 微信好友信息统计与可视化
微信好友信息统计与可视化





技术群里一位读者微信私聊我,问我能不能统计下微信好友信息并以文件形式保存。其实,以前也写过类似的文章,一篇是微信好友性别统计,一篇是制作好友签名的词云图。比较分散,今天就索性把他们整合一下,一次性完成制作好友信息 csv 表格、性别统计饼图、昵称词云图、个性签名词云图、好友城市地区分布柱形图。
效果图
以下是本次程序运行后生成的信息图。(源码获取方式文末已给出)
1、好友信息表格
csv 文件中包括昵称、备注名称、性别(1 表示男,2 表示女,0 表示没有填写性别信息)、个性签名、省份、城市。第一条信息是自己的信息。
Python资源共享群:484031800

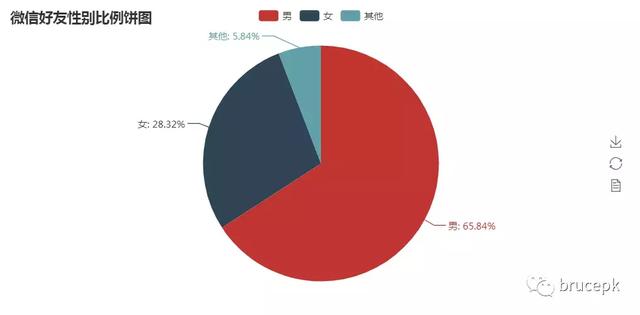
2、好友性别统计饼状图
此图根据收集的好友信息的性别进行统计比例,图中看到我的微信好友中男性还是占大多数的,也有一部分伙伴不愿意透露自己的性别。

3、好友昵称词云图
对微信好友的昵称收集进行分词后做成词云图,图中字体越大表示出现的次数越多。看来有部分伙伴喜欢取叠词作为昵称,像露露、大大、甜甜、西西之类的。其他的昵称有「人生」和「天下」的豪迈,也有「蜗牛」和「晴天」的惬意。

4、好友个性签名词云图
对微信好友的个性签名收集进行分词后做成词云图,图中字体越大表示出现的次数越多。人生、奋斗、生活、努力、世界、未来等是我微信好友签名的主旋律,看来大家都是积极向上的乐观派。

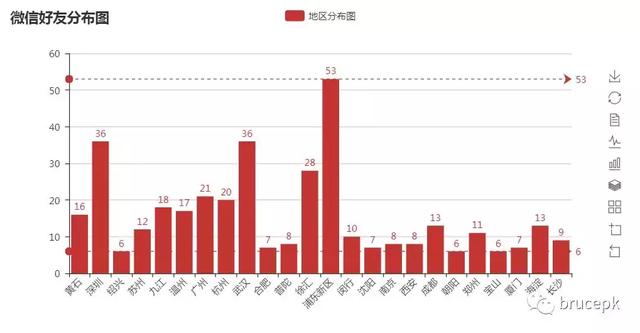
5、好友主要城市分布柱形图
对微信好友资料中填写的城市或地区进行统计,图中为了展示效果,我去掉了地区个数小于 5 个的地区数据。
项目环境
语言:Python
编辑器:Pycharm
导包
需要导入的主要包如下:
- itchat:Python 实现调用微信接口的第三方模块。
- jieba:分词库,用于制作词云图前的分词。
- matplotlib:画词云图需要用到。
- wordcloud:画词云图需要用到。
- pyecharts:用于画柱形图和饼状图。
代码分析
代码结构由 7 部分组成,收集好友信息、整合信息、保存为 csv 文件、制作性别统计饼图、制作昵称词云图、制作个性签名词云图、制作好友城市地区分布柱形图。下面对这 7 部分进行分析讲解。
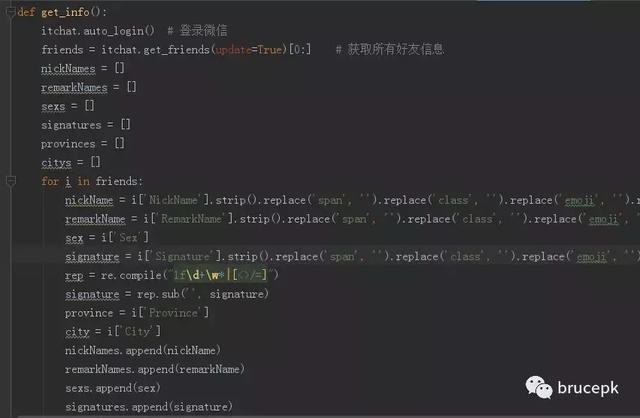
收集信息
通过 itchat 库获取所有微信好友信息并进行整理,并将好友信息一一对应打包成元组,主要代码如下。
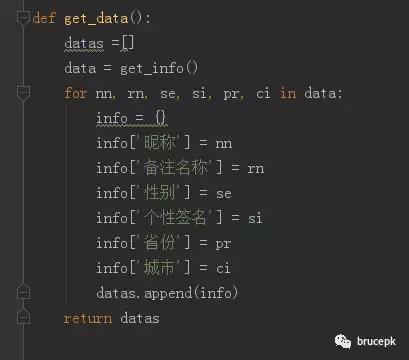
整合信息
把收集的信息整合成字典形式,方便之后对信息进行更方便的提取,主要代码如下。
保存csv文件
将上面的字典信息保存为 csv 文件,保存文件的方法之前项目也经常用到,在此不再赘述,主要代码如下。

