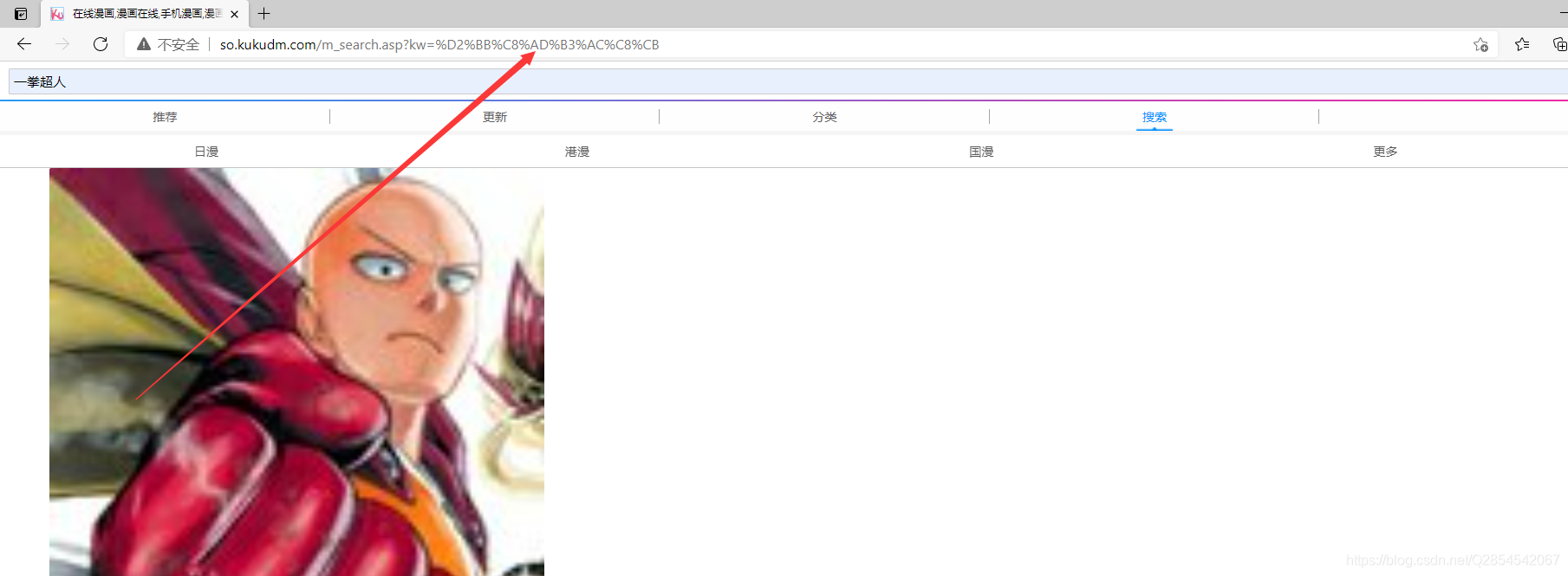
我们发现使用 URLEncoder.encode();这个方法可以获取我们向实现的内容
让后我们使用f12进行源代码查看 ctrl+shift+c点击这个图片我们会发现这个小说的链接路径是在一个li中存储的
我们只需要使用jsoup 获取到这个链接即可
import java.net.URLEncoder;
import java.util.ArrayList;
import java.util.List;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class Test{
public static void main(String[] args) throws Exception {
// 用于存储搜索到漫画名字的集合
List<String> CartoonName=new ArrayList<String>();
// 用于存储搜索到漫画链接地址的集合
List<String> CartoonUrl=new ArrayList<String>();
//将我们输入的文字变成gbk编码
String tail= URLEncoder.encode("一拳超人","gbk");
//向这个网址发送请求
Document document=Jsoup.connect("http://so.kukudm.com/m_search.asp?kw="+tail).get();
//这里我们只获取标签id为classify_container下的li标签下的a标签
Elements str1= document.select("#classify_container>li>a[class=txtA]");
//这里我们只获取标签id为classify_container下的li标签下的a标签
Elements str2= document.select("#classify_container>li>a[href]");
//获取到漫画的名字
for(Element li1:str1) {
CartoonName.add(li1.text());
System.out.println(li1.text());
}
//获取循环获取小说链接
for(Element li2:str2) {
CartoonUrl.add(li2.attr("href"));
System.out.println(li2.attr("href"));
}
}
}
输出结果为:
一拳超人
http://m.kkkkdm.com/comiclist/2035/
现在我们就可以直接使用这个http://m.kkkkdm.com/comiclist/2035/链接复制到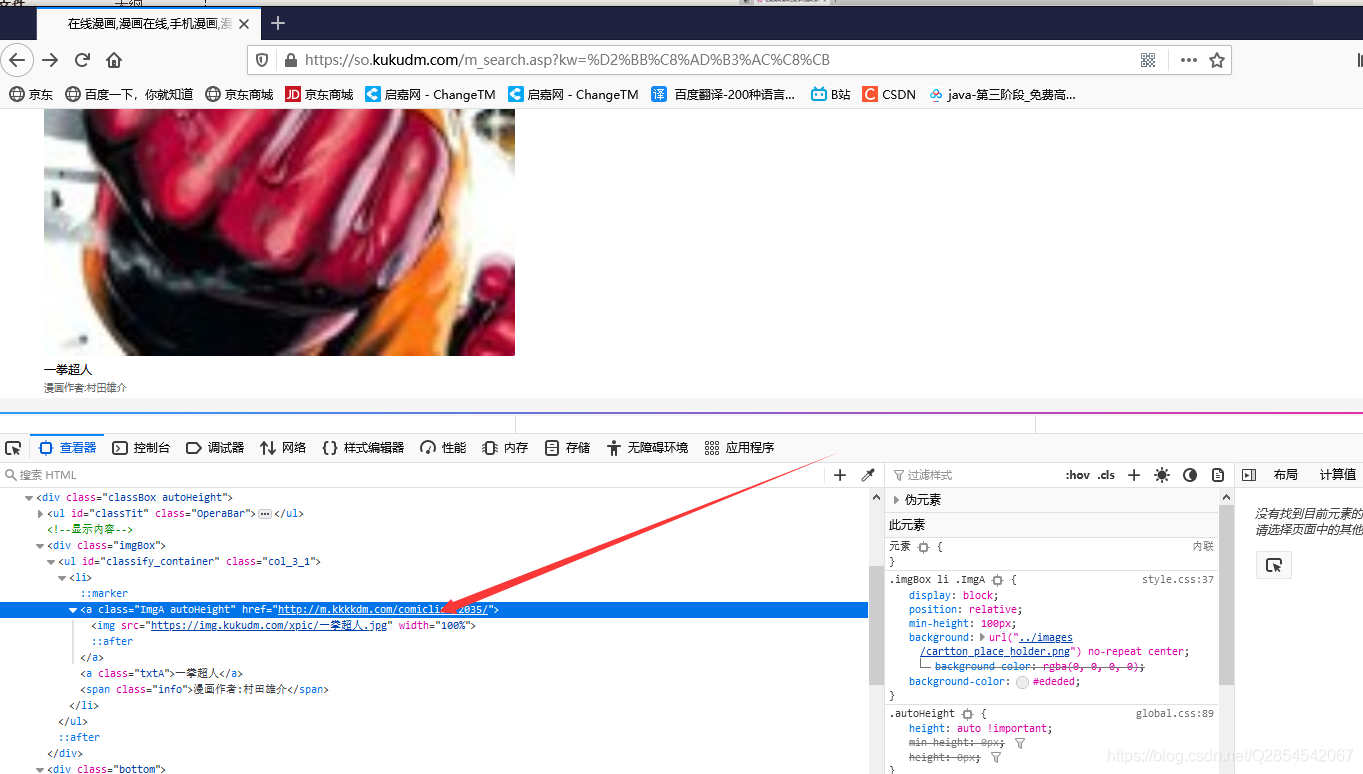
这里进行回车会找到会发现我们进去到了下面这个网址
现在我们再进行f12进行源代码查看,
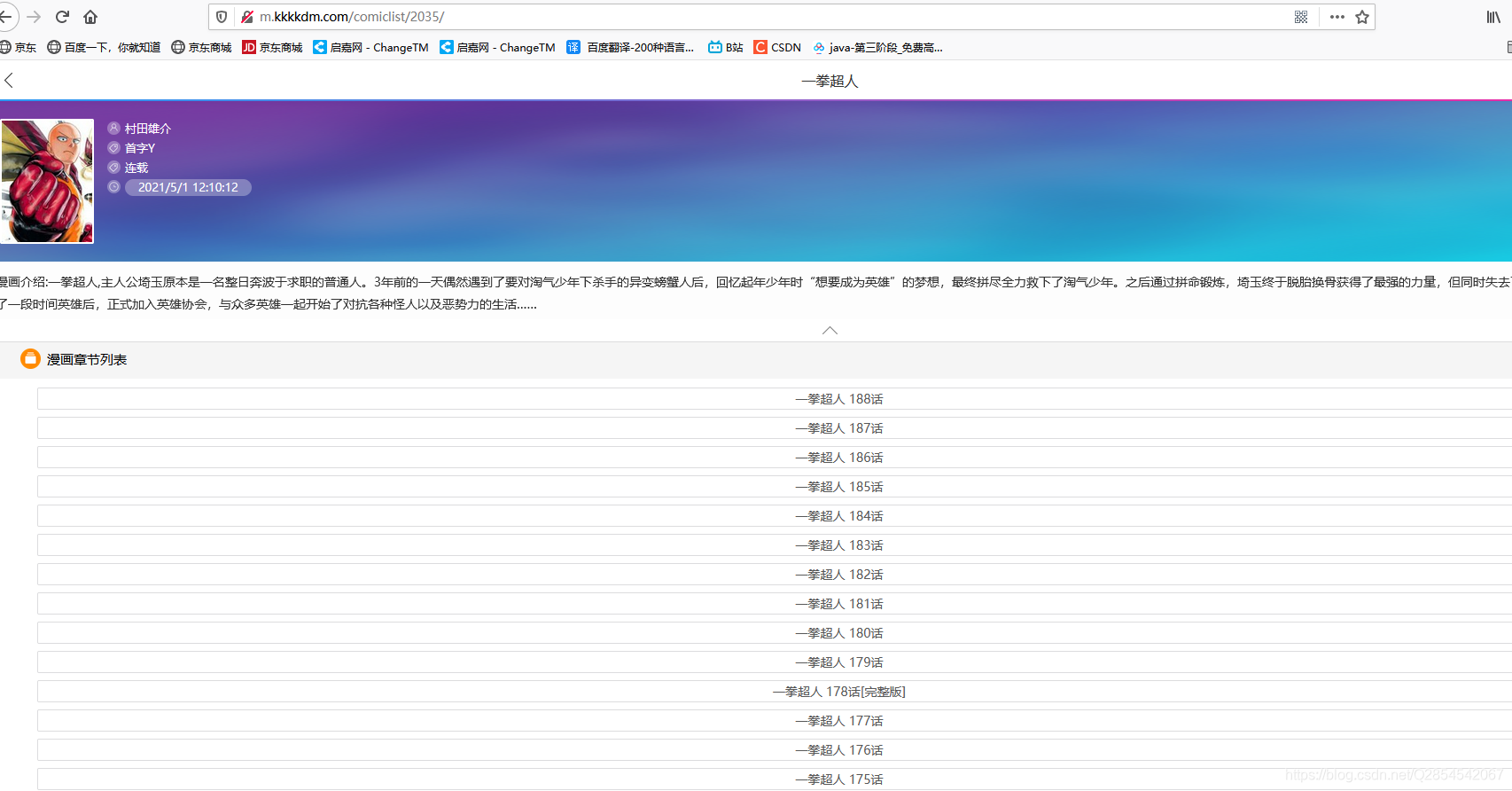
