



步骤
- 将目标网站下的页面抓取下来
- 将抓取下来的数据根据一定规则进行提取
具体流程
- 将目标网站下的页面抓取下来
1. 倒库
import requests
2.头信息(有时候可不写)
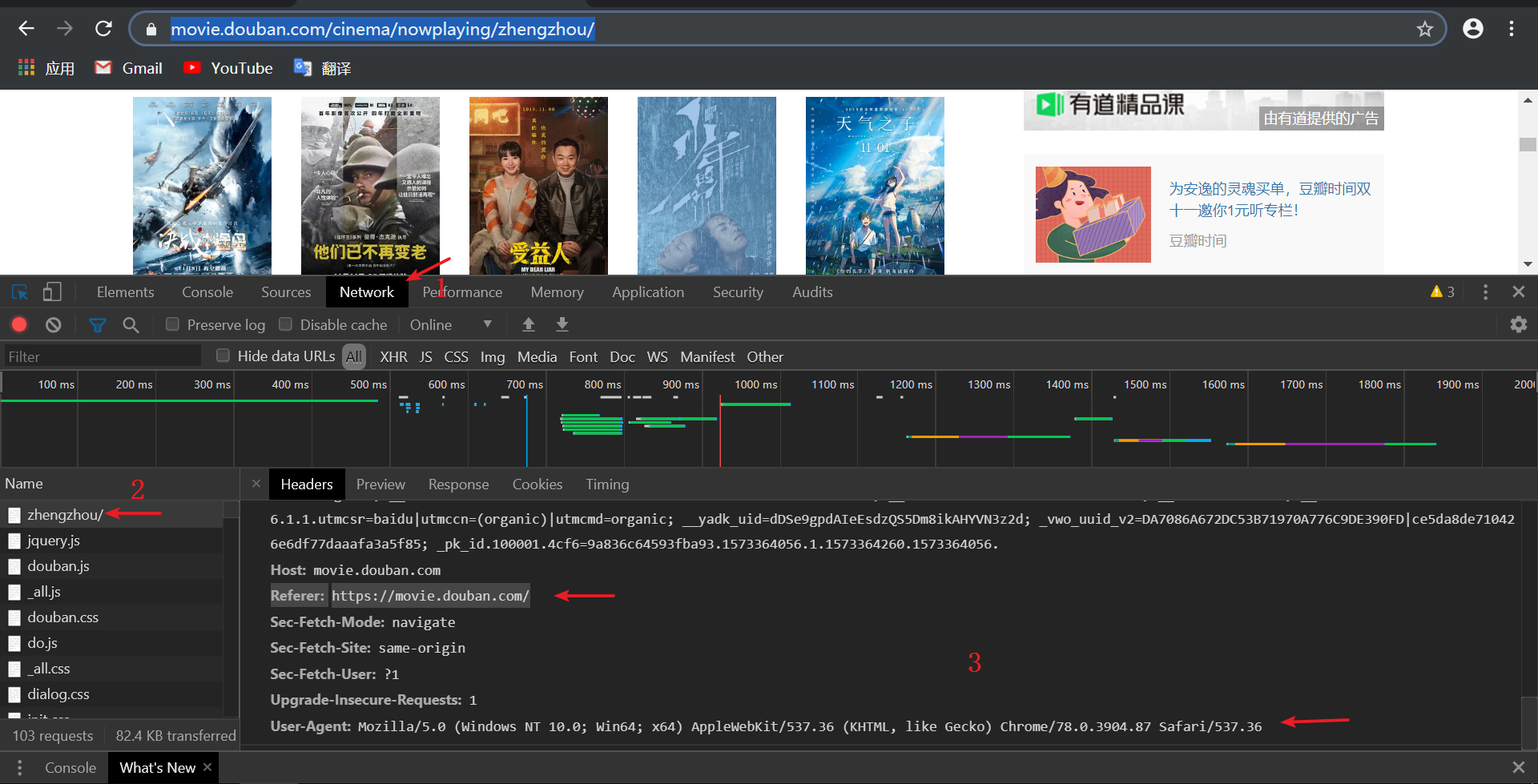
headers = {
#请求身份/默认为User-Agent:python
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.87 Safari/537.36',
'Referer': 'https://movie.douban.com/'
}
3.url
url = 'https://movie.douban.com/cinema/nowplaying/zhengzhou/'
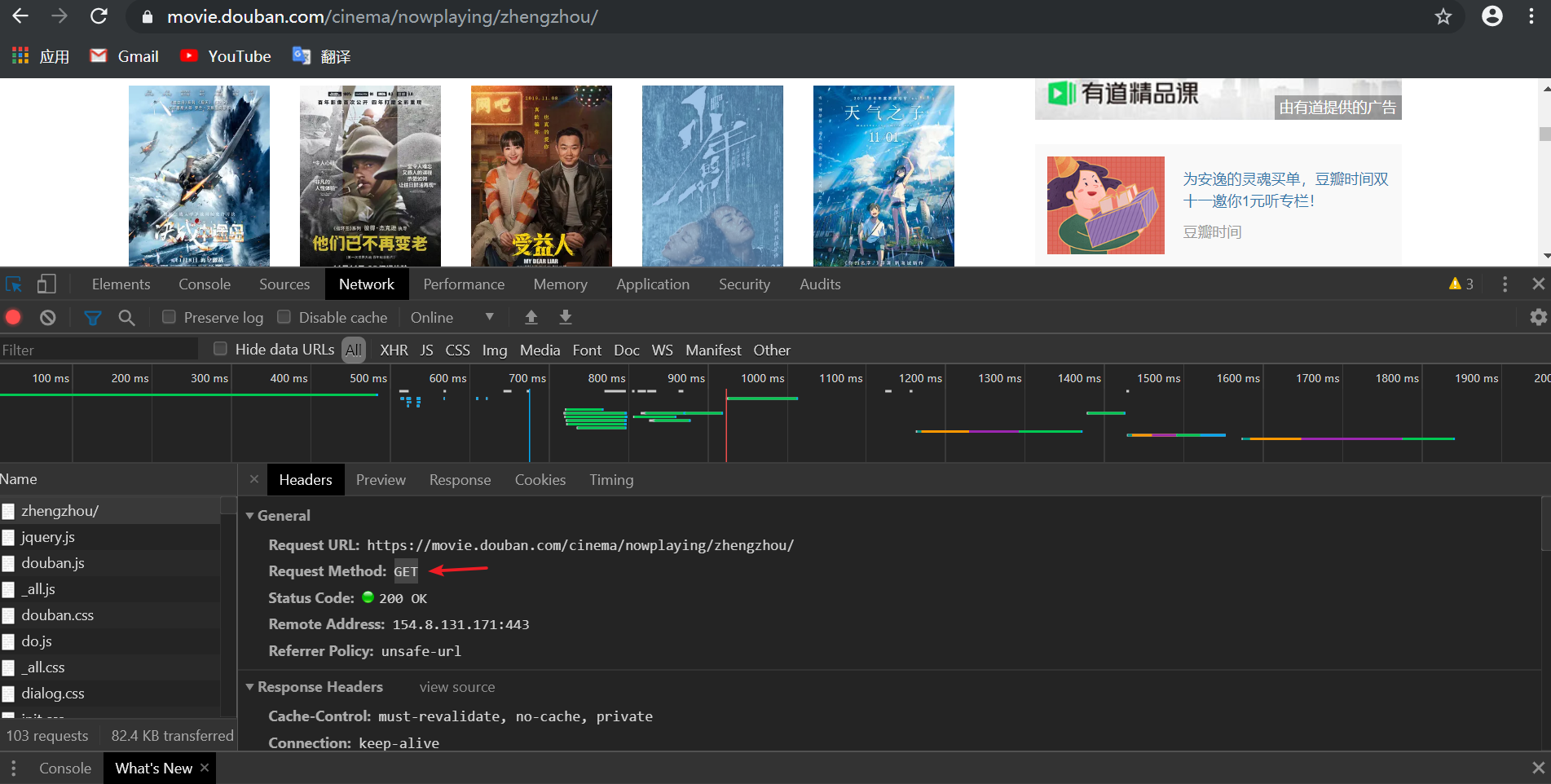
4.返回响应
response = requests.get(url,headers=headers) #响应
#print(response.text)
text = response.text
response.text:返回的是一个经过解码后的字符串,是str(unicode)类型
