




 本文介绍了如何使用Python进行网络爬虫,通过requests和BeautifulSoup库,三步轻松实现下载200个页面的表情包图片,总计9000张。首先获取HTML,然后解析HTML获取图片信息,最后将图片保存到本地。
本文介绍了如何使用Python进行网络爬虫,通过requests和BeautifulSoup库,三步轻松实现下载200个页面的表情包图片,总计9000张。首先获取HTML,然后解析HTML获取图片信息,最后将图片保存到本地。
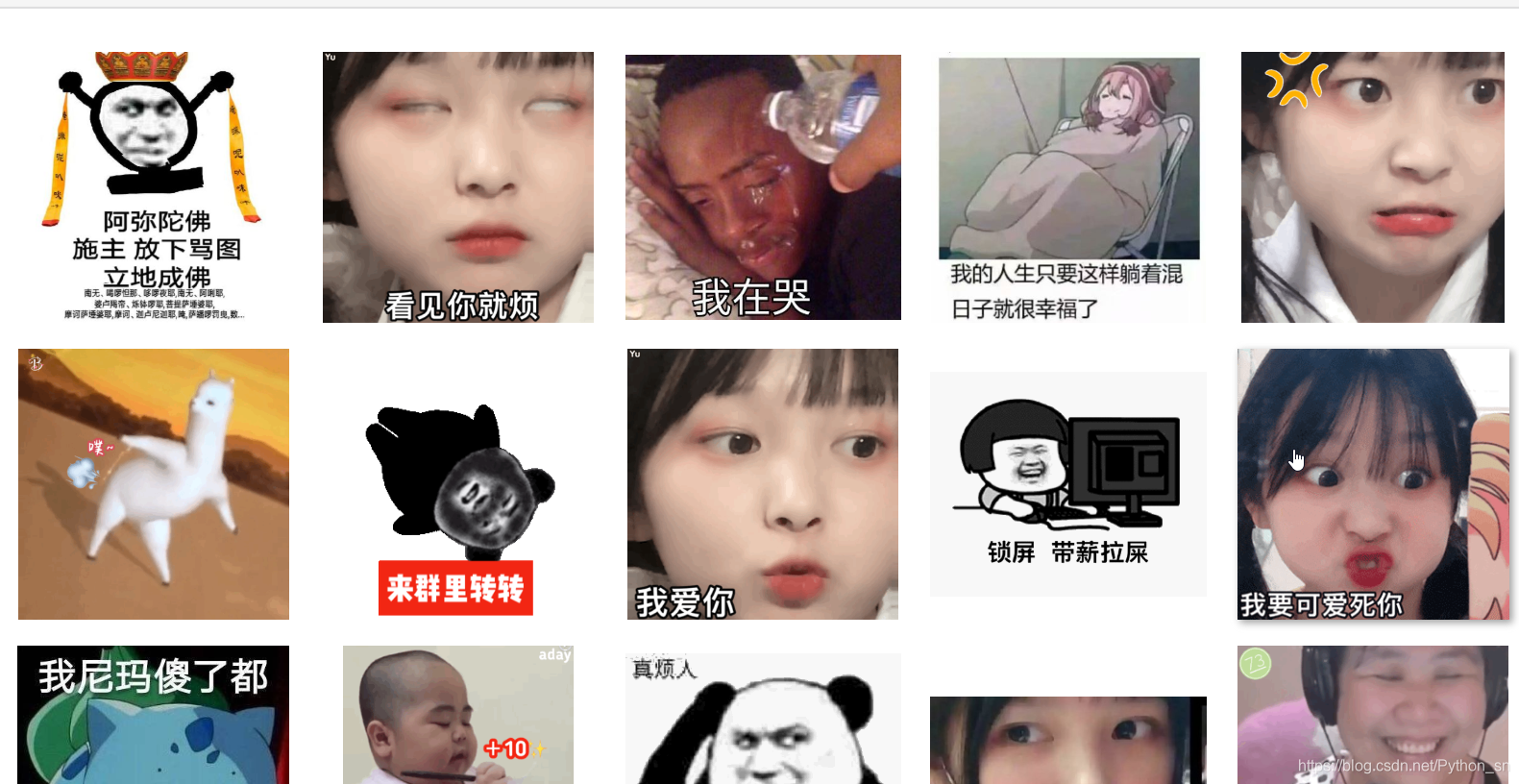
先看下我的爬取成果:
很多人学习python,不知道从何学起。
很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手。
很多已经做案例的人,却不知道如何去学习更加高深的知识。
那么针对这三类人,我给大家提供一个好的学习平台,免费领取视频教程,电子书籍,以及课程的源代码!
QQ群:961562169
本视频的演示步骤:
- 使用requests爬取200个网页
- 使用BeautifulSoup实现图片的标题和地址解析
- 将图片下载到本地目录
这2个库的详细用法,请看我的其他视频课程
import requests
from bs4 import BeautifulSoup
import re
1、下载共200个页面的HTML
def download_all_htmls():
"""
下载所有列表页面的HTML,用于后续的分析
"""
htmls = []
for idx in range(200):
url = f"https://fabiaoqing.com/biaoqing/lists/page/{idx+1}.html"
print("craw html:", url)
r = requests.get(url)
if r.status_code != 200:
raise Exception("error")
htmls.append(r.text)
print("success")
return htmls
# 执行爬取
htmls = download_all_htmls()
craw html: https://fabiaoqing.com/biaoqing/lists/page/1.html
craw html: https://fabiaoqing.com/biaoqing/lists/page/2.html
craw html: https://fabiaoqing.com/biaoqing/lists/page/3.html
craw html: https://fabiaoqing.com/biaoqing/lists/page/4.html
craw html: https://fabiaoqing.com/biaoqing/lists/page/188. 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4494
4494

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