我们会发现他的所有章节链接都存放在id为list的一个div下的il下的a标签属性中的href中存放我们只需要获取这个链接就可以进入本章节
//向获取到的这个一拳超人网址发送请求
Document documentsImgs=Jsoup.connect("http://m.kkkkdm.com/comiclist/2035/").get();
//获取到这个网址中的id为list下li下a标签元素中有的href的a标签
Elements str3= documentsImgs.select("#list>li>a[href]");
//只获取href中的内容,并将这些内容循环添加进集合
for(Element li3: str3) {
ImageUrl.add(li3.attr("href"));
}
System.out.println(ImageUrl);
输出结果为:
我们发现只使用这个获取到的链接是打不开网址的获取到的这些链接前面必须加上http://m.kkkkdm.com这个开头才可以打开 就向这样 http://m.kkkkdm.com加上/http://m.kkkkdm.com/就可以正常打开了
当我们打开一张漫画进行观看时会发现他们的
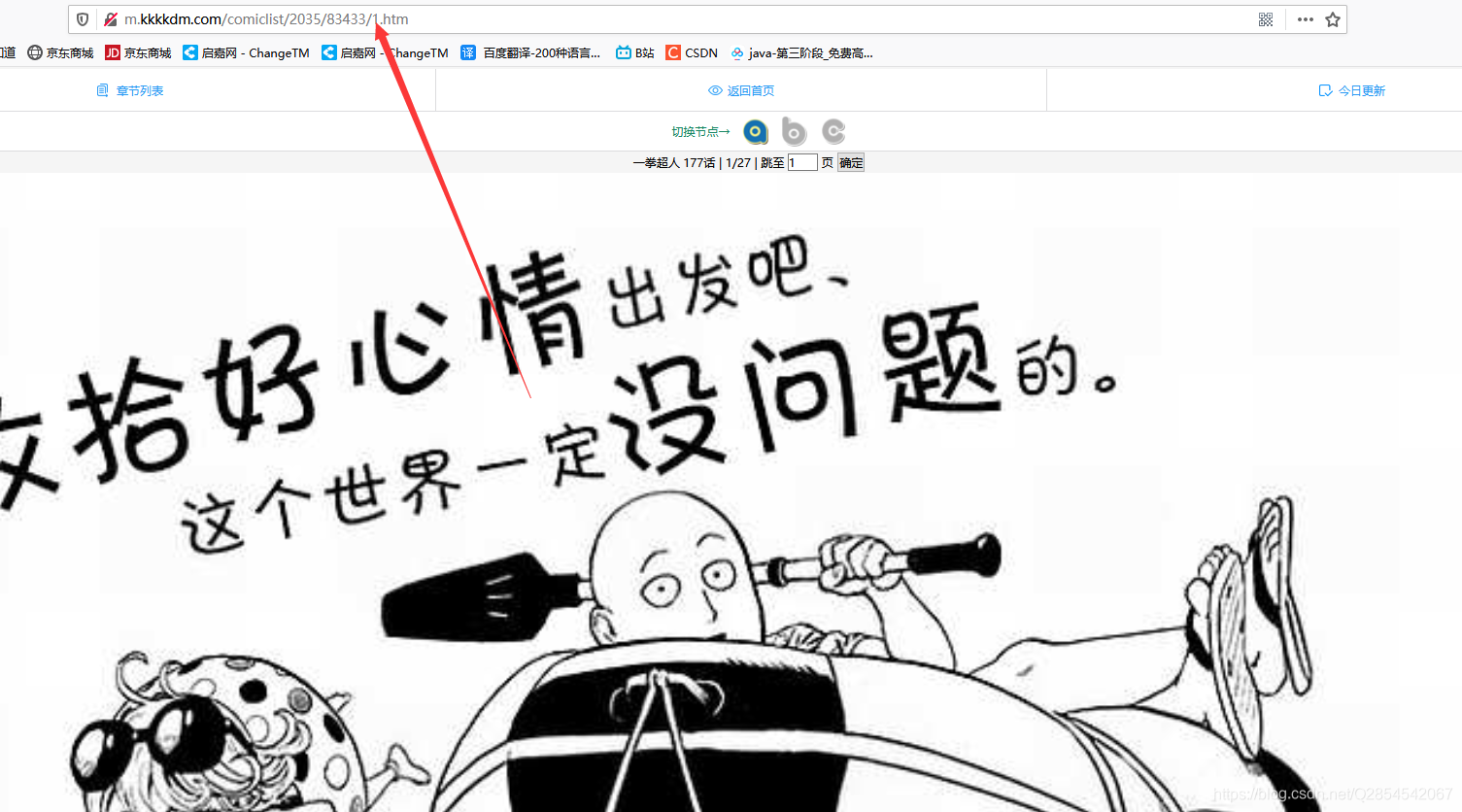
当跳转到下一张的时候
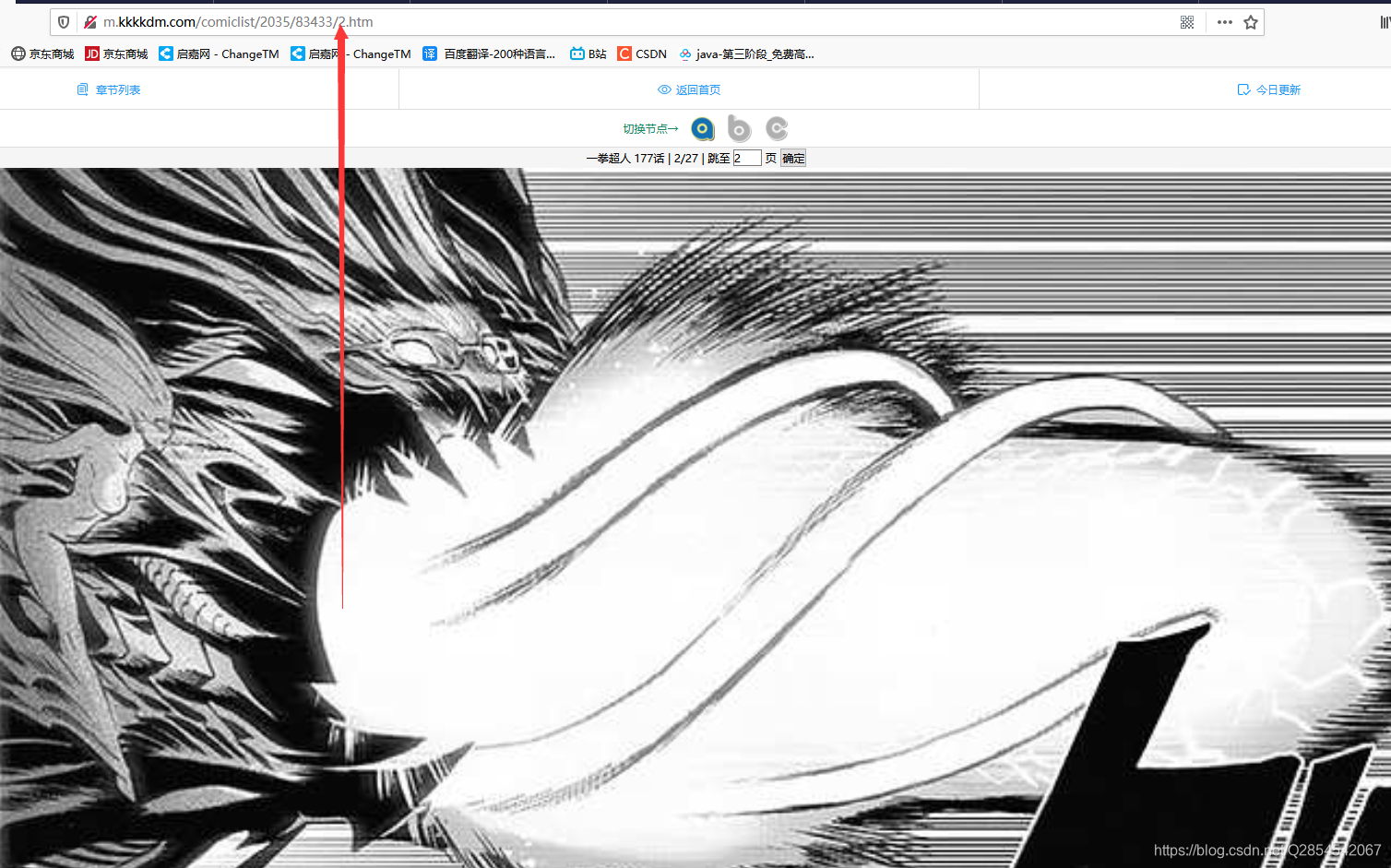
发现只是数字换了一下
那么这样就更简单了我们可以使用循环访问这个网址每次访问的时候只需要变一下这个网址中间的数字就可以进行全部访问,并在访问的时候将图片添加到一个集合中
Document documentsUrl=Jsoup.connect("http://m.kkkkdm.com/comiclist/2035/89000/1.htm").get();
//只获取这个网址的.subNav下的li内容
Elements page= documentsUrl.select(".subNav>li");
//转成String类型
String pages=""+page;
//使用indexOf()方法获取<li>1/在这个字符串中第一出现的位置
int temp=pages.indexOf("<li>1/");
//使用indexOf()方法获取<li class=\"last\">在这个字符串中第一出现的位置
int temps=pages.indexOf("<li class=\"last\">");
//获取本章一共多少多少页数
int tempPage=Integer.parseInt(pages.substring(temp+6,temps-6));
for(int i=1;i<=tempPage;i++) {
//获取这个字符串
String a="/comiclist/2035/89000/1.htm";
//将这个字符串里的页数改为i
String html=a.replaceFirst ("1.htm", i+".htm");
