



麻省理工的一份最新报告显示,约 95% 的企业在实施 AI 后并未获得实际商业回报。事实上,我们也常见到一些 AI 项目“Demo 很惊艳,上线后无人问津”。问题究竟在哪?我们将从企业级 AI 应用的真实场景切入,并通过一个Demo构建,探讨 AI 在数据层的真正需求,以及企业应如何构建合适的数据底座来支撑真实的 AI 应用。
- 问题:超预期的真实业务需求
- 思考:当向量遇到企业应用的天花板
- 实战:构建一个多模态混合检索Agent
- 扩展:传统方案并未消失
- 结语:构建一体化的AI数据底座
01 问题:超预期的真实业务需求
AI在企业应用的不尽如人意,不仅在于工程上的高要求;也在于开发者往往容易沉浸于某些技术细节,却忽视真实场景的复杂性。
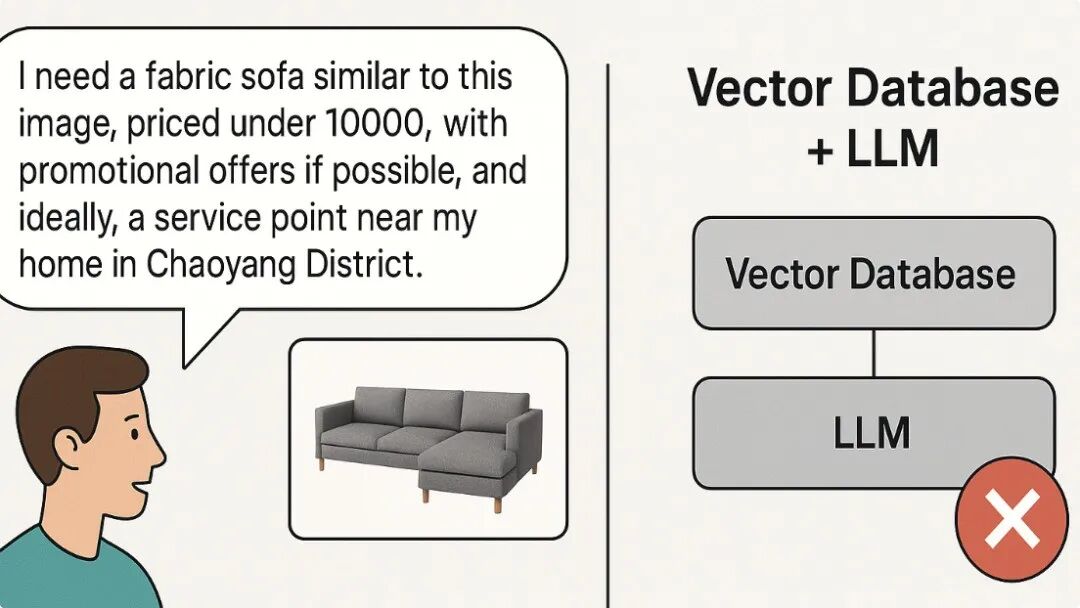
以看似简单的AI咨询为例,用户的需求远非“产品有什么特点”或“如何退换货”这样的单维问题,靠着“知识库+向量+LLM”可以轻松解决。而实际情况可能是:
“有没有类似图片这种的布艺沙发,价格低于8000,适合女生。我在朝阳区,附近最好有销售点,想去体验下。”
再比如:
“找到北京地区近三个月购买过家居类产品,最近的投诉内容里涉及配送问题;优先推荐在我们现有库存量大的 SKU 上投放优惠券。”
这类请求融合了向量相似(理解图片、“适合女生”)、关键词(“配送问题”)、数值精确过滤(价格)、位置约束(附近有销售点)、甚至个性化信息(购买过xx产品)等。现在请回想:你正在建设的RAG或者Agent应用能否支持这样的对话?
