




 本文详细介绍了ClickHouse的Distributed表引擎,它用于分布式查询且不存储数据,利用索引自动并行读取。内容包括Distributed表引擎的参数解析,如cluster_name、database、table和sharding_key,并通过实例展示了如何创建和使用Distributed表,包括数据的分片和插入机制。
本文详细介绍了ClickHouse的Distributed表引擎,它用于分布式查询且不存储数据,利用索引自动并行读取。内容包括Distributed表引擎的参数解析,如cluster_name、database、table和sharding_key,并通过实例展示了如何创建和使用Distributed表,包括数据的分片和插入机制。
一:Distributed介绍
分布式引擎,本身不存储数据,但可以在多个服务器上进行分布式查询。读是自动并行的。读取时,远程服务器表的索引(如果存在)会被使用。
Distributed(cluster_name, database, table, [sharding_key])
参数解析:
cluster_name:服务器配置文件中的集群名,在/etc/metrika.xml中配置的。具体配置见前文。
database:数据库名。
table:表名。
sharding_key:数据分片键。
二:Distributed使用
1. 在三台机器上分别创建一个表t。
create table t(id UInt16, name String) engine=TinyLog;
2. 在三台机器的t表中插入一些数据。
insert into t(id, name) values(1, 'zs');
insert into t(id, name) values(2, 'ls');
3. 在192.168.44.129上创建分布式表。
create table dis_table(id UInt16, name String) engine=Distributed(clickhouse_cluster, default, t, id);
4. 查看结果。
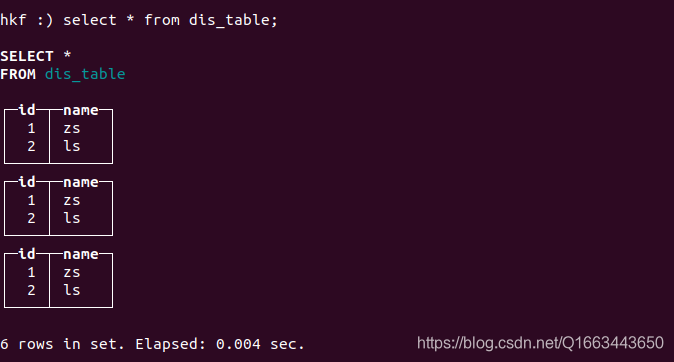
可以看到,三台机器的数据都拿到了。
5. 向分布式表插入数据。
insert into dis_table(id, name) values(3, 'aa');
insert into dis_table(id, name) values(4, 'bb');
查看结果:
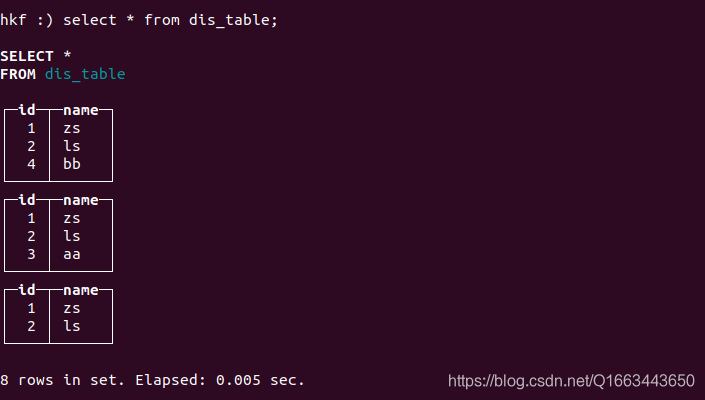
插入机制是根据指定的分片键id,对插入的id进行哈希计算,然后放到分片里面。

















 3668
3668




 到【灌水乐园】发言
到【灌水乐园】发言