//向这个网页发出请求
Document documentsImgUrl=Jsoup.connect("http://m.kkkkdm.com"+html).get();
//获取这个页面的所有内容并且转为字符串
String box=""+documentsImgUrl;
String u="<IMG SRC='\"+m2007+\"";
//获取<IMG SRC='\"+m2007+\"在box字符串中第一次出现的位置
int num = box.indexOf(u)+u.length();
//获取.jpg在box中第一次出现的位置;
int nums=box.indexOf(".jpg");
//截取box,num到nums+4中间的字符串
String url=box.substring(num,nums+4);
//将"https://tu.kukudm.com/"和url相加添加到CartoonImageUrl集合中
CartoonImageUrl.add("https://tu.kukudm.com/"+url);
以上代码将是将获取到的图片添加到一个集合中
当我们做到这一步时只需要将这个代码整合一些添加到一个简陋的GUI中即可
实现代码
import java.io.IOException;
import java.net.URLEncoder;
import java.util.ArrayList;
import java.util.List;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import javafx.application.Application;
import javafx.event.ActionEvent;
import javafx.event.EventHandler;
import javafx.scene.Scene;
import javafx.scene.control.Button;
import javafx.scene.control.Label;
import javafx.scene.control.TextArea;
import javafx.scene.control.TextField;
import javafx.scene.image.Image;
import javafx.scene.image.ImageView;
import javafx.scene.layout.BorderPane;
import javafx.scene.layout.HBox;
import javafx.scene.layout.VBox;
import javafx.scene.text.Font;
import javafx.stage.Stage;
public class CartoonGUI extends Application{
// 用于存储搜索到漫画名字的集合
List<String> CartoonName=new ArrayList<String>();
