



1. 多表征/向量索引
为每一个文档块生成一条向量用于记录该文本的特征信息,如果能从多个维度记录该文档块的信息,会大大增加该文档块被检索到的概率,多个维度记录信息 等同于为文档块生成 多个向量,支持的方法如下:
- 把文档切割成更小的块:通过检索更小的块,但是查找其父类文档(ParentDocumentRetriever)。
- 摘要:使用 LLM 为每个文档块生成一段摘要,将其和原文档一起嵌入或者代替,返回时返回原文档。
- 假设性问题:使用 LLM 为每个文档块生成适合回答的假设性问题,将其和原文档一起嵌入或者代替,返回时返回原文档。
通过这种方式可以为一个文档块生成多条特征/向量,在检索时能提升关联文档被检索到的概率,多向量检索的运行流程其实也非常简单,以 摘要文档 检索 原文档为例,运行流程图如下
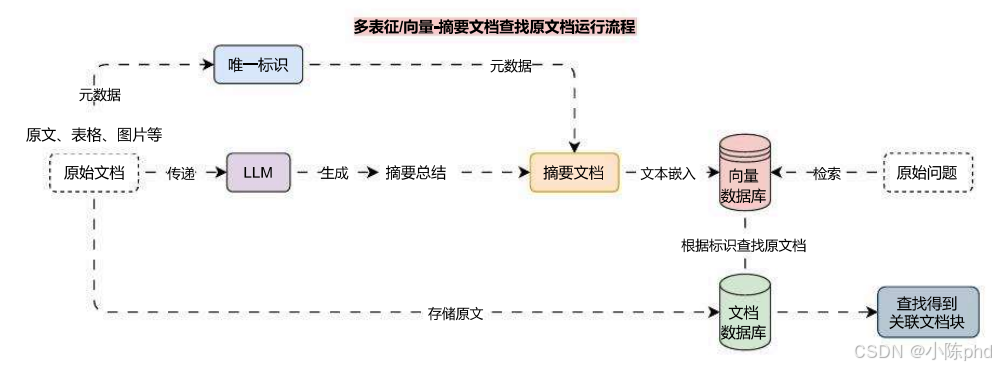
在这里插入图片描述
通过上面的运行流程,可以很容易知道在 原始文档 和 摘要文档 中都在元数据中设置了 唯一标识,从向量数据库中找到符合规则的数据后,通过查找其 元数据 的唯一标识,即可在 文档数据库 中匹配出原文档,完成整个多表征/向量的检索。
2. 多向量索引示例
在 LangChain 中,为多向量索引的集成封装了MultiVectorRetriever类,实例化该类只需要传递 向量数据库、字节存储数据库(文档数据库)、id标识(关联标识) 即可快速完成整个运行流程的集成。
以 FAISS向量数据库 和 本地文件存储库 为例,构建一个 存储摘要->检索原文 的优化策略,代码示例如下:
import uuidimport dotenvfrom langchain.retrievers import MultiVectorRetrieverfrom langchain.storage import LocalFileStorefrom langchain_community.document_loaders import UnstructuredFileLoaderfrom langchain_community.vectorstores import FAISSfrom langchain_core.documents import Documentfrom langchain_core.output_parsers import StrOutputParserfrom langchain_core.prompts import ChatPromptTemplatefrom langchain_openai import ChatOpenAI, OpenAIEmbeddingsfrom langchain_text_splitters import RecursiveCharacterTextSplitterdotenv.load_dotenv()# 1.创建加载器、文本分割器并处理文档loader = UnstructuredFileLoader("./电商产品数据.txt")text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)docs = loader.load_and_split(text_splitter)# 2.定义摘要生成链summary_chain = ( {"doc": lambda x: x.page_content} | ChatPromptTemplate.from_template("总结以下文档的内容: \n\n{doc}") | ChatOpenAI(model="gpt-3.5-turbo-16k", temperature=0) | StrOutputParser())# 3.批量生成摘要与唯一标识summaries = summary_chain.batch(docs, {"max_concurrency": 5})doc_ids = [str(uuid.uuid4()) for _ inenumerate(docs)]# 4.构建摘要文档summary_docs = [ Document(page_content=summary, metadata={"doc_id": doc_ids[idx]}) for idx, summary inenumerate(summaries)]# 5.构建文档数据库与向量数据库byte_store = LocalFileStore("./multy-vector")db = FAISS.from_documents( summary_docs, embedding=OpenAIEmbeddings(model="text-embedding-3-small"),)# 6.构建多向量检索器retriever = MultiVectorRetriever( vectorstore=db, byte_store=byte_store, id_key="doc_id",)# 7.将摘要文档和原文档存储到数据库中retriever.docstore.mset(list(zip(doc_ids, docs)))# 8.执行检索search_docs = retriever.invoke("推荐一些潮州特产?")print(search_docs)print(len(search_docs))