response.concent:返回的是一个原生的字符串,就是从网页上抓取下来的,没有经过解码的字符串,是bytes类型
2.将抓取下来的数据根据一定规则进行提取
1.将爬取下来是数据用lxml进行解析
from lxml import etree
html = etree.HTML(text)
2.获取ul、li下的 ‘title’、‘score’、‘poster’
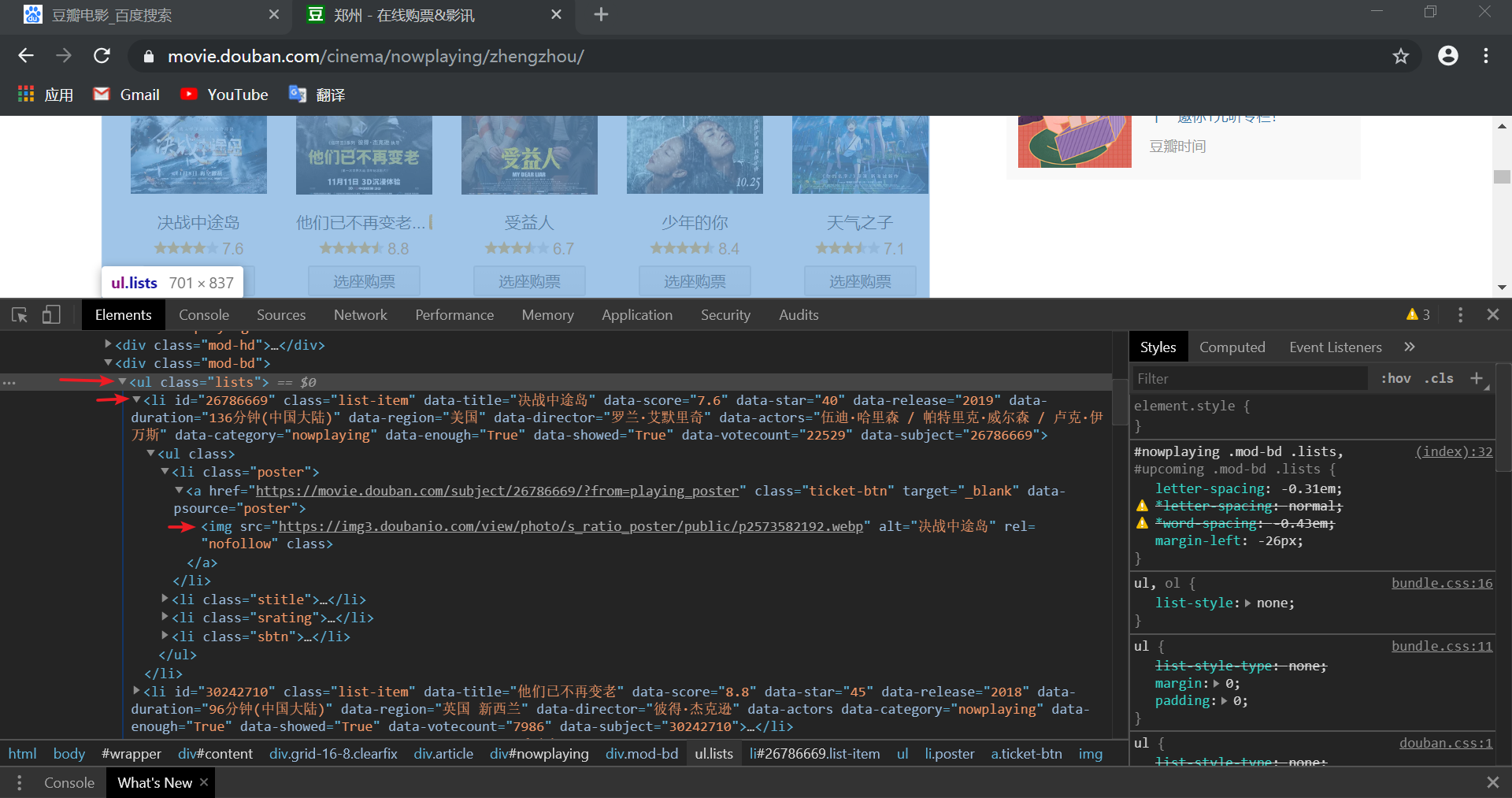
先看看框架
ul (class=‘list’)
li ······
ul
li
a ······
ul = html.xpath("//ul\[@class='lists'\]")\[0\]
#print(etree.tostring(ul,encoding='utf-8').decode('utf-8'))
lis = ul.xpath('./li')
for li in lis:
#print(etree.tostring(li,encoding='utf-8').decode('utf-8'))
title = li.xpath('@data-title')\[0\]
#print(title)
score = li.xpath('@data-score')\[0\]
# print(score)
poster = li.xpath('.//img/@src')\[0\]
# print(poster)
[0] 只获取第一个内容
// 获取网页当中所有的元素
./ 在当前标签下获取
.// 在当前标签下下获取
xpath返回的是列表的形式 [‘’],[0]就可以只拿内容
3.储存信息
1.下载
request.urlretrieve(poster, 'D:/A/' + score + title + '.jpg')
下载到D盘下A目录中,文件名为 评分+影名.jpg
2.显示进度条
fns\_num = 1
num = len(lis)
for li in lis:
···
print("\\r完成进度: {:.2f}%".format(fns\_num \* 100 / num), end="")
fns\_num += 1
完整版Python项目源码,点击领取 100%免费!
👉 这份完整版的Python全套学习资料已经上传,朋友们如果需要可以扫描下方优快云官方认证二维码或者点击链接免费领取【保证100%免费】


















 1948
1948

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