// 用于存储搜索到漫画链接地址的集合
List<String> CartoonUrl=new ArrayList<String>();
// 用于存储图片连接
List<String> ImageUrl=new ArrayList<String>();
//定义两个成员变量用于获取一些值
int temp1;
int temp2;
public void start(Stage primaryStage) throws Exception{
//创建两个文本
TextArea textArea=new TextArea();
TextArea textArea1=new TextArea();
//创建一个垂直布局 vbox对象的控件
VBox vbox=new VBox();
BorderPane root=new BorderPane();
//输入框
TextField text1=new TextField();
TextField text2=new TextField();
TextField text3=new TextField();
//创建竖向布局的控件对象
HBox hen=new HBox();
HBox hen1=new HBox();
HBox hen2=new HBox();
//按钮
Button chaxun=new Button("搜索");
Button chaxun1=new Button("进入");
Button chaxun2=new Button("打开");
//在root窗口中上面添加一个vbox控件
root.setTop(vbox);
//在vbox控件中添加控件
vbox.getChildren().addAll(hen,textArea,hen1,textArea1,hen2);
//设置第一个文本框的大小
textArea.setPrefHeight(40);
//给横向布局的控件添加控件
hen.getChildren().addAll(text1,chaxun);
hen1.getChildren().addAll(text2,chaxun1);
hen2.getChildren().addAll(text3,chaxun2);
//将root添加到scene里并设置初始大小
Scene scene = new Scene(root,500,600);
//设置标题
primaryStage.setTitle("super漫画");
//将添加的东西加入窗口
primaryStage.setScene(scene);
//显示窗口
primaryStage.show();
//当点击chaxun按钮的时候出发的代码
chaxun.setOnAction(new EventHandler<ActionEvent>() {
@Override
public void handle(ActionEvent event) {
//点击的时候清空该列表
CartoonName.removeAll(CartoonName);