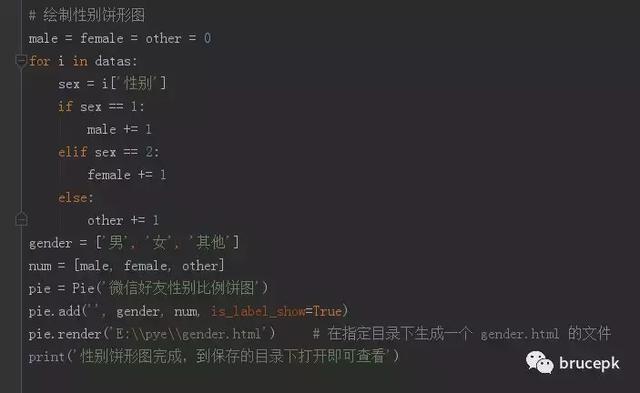
制作性别统计饼图
在上面收集的信息中遍历好友性别信息,为 1 时,男性数量加 1,为 2 时,女性数量加 1,其他就是表示没填写性别信息的。调用 pyecharts 库中的 Pie 方法制作饼图,生成的是一个 html 文件,打开此文件就会显示统计饼图。此文件保存目录需自己指定目录,不然会报错,代码如下。
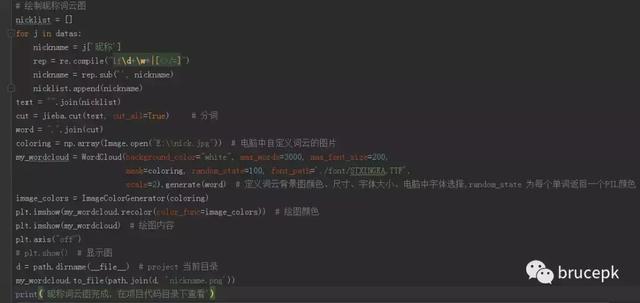
制作昵称词云图
从上面获取的信息中提取所有好友的昵称信息,进行分词。制作词云图的背景图需要指定详细的本地路径。对词云图的参数进行设置,词云图里的字体 font_path 可以更改成自己喜欢的字体,Windows 电脑一般在系统盘\Windows\Fonts 目录下,右键点击你要设置的字体查看属性就可以看到该字体的名称。
生成的词云图我保存在该项目代码的同一目录下,主要代码如下。
制作个性签名词云图
个性签名词云图和昵称词云图的代码几乎一样,只是从上面信息取的是个性签名信息做成词云图而已。代码中保存的词云图名称改成和昵称词云图不同即可,不然会覆盖保存。当然你可以把制作词云图的背景图换一个,由于代码几乎一样,就不做展示了。
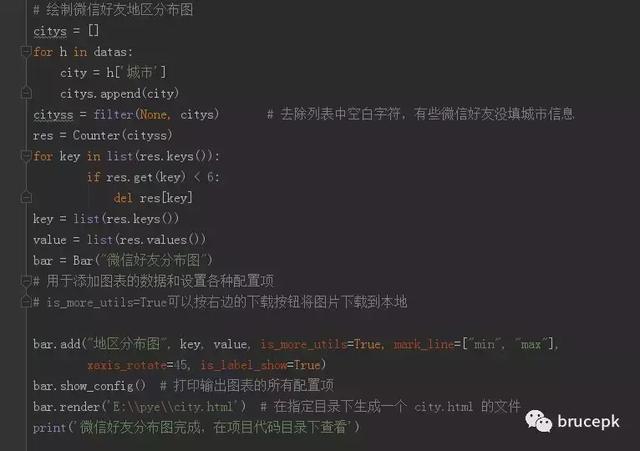
制作好友城市分布图
提取信息中的城市或地区信息,去除没填写地区或城市的空白字符。对地区信息进行统计,为了展示效果,我去掉了所在地区个数在 5 个以下的情况,因为城市太多,图会显得很臃肿。调用 pyecharts 库中的 Bar 方法制作柱形图,生成的也是一个 html 文件,和上面制作性别比例饼图一样。html 文件保存目录需自己指定目录,代码如下。
用 Python 制作这些可视化图形之前文章也讲过,没来记得看的戳这里查看 Python让你的数据生成可视化图形

















 3195
3195

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









