 Python自动搜索关键词采集京东信息
Python自动搜索关键词采集京东信息





 本文通过Python网络爬虫工具集搜客,演示如何设置连续动作自动搜索关键词并在京东采集商品信息。教程涵盖从定义规则、设置连续动作、创建二级规则到抓取数据的全过程。
本文通过Python网络爬虫工具集搜客,演示如何设置连续动作自动搜索关键词并在京东采集商品信息。教程涵盖从定义规则、设置连续动作、创建二级规则到抓取数据的全过程。
一、操作步骤
如果网页上有搜索框,但是搜索结果页面没有独立网址,想要采集搜索结果,直接做规则是采集不到的,要先做连续动作(输入+点击)来实现自动输入关键词并搜索,然后才能采集数据。下面用京东搜索为例,演示自动搜索采集,操作步骤如下:


二、案例规则+操作步骤
- 第一级采集规则:连续动作_京东搜索
- 第二级采集规则:京东空调列表
- 样本网址:https://list.jd.com/list.html?cat=737,794,870
- 采集内容:京东商品的名称、价格、链接
**注意:**本案例京东搜索是有独立网址的,对于具有独立网址的页面,最简单的方法就是构造出每个关键词的搜索网址,然后把线索网址导入到规则里,就可以批量采集,而不是设置连续动作
第一步:定义第一级规则
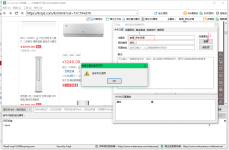
1.1打开集搜客网络爬虫,输入网址并Enter,加载出网页后再点击“定义规则”按钮,看到一个浮窗显示出来,称为工作台,在上面定义规则;
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 71万+
71万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