CartoonUrl.removeAll(CartoonUrl);
textArea.setText("");
//捕获异常
try {
//调用obtain()方法
obtain(text1.getText());
//循环向textArea集合中追加字符串
for(int i=CartoonName.size()-1;i>=0;i--) {
textArea.appendText(i+"-"+CartoonName.get(i)+"\n");
}
//抛出异常
} catch (IOException e) {
e.printStackTrace();
}
}
});
//点击这个按钮时的出发这块代码
chaxun1.setOnAction(new EventHandler<ActionEvent>() {
@Override
public void handle(ActionEvent event) {
// 捕获异常
try {
// 获取文本 将文本内容,将内容转换为Integt类型在拆箱为int
temp1=Integer.parseInt(text2.getText());
// 获取到choice中的nb下标对应的字符串(网址),向这个网址发送请求
Document documents=Jsoup.connect(CartoonUrl.get(temp1)).get();
// 获取到这个网址页面中id元素list下的li下的a标签的href内容
Elements cartoons= documents.select("#list>li>a[href]");
//循环遍历
for (Element element : cartoons) {
//将获取到的标签循环添加到list集合中,并且值获取标签中的href中的字符串
ImageUrl.add(element.attr("href"));
}
// 获取list集合的长度
int lon = ImageUrl.size();
for(int i=ImageUrl.size()-1;i>=0;i--) {
//用来计数
lon--;
// 满足条件时进行换行
if((lon+1)%10==0) {
textArea1.appendText(lon+"\n");
}else {
textArea1.appendText(lon+"\t");
}
}
//抛出异常
}catch (IOException e) {
e.printStackTrace();
}
}
});
//点击此按钮的时候执行的代码
chaxun2.setOnAction(new EventHandler<ActionEvent>() {
@Override
public void handle(ActionEvent event) {
try {
// 获取文本 中的内容,将内容转换为Integt类型在拆箱为int
temp2=Integer.parseInt(text3.getText());
//将list.get(ns)的字符串传入MyWindow()对象中,打开另一个窗口