输出内容:
[Document(metadata={'source': './电商产品数据.txt'}, page_content='产品名称: 潮汕鱼丸\n\n电商网址: shop.example.com/fishballs\n\n产品描述: 潮汕鱼丸采用新鲜鱼肉,加入少量淀粉和调味料,手工捶打成丸,Q弹爽滑,鱼香浓郁。\n\n产品特点:\n\n原材料: 新鲜鱼肉、淀粉、盐、胡椒粉\n\n制作工艺: 传统手工捶打\n\n口感: Q弹爽滑,鲜美可口\n\n净重: 500克/袋、1000克/袋\n\n保质期: 6个月(冷冻保存)\n\n发货方式: 顺丰冷链配送,确保新鲜\n\n物流信息: 24小时内发货,预计2\n\n3天到货\n\n推荐菜系:\n\n鱼丸火锅: 搭配各类蔬菜、菌类,煮至鱼丸浮起即可。\n\n鱼丸煮汤: 与蔬菜同煮,味道鲜美。\n\n价格:\n\n500克: 55元/袋\n\n1000克: 100元/袋\n\n6. 潮汕豆腐花\n\n产品名称: 潮汕豆腐花\n\n电商网址: shop.example.com/tofupudding\n\n产品描述: 潮汕豆腐花使用优质黄豆,传统工艺制作,质地细腻,入口即化,豆香浓郁。\n\n产品特点:\n\n原材料: 黄豆、水、石膏\n\n制作工艺: 传统手工点浆\n\n口感: 细腻嫩滑,豆香浓郁\n\n净重: 450克/盒\n\n保质期: 5天(冷藏保存)'), Document(metadata={'source': './电商产品数据.txt'}, page_content='产品特点:\n\n原材料: 猪后腿肉、香料、盐、糖\n\n制作工艺: 精细切割,手工卷制\n\n口感: 鲜嫩多汁,咸香可口\n\n净重: 400克/袋、800克/袋\n\n保质期: 3个月(冷冻保存)\n\n发货方式: 顺丰冷链配送,确保新鲜\n\n物流信息: 24小时内发货,预计2\n\n3天到货\n\n推荐菜系:\n\n猪肉卷煎烤: 切片后煎至金黄,外脆里嫩。\n\n猪肉卷炖煮: 切块后与蔬菜同炖,风味更佳。\n\n价格:\n\n400克: 58元/袋\n\n800克: 108元/袋\n\n3. 潮汕三宝(酱油、甜醋、虾酱)\n\n产品名称: 潮汕三宝\n\n电商网址: shop.example.com/chaoshanthree\n\n产品描述: 潮汕三宝包含酱油、甜醋和虾酱。酱油由大豆、麦子自然发酵而成,甜醋以糯米酿制,虾酱选用新鲜海虾发酵,是潮汕菜肴必备调味品。\n\n产品特点:\n\n酱油: 大豆、麦子自然发酵,500ml/瓶\n\n甜醋: 糯米酿制,500ml/瓶\n\n虾酱: 新鲜海虾发酵,200克/瓶\n\n保质期: 酱油和甜醋12个月,虾酱6个月\n\n发货方式: 顺丰配送,确保完好\n\n物流信息: 24小时内发货,预计2\n\n3天到货\n\n推荐菜系:'), Document(metadata={'source': './电商产品数据.txt'}, page_content='口感: 鲜嫩多汁,味道浓郁\n\n净重: 500克/袋、1000克/袋\n\n保质期: 3个月(冷冻保存)\n\n发货方式: 顺丰冷链配送,确保新鲜\n\n物流信息: 24小时内发货,预计2\n\n3天到货\n\n推荐菜系:\n\n红烧狮子头: 加热后直接食用,适合作为主菜。\n\n狮子头炖菜: 与蔬菜同炖,味道更佳。\n\n价格:\n\n500克: 60元/袋\n\n1000克: 110元/袋\n\n10. 潮汕香菇肉酱\n\n产品名称: 潮汕香菇肉酱\n\n电商网址: shop.example.com/mushroomsauce\n\n产品描述: 潮汕香菇肉酱采用香菇和猪肉为主要原料,加入特制酱料炒制而成,香气扑鼻,味道鲜美。\n\n产品特点:\n\n原材料: 香菇、猪肉、酱料\n\n制作工艺: 精细切割,炒制均匀\n\n口感: 鲜香可口,酱香浓郁\n\n净重: 200克/瓶、400克/瓶\n\n保质期: 6个月(常温保存)\n\n发货方式: 顺丰配送,确保完好\n\n物流信息: 24小时内发货,预计2\n\n3天到货\n\n推荐菜系:\n\n拌饭: 加入米饭中,提升口感。\n\n拌面: 加入面条中,风味独特。\n\n价格:\n\n200克: 35元/瓶\n\n400克: 65元/瓶'), Document(metadata={'source': './电商产品数据.txt'}, page_content='口感: 细腻嫩滑,豆香浓郁\n\n净重: 450克/盒\n\n保质期: 5天(冷藏保存)\n\n发货方式: 顺丰冷链配送,确保新鲜\n\n物流信息: 24小时内发货,预计2\n\n3天到货\n\n推荐菜系:\n\n甜食: 加糖水、红豆、芝麻食用。\n\n咸食: 加入虾米、葱花、酱油食用。\n\n价格: 25元/盒\n\n7. 潮汕鱼露\n\n产品名称: 潮汕鱼露\n\n电商网址: shop.example.com/fishsauce\n\n产品描述: 潮汕鱼露以新鲜小鱼为原料,经过发酵、过滤而成,味道鲜美,是潮汕菜肴必备调味品。\n\n产品特点:\n\n原材料: 小鱼、盐\n\n制作工艺: 自然发酵,传统工艺\n\n口感: 鲜美咸香\n\n净重: 500ml/瓶\n\n保质期: 12个月\n\n发货方式: 顺丰配送,确保完好\n\n物流信息: 24小时内发货,预计2\n\n3天到货\n\n推荐菜系:\n\n凉拌菜: 作为调味料使用,提升菜肴鲜味。\n\n炒菜: 适合炒菜提鲜。\n\n价格: 38元/瓶\n\n8. 潮汕糯米肠\n\n产品名称: 潮汕糯米肠\n\n电商网址: shop.example.com/glutinousrice')]