问题的瓶颈并不在LLM,更不是向量数据库。而是:
企业AI应用的大量场景从来都不是孤立(查询一个财务政策、保修条款、创作一封邮件)的,更多的是与企业的业务紧密联系,这体现在应用、流程与数据多个层面。
所以,企业真实应用场景的复杂性远超我们的想象。我们必须意识到:

- 数据的多样性是常态
-
产品有图片、文字、参数、评价、宣传视频
-
交易有金额、时间、地点、关联商品、满意度
-
用户有基本信息、行为、社交关系、客户画像
- 查询的复杂性是必然
-
语义相似+价格区间+地理位置
-
图像匹配+库存状态+用户偏好
-
关键词搜索+时间范围+关联推荐
- 应用的融合性是趋势
-
用户的行为会实时影响到AI推荐结果
-
价格、宣传物料的更新实时反映到AI搜索结果
-
AI应用的交互信息会实时的影响用户的画像
02 思考:当向量遇到企业级应用的天花板
以上的问题和案例都暴露了当前很多以数据为中心的AI应用的一些核心痛点:
- 新的AI数据“孤岛”
企业生产中不仅有大量非结构化文本,还有丰富的结构化信息(往往是核心生产数据),它们往往需要关联使用。比如一个企业的“产品”相关的信息:
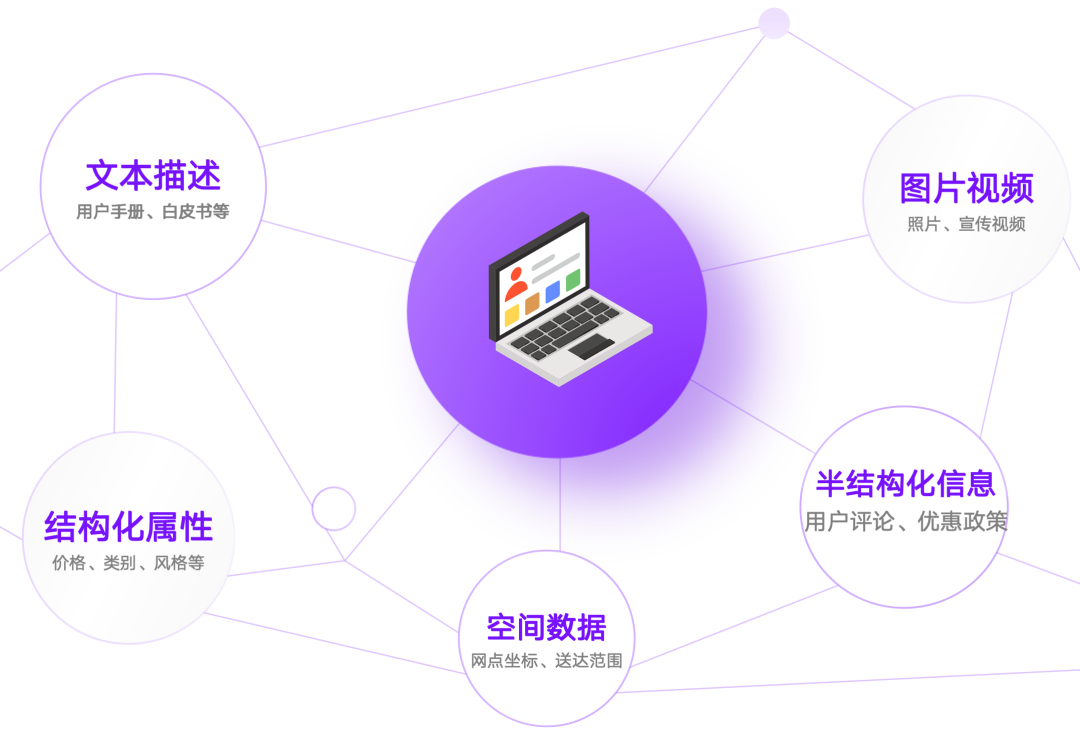
AI时代,我们擅长将非结构化文本存入向量库,比如用户手册、常见问答等;而产品的价格、类别、库存、参数等留在传统RDBMS/文档数据库。一个显然的问题是:数据同步与维护复杂、低效、代价大,更可能涉及复杂的分布式事务等问题。
现有以向量为核心的RAG应用仍然是面向文本为主,在客户提供参考图片或其他非文本时往往捉襟见肘,常见方案是借助图片嵌入模型,并需要开发框架的支持。如果能够将图像、音频、视频等多模向量,与非结构化文本向量统一存储与检索,就可以更方便的实现跨模态关联,减少在应用层的”粘合开发“工作。
- 单一的检索维度
