




 本文介绍了如何使用Python爬取Bilibili的弹幕数据,并通过BeautifulSoup解析XML文件,利用jieba分词后生成词云。以TES vs SN第四场决胜局为例,详细阐述了寻找弹幕数据源、去除标点符号和空格的步骤,最后展示了词云效果。
本文介绍了如何使用Python爬取Bilibili的弹幕数据,并通过BeautifulSoup解析XML文件,利用jieba分词后生成词云。以TES vs SN第四场决胜局为例,详细阐述了寻找弹幕数据源、去除标点符号和空格的步骤,最后展示了词云效果。
Python爬取bilibili弹幕并生成词云
目标网站:
我这里以 TES vs SN 第四场决胜局为例:
探索经历:
很多人学习python,不知道从何学起。
很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手。
很多已经做案例的人,却不知道如何去学习更加高深的知识。
那么针对这三类人,我给大家提供一个好的学习平台,免费领取视频教程,电子书籍,以及课程的源代码!??¤
QQ群:623406465
首先我们要找到我们想要爬取的弹幕都发在哪:
我们先播放这个视频,随便记住一条弹幕,到审查元素里面搜索

哎,可以找到,然后我们再查看一下网页的源代码,没有搜索结果。。。。。。这说明bilibili的弹幕是动态加载的,是js请求的数据,可能是json,也可能是XML
通常我们都会通过翻页等操作让网页进行js请求,我们在“后台”盯着,看有没有多出来的文件,依次翻看一下里面的东西,看看有没有存放弹幕的文件,于是我继续播放视频,列表里也确实多了很多文件

但很可惜并没有找到我想要的存储弹幕的文件
我觉得播放视频还是没能请求到弹幕文件,于是我找到了第二种方法:(需要先登陆一下)
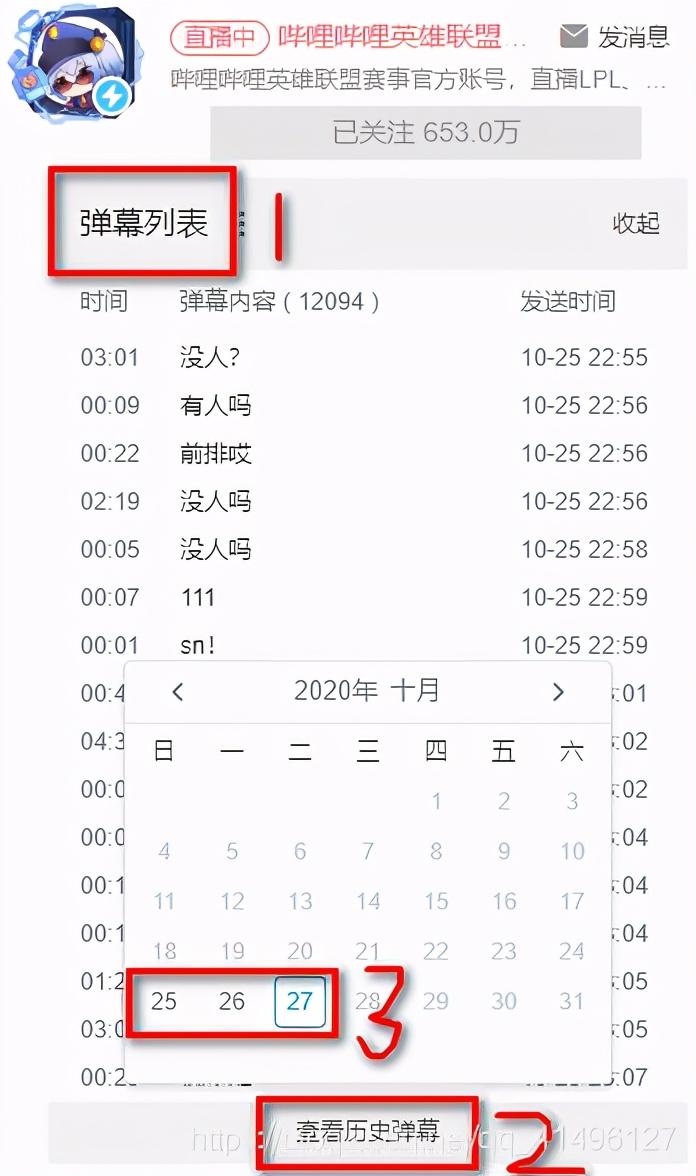
如图,切换不同的日期可以找到我们想要的存储
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 643
643




 到【灌水乐园】发言
到【灌水乐园】发言







