




 本文是Python爬虫教程,介绍如何使用selenium模拟登录并抓取QQ群成员信息,详细讲解了登录、选择群组、动态加载信息的页面分析及代码实现过程。
本文是Python爬虫教程,介绍如何使用selenium模拟登录并抓取QQ群成员信息,详细讲解了登录、选择群组、动态加载信息的页面分析及代码实现过程。
Python–selenium 加载并保存QQ群成员,去除其群主、管理员信息。
基本思路
模拟登陆页面
页面分析
思路:
点击登陆按钮
选择要登陆的账号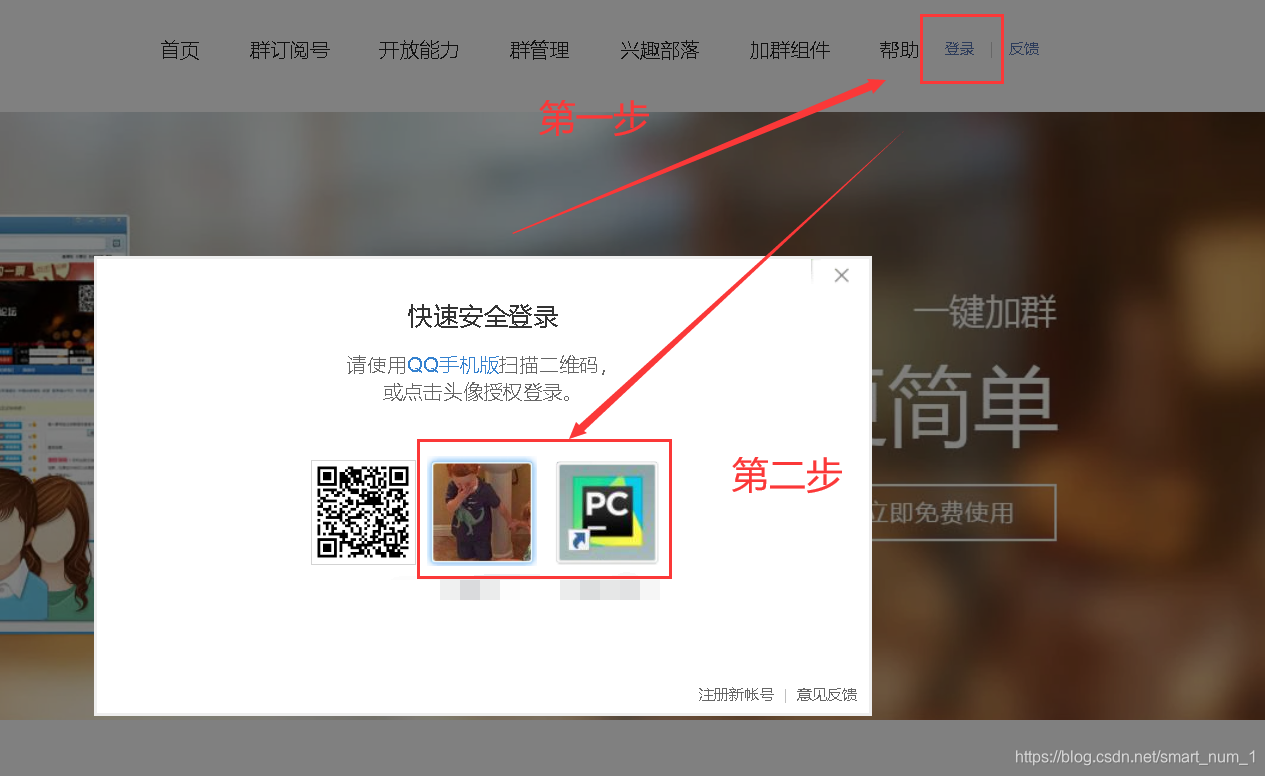
代码实现
# Author:smart_num_1
# Blog:https://blog.youkuaiyun.com/smart_num_1
# WeChat:Be_a_lucky_dog
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
def  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1114
1114





 到【灌水乐园】发言
到【灌水乐园】发言