new MyWindow(ImageUrl.get(temp2));
}//抛出异常
catch (Exception e) {
e.printStackTrace();
}
}
});
}
public static void main(String[] args) {
launch(args);
}
// 创建一个obtain方法用来获取搜索的关键字找出来的漫画链接
public void obtain(String name) throws IOException {
//将文本输入我文本修改为gbk格式的文本
String tail= URLEncoder.encode(name,"gbk");
//获取要搜索的漫画网址 并且发起请求
Document document=Jsoup.connect("http://so.kukudm.com/m_search.asp?kw="+tail).get();
//获取这个网址中搜索到的小说名字
Elements cartoono= document.select("#classify_container>li>a[class=txtA]");
//获取这个网址中搜索到的小说路径
Elements cartoon= document.select("#classify_container>li>a[href]");
//经这个路径转为字符串
String cartoonUrl=""+cartoon;
//将获取到的漫画链接循环放入choice对象集合中
for(Element li:cartoon) {
CartoonUrl.add(li.attr("href"));
}
//获取到漫画的名字
for(Element lil:cartoono) {
CartoonName.add(lil.text());
}
}
}
//创建一个MyWindow类继承一个线程类
class MyWindow extends Thread{
//创建一个窗口对象
private final Stage stage = new Stage();
//创建一个用于储存图片路径的集合
List<String> tup=new ArrayList();
//创建一个Image数组
Image[] image=new Image[999];
//创建一个imageView控件用于在窗口显示图片
ImageView imageView=new ImageView();
//计数的一个成员变量
int sum;
String str;
int currentIndex=0;
//创建按钮控件
Button upper=new Button("上一张");
Button lower=new Button("下一张");
//创建一个有参构造
public MyWindow(String list2) throws Exception{
//向
Document documentsImgs=Jsoup.connect("http://m.kkkkdm.com"+list2).get();