各种类型数据的割裂带来了检索能力的单一,但真实场景中的检索往往是“混合”型的。在割裂的数据层中实现混合检索,不仅是处理流程上的复杂,更在于不统一的检索接口或查询语言。比如:结构化过滤使用SQL;而到了语义检索则使用向量库的API - 这取决于不同的产品实现。
当前应对混合检索的常见方法:
-
多种检索方法组合使用。比如先用结构化条件筛选,再用向量做语义匹配与排序(也可以反过来)。这种方法既麻烦且性能低下。
-
一些优秀的向量库也支持元数据过滤等筛选。比如:查找“xx类别”下语义近似“xxxx”的块。不过更适合轻量级场景,且元数据大小有限制。
-
完全在应用层实现拼接:分别检索后由应用做合并、去重和排序。
【方案:多模态的融合AI数据层】
源自于数据的不可复制性、价值积累性以及业务依赖性,破解这些核心痛点以释放AI潜力的技术关键或许仍然是数据层:一体化的AI融合数据层,提供面向多模态、多负载的统一数据存储、检索与更新,从而极大的简化上层应用架构,开发者可以更专注在业务需求的满足,而非技术层面的“粘合”工作。
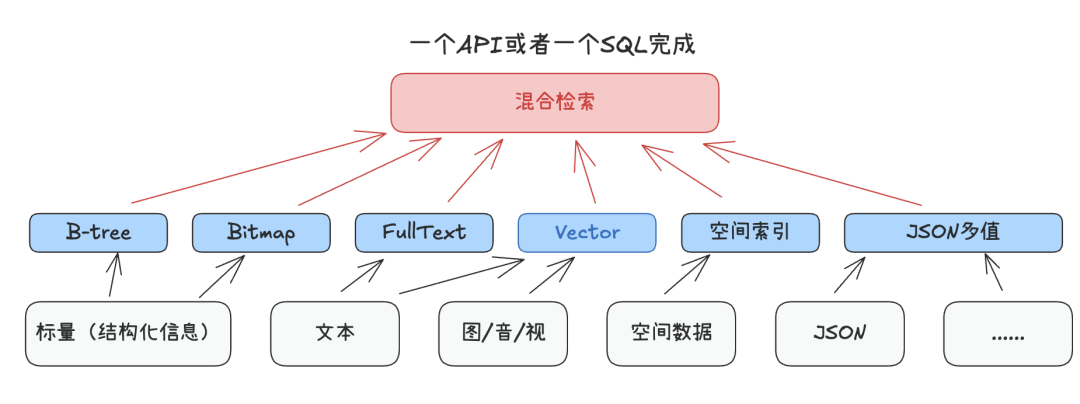
这可以显著改善以下能力:
- 多模态统一数据支持:多种模态的数据可以更一致的存储并创建混合索引。
- 融合的数据应用能力:多类型索引、混合检索、简化数据同步、提高性能。
- 简化系统架构与运维:更易于统一的架构设计、性能优化、分布式扩展等。
03 实战:构建一个多模态混合检索Agent
为了更直观地理解“多模态融合AI数据层”的方案与价值,我们来动手构建一个基于真实场景的完整Demo。
【场景设计】
假设一个家居产品(如沙发)的销售企业,在多个渠道部署了AI产品推荐与咨询的机器人。用户可以与AI展开可能的连续对话,比如:
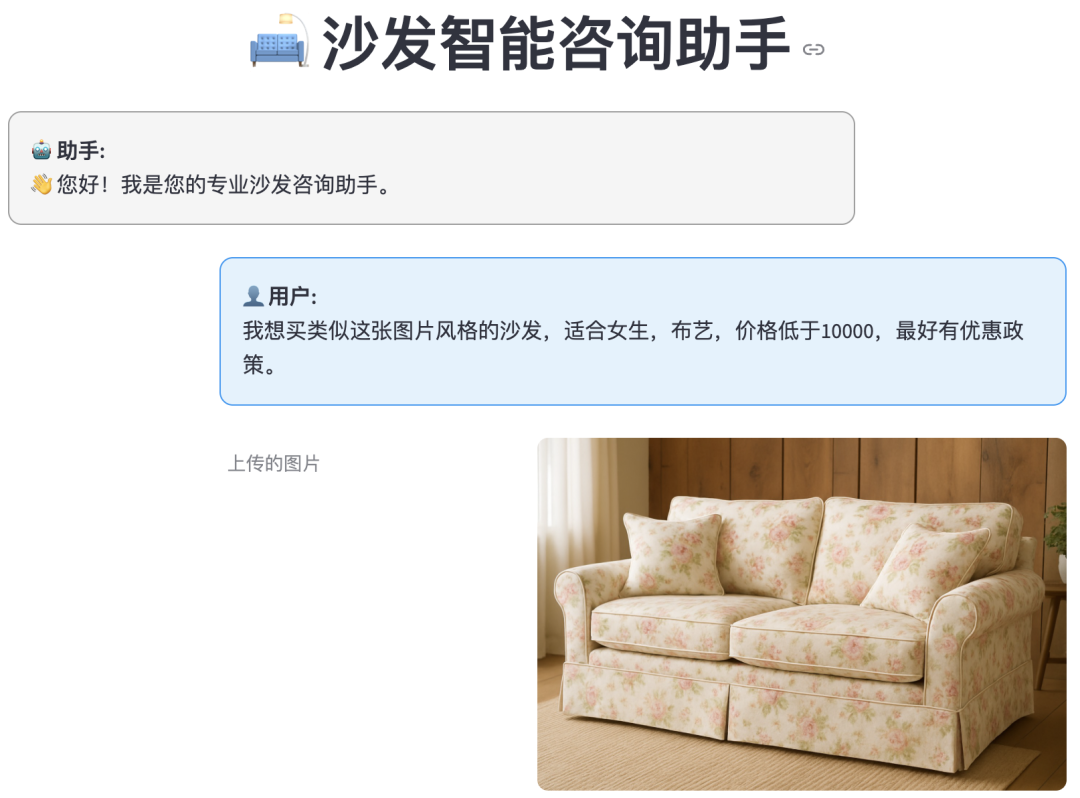
“我想买类似这张图片风格的沙发,适合女生,布艺,价格低于10000,最好有优惠政策。【上传了参考图片】”
“推荐的这款产品维护保养能否详细介绍下?