除了使用 摘要 来检索全文,多向量检索一般还适用于 子文档检索父文档和 假设性查询检索,其中 假设性查询检索 是利用 LLM 对切块后的文档生成多个 假设性标题,在向量数据库中存储 假设性标题 文档块,使用检索到的数据查找 原始文档。
核心代码修正如下
from typing importListimport dotenvfrom langchain_core.documents import Documentfrom langchain_core.prompts import ChatPromptTemplatefrom langchain_core.pydantic_v1 import BaseModel, Fieldfrom langchain_openai import ChatOpenAIdotenv.load_dotenv()classHypotheticalQuestions(BaseModel): """生成假设性问题""" questions: List[str] = Field( description="假设性问题列表,类型为字符串列表", )# 1.构建一个生成假设性问题的promptprompt = ChatPromptTemplate.from_template("生成一个包含3个假设性问题的列表,这些问题可以用于回答下面的文档:\n\n{doc}")# 2.创建大语言模型,并绑定对应的规范化输出结构llm = ChatOpenAI(model="gpt-3.5-turbo-16k", temperature=0)structured_llm = llm.with_structured_output(HypotheticalQuestions)# 3.创建链应用chain = ( {"doc": lambda x: x.page_content} | prompt | structured_llm)hypothetical_questions: HypotheticalQuestions = chain.invoke( Document(page_content="我叫慕小课,我喜欢打篮球,游泳"))print(hypothetical_questions)
输出内容
questions=['如果你不能打篮球,你会选择什么运动?', '如果你不能游泳,你会选择什么运动?', '如果你不能进行任何体育运动,你会选择什么爱好?']
接下来针对每个文档生成的 假设性查询 创建 Document列表,并添加 doc_id,添加到向量数据库中,并将 doc_id 与原始文档进行绑定,存储到 文档数据库/字节数据库 即可。
如何高效转型Al大模型领域?
作为一名在一线互联网行业奋斗多年的老兵,我深知持续学习和进步的重要性,尤其是在复杂且深入的Al大模型开发领域。为什么精准学习如此关键?
- 系统的技术路线图:帮助你从入门到精通,明确所需掌握的知识点。
- 高效有序的学习路径:避免无效学习,节省时间,提升效率。
- 完整的知识体系:建立系统的知识框架,为职业发展打下坚实基础。
AI大模型从业者的核心竞争力
- 持续学习能力:Al技术日新月异,保持学习是关键。
- 跨领域思维:Al大模型需要结合业务场景,具备跨领域思考能力的从业者更受欢迎。
- 解决问题的能力:AI大模型的应用需要解决实际问题,你的编程经验将大放异彩。
以前总有人问我说:老师能不能帮我预测预测将来的风口在哪里?
现在没什么可说了,一定是Al;我们国家已经提出来:算力即国力!
未来已来,大模型在未来必然走向人类的生活中,无论你是前端,后端还是数据分析,都可以在这个领域上来,我还是那句话,在大语言AI模型时代,只要你有想法,你就有结果!只要你愿意去学习,你就能卷动的过别人!
现在,你需要的只是一份清晰的转型计划和一群志同道合的伙伴。作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。

第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
- 硬件选型
- 带你了解全球大模型
- 使用国产大模型服务
- 搭建 OpenAI 代理
- 热身:基于阿里云 PAI 部署 Stable Diffusion
- 在本地计算机运行大模型
- 大模型的私有化部署
- 基于 vLLM 部署大模型
- 案例:如何优雅地在阿里云私有部署开源大模型
- 部署一套开源 LLM 项目
- 内容安全
- 互联网信息服务算法备案
- …
学习是一个过程,只要学习就会有挑战。天道酬勤,你越努力,就会成为越优秀的自己。
如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名大模型 AI 的正确特征了。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