Elements page= documentsImgs.select(".subNav>li");
String pages=""+page;
int temp=pages.indexOf("<li>1/");
int temps=pages.indexOf("<li class=\"last\">");
//获取本章一共多少多少页数
int tempPage=Integer.parseInt(pages.substring(temp+6,temps-6));
//将这个数字赋值给成员变量sum
sum=tempPage;
//将这个字符串赋值给成员变量str
str=list2;
//开启线程
start();
//创建一个文本对象
Label text=new Label();
//布局创建窗口对象;
BorderPane bor = new BorderPane();
//添加背景颜色
bor.setStyle("-fx-background-color:#FFF0F5");
//在bor中间添加一个图片控件,imageView
bor.setCenter(imageView);
//在bor左边添加一个上一页按钮
bor.setLeft(upper);
//在bor右边添加一个下一页按钮
bor.setRight(lower);
//在bor这个底部添加一个文本
bor.setBottom(text);
//添加一个图片在imageView中
imageView.setImage(image[currentIndex]);
//保存缩放比例
imageView.setPreserveRatio(true);
//设置图片初始大小
imageView.setFitWidth(700);
text.setText(currentIndex+"/"+tempPage);
//设置文本大小
text.setFont(new Font("Cambria", 40));
//给文本添加边距
text.setStyle("-fx-padding: 40 20 20 800");
Scene scene = new Scene(bor);
stage.setScene(scene);
//窗口宽高
stage.setHeight(500);//高
stage.setWidth(500);//宽
//设置窗口初始值为最大化
stage.setMaximized(true);
//显示窗口
stage.show();
//点击upper按钮时执行的代码
upper.setOnAction(new EventHandler<ActionEvent>() {
@Override
public void handle(ActionEvent event) {
//用来轮播图片的代码的方法
upperbtn();
//在窗口上显示当前页数
text.setText(currentIndex+"/"+tempPage);
}
});
lower.setOnAction(new EventHandler<ActionEvent>() {
