




 本文介绍了ClickHouse中表引擎的作用,包括数据存储、查询支持、并发访问等方面,并详细讲解了TinyLog、Memory和Merge三种常用的表引擎。TinyLog适合一次性写入的小表,Memory引擎提供极高读写速度但数据易丢失,Merge引擎用于合并多个表数据,不支持写入。
本文介绍了ClickHouse中表引擎的作用,包括数据存储、查询支持、并发访问等方面,并详细讲解了TinyLog、Memory和Merge三种常用的表引擎。TinyLog适合一次性写入的小表,Memory引擎提供极高读写速度但数据易丢失,Merge引擎用于合并多个表数据,不支持写入。
一:表引擎作用
表引擎(即表的类型)决定了:
1)数据的存储方式和位置,写到哪里以及从哪里读取数据。
2)支持哪些查询以及如何支持。
3)并发数据访问。
4)索引的使用(如果存在)。
5)是否可以执行多线程请求。
6)数据复制参数。
二:几种常用的表引擎
1. TinyLog
最简单的表引擎,用于将数据存储在磁盘上。每列都存储在单独的压缩文件中,写入时,数据将附加到文件末尾。
该引擎没有并发控制。
如果同时从表中读取和写入数据,则读取操作将抛出异常。
如果同时写入多个查询中的表,则数据将被破坏。
不支持索引。
这种表引擎的典型用法是write-once,首先只写入一次数据,然后根据需要多次读取。此引擎适用于相对较小的表(建议最多1000000行)。如果有许多小表,则使用此表引擎是适合的,因为它需要打开的文件更少。当拥有大量小表时,可能会导致性能低下。
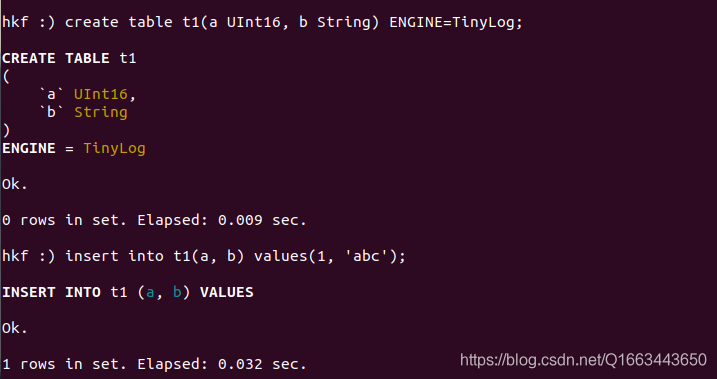
例:创建一个TinyLog引擎的表并插入一条数据。
create table t1(a UInt16, b String) ENGINE=TinyLog;
insert into t1(a, b) values(1, 'abc');
运行结果:
插入完成后,我们进入存储的地方:
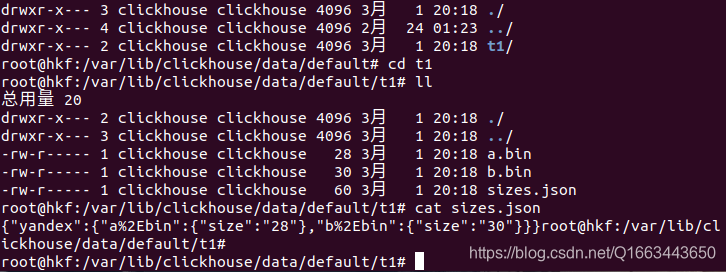
如上图所示,进入刚才创建的t1,可以看到a.bin,b.bin,sizes.json三个文件,其中前两个是压缩过的对应的列的数据,sizes.json则记录了每个*.bin的大小。
2. Memory
内存引擎,数据以未压缩的原始形式直接保存在内容当中,服务器重启数据就会消失。
读写操作不会相互阻塞,不支持索引。简单查询下有非常非常高的性能表现(超过10G/s)。一般用到它的地方不多,除了用来测试,就是在需要非常高的性能,同时数据量又不太大(上限大概1亿行)的场景。
3. Merge
Merge引擎本身不存储数据,但可用于同时从任意多个其他的表中读取数据。表是自动合并的,不支持写入。读取时,那些被真正读取到数据的表的索引(如果有的话)会被使用。
Merge引擎的参数:一个数据库名和一个用于匹配表名的正则表达式。
例:先建t1,t2,t3三个表,然后用Merge引擎的t表把他们链接起来。
首先创建t1,t2,t3,并且插入数据:
create table t1(id UInt16, name String) ENGINE=TinyLog;
create table t2(id UInt16, name String) ENGINE=TinyLog;
create table t3(id UInt16, name String) ENGINE=TinyLog;
insert into t1(id, name) values(1,'aaa');
insert into t2(id, name) values(2,'bbb');
insert into t3(id, name) values(3,'ccc');
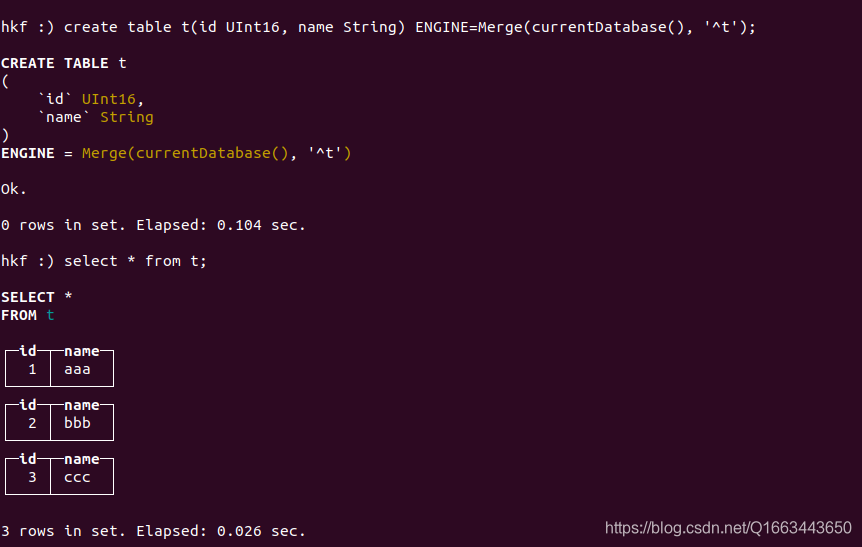
然后创建表t:
create table t(id UInt16, name String) ENGINE=Merge(currentDatabase(), '^t');
select * from t;
结果如下:
如果对t表插入数据肯定会报错!

下篇文章将对MergeTree进行详细讲解!!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