@Override
public void handle(ActionEvent event) {
//用来轮播图片的代码的方法
lowerbtn();
//在窗口上显示当前页数
text.setText(currentIndex+"/"+tempPage);
}
});
}
//每当这个方法被调用时都会执行这个代码 下一页
public void upperbtn() {
currentIndex--;
//判断当前页数有没有超出范围
if(currentIndex<0) currentIndex=tup.size()-1;
imageView.setImage(image[currentIndex]);
}
//每当这个方法被调用时都会执行这个代码 下一页
public void lowerbtn() {
currentIndex++;
//判断当前页数有没有超出范围
if(currentIndex>=tup.size()) currentIndex=0;
imageView.setImage(image[currentIndex]);
}
//重写run方法
public void run() {
//捕获异常
try {
//循环sum次
for(int i=1; i<=sum;i++) {
//将str的字符串赋值给a
String a=str;
// 使用字符串指定修改某个字符来获取不同的页面
String html=a.replaceFirst ("1.htm", i+".htm");
//向这些页面发出请求
Document kk = Jsoup.connect("http://m.kkkkdm.com"+html).get();
String box=""+kk;
String u="<IMG SRC='\"+m2007+\"";
//获取字符的长度和u字符串在box中出现的位置,并相加并使用num接收这个值;
int num = box.indexOf(u)+u.length();
//获取.jpg在box中出现的位置,并用nums接收这个值
int nums=box.indexOf(".jpg")+4;
//使用num,nums这两个值来截取取这个字符串
String url=box.substring(num,nums);
//将这些截取到的字符串添加到tup这个集合中
tup.add("https://tu.kukudm.com/"+url);
// 使用image数组来获取这个集合里的东西
image[i-1]=new Image(tup.get(i-1));
//输出这个图片
System.out.println(image[i-1]);
}
}catch (Exception e) {
e.printStackTrace();
}
}
}
程序可能有考虑不全面,或者有bug,欢迎大家指正

















 2246
2246

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