“我之前买过你们一款沙发,很不错,想再买一个大点,但是样子差不多的”
【工具选择】
技术选型如下:
- 开发框架:LangGraph,用来更灵活的实现AI应用工作流
- 融合AI数据层:OceanBase(OB Cloud实例)
- LLM模型:通义千问
- 嵌入模型:阿里text-embedding-v3/multimodal-embedding-v1
这里核心的融合数据层选择了国产的分布式数据库OceanBase最新社区版来构建:可以很好的支持结构化、JSON、向量、空间等统一数据的存储,并提供了简洁一致的访问接口(SQL&内部算法函数&API库)。你可以选择使用社区版或OceanBase Cloud上的免费实例来完成Demo(对于生产级应用,企业版应是最佳选择)。
【方案设计】
如上文分析,这些常见的真实场景咨询用简单的知识库与RAG是很难应对的。要么无法实现,要么效果不佳。当然,你可能会想到借助Agentic RAG:针对多数据源建立多个检索Pipeline,再借助应用层Workflow来处理。不过复杂性较高,且可能会产生大量的胶水代码。
Demo的方案如下:
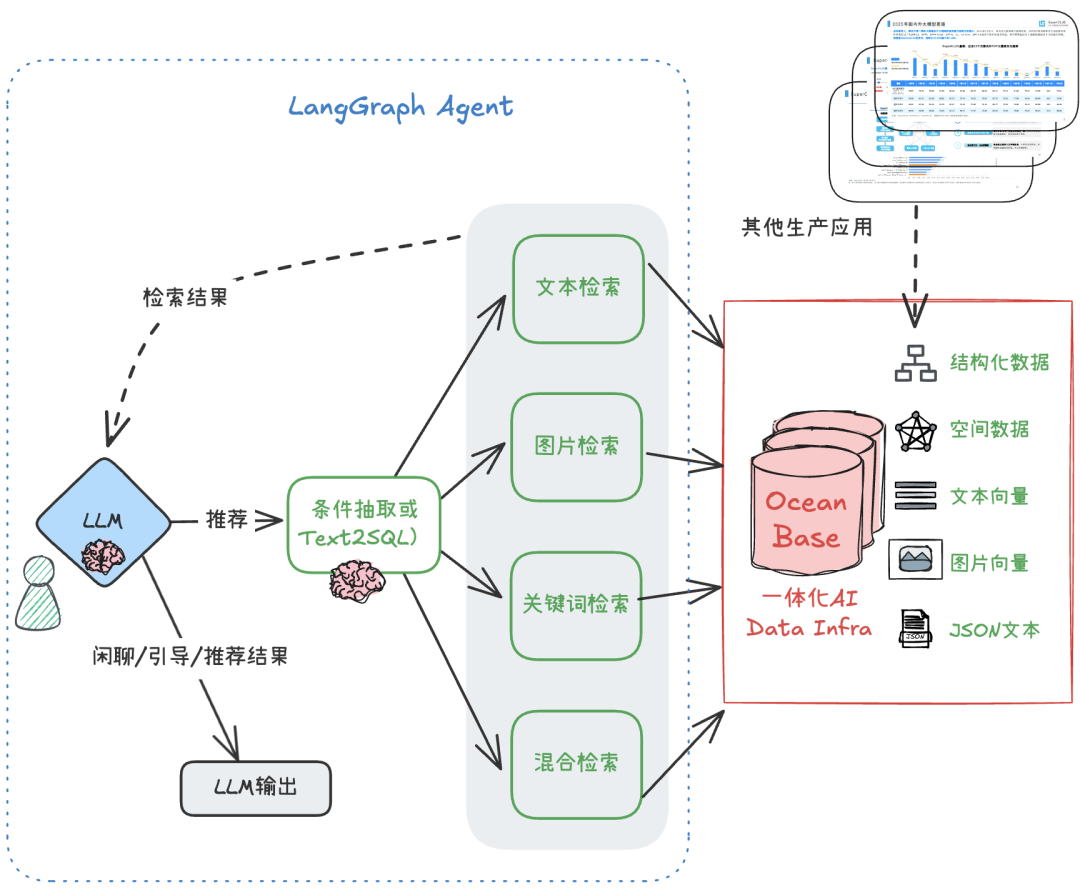
本方案的核心有两个:
- 一个融合的AI数据层:不再需要其他独立的RDBMS或向量库。
- 一个灵活的AI应用层:采用LangGraph框架构建应用工作流,整合检索工具。
【关键实现】
- 混合检索
借助OceanBase(打开向量支持)的统一接口与语言(SQL)来方便的实现混合检索。以下是一个例子:
SELECT cosine_distance(p.image_vector, [参考图片的vector]) as similar_score_image, cosine_distance(p.description_vector, [查询自然语言的vector]) as similar_score_text,...from products pwhere style='布艺' and price<=10000 and cast(JSON_UNQUOTE(JSON_EXTRACT(promotion_policy, '$.discount')) AS DECIMAL(3,1)) < 9.0 andst_dwithin(address, ST_GeomFromText(...),20)order by similar_score_image ASClimit3
在这个模拟检索中融合了结构化属性检索(价格)、文本/图片相似度(cosine_distance计算与排序)、JSON属性过滤(JSON_EXTRACT)、空间数据过滤(st_dwithin)。相对于单一的向量库,这种方式依托于强大的SQL,可以满足极其灵活与复杂的检索需求。
这里的难点是:如何动态的根据客户自然语言生成检索语句?毕竟单纯的向量检索可以输入任意文本,而SQL是一种有着严格语法的查询语言。
可以考虑两种方法:
借助LLM生成,即广为所知的Text2SQL。考虑混合检索本身具有较大的复杂性,在实际应用中你需要精心设计Prompt(提供样例和数据结构)来提高生成准确性,否则容易出错;另一种是针对你的数据层微调专用的SLM(小模型)。
LLM的条件推理+代码组装。这也是我们Demo中使用的方式:

- 抽取检索条件:从用户的自然语言输入和上下文推理检索条件。比如:

借助于现在的LLM和few-shot Prompt,这种抽取可以达到极高的准确性。
-
检索条件校验:对推理出来的条件进行校验,这里可以做设定:比如有的条件必须提供,有的条件可以选择性;并根据抽取结果决定是继续检索,还是反馈客户(要求提供更多信息)。
-
生成混合检索语句:有了检索条件,生成混合检索语句只是简单的拼装工作(实际应用中要充分考虑索引利用、SQL缓存等更多性能问题)。代码参考(部分):
def _vector_search(self, embedding: List[float], filters: Dict[str, Any] = None, search_type: str = 'text') -> List[Dict]: try: # 根据搜索类型选择向量字段 vector_column = 'description_vector' if search_type == 'text'else'image_vector' # 构建基础查询语句 base_query = f""" SELECT id, name, description, material, style, price, size, color, brand, service_locations, features, dimensions, promotion_policy, image_url, cosine_distance({vector_column}, '{embedding}') as similarity FROM {self.table_name} """ # 添加过滤条件 conditions = [] if filters: # 材质过滤 if filters.get(self.material_name): conditions.append(f"material LIKE '%{filters[self.material_name]}%'") #.......省略:添加其他过滤条件......... # 组合查询语句 if conditions: base_query += " WHERE " + " AND ".join(conditions) base_query += f" ORDER BY similarity ASC LIMIT {self.topk}" # 执行查询 results = self.client.perform_raw_text_sql(base_query)......
- 工作流与Prompts设计
为了更好的控制流程,没有直接使用预置的ReAct Agent,而是自定义了LangGraph工作流,大致逻辑为:
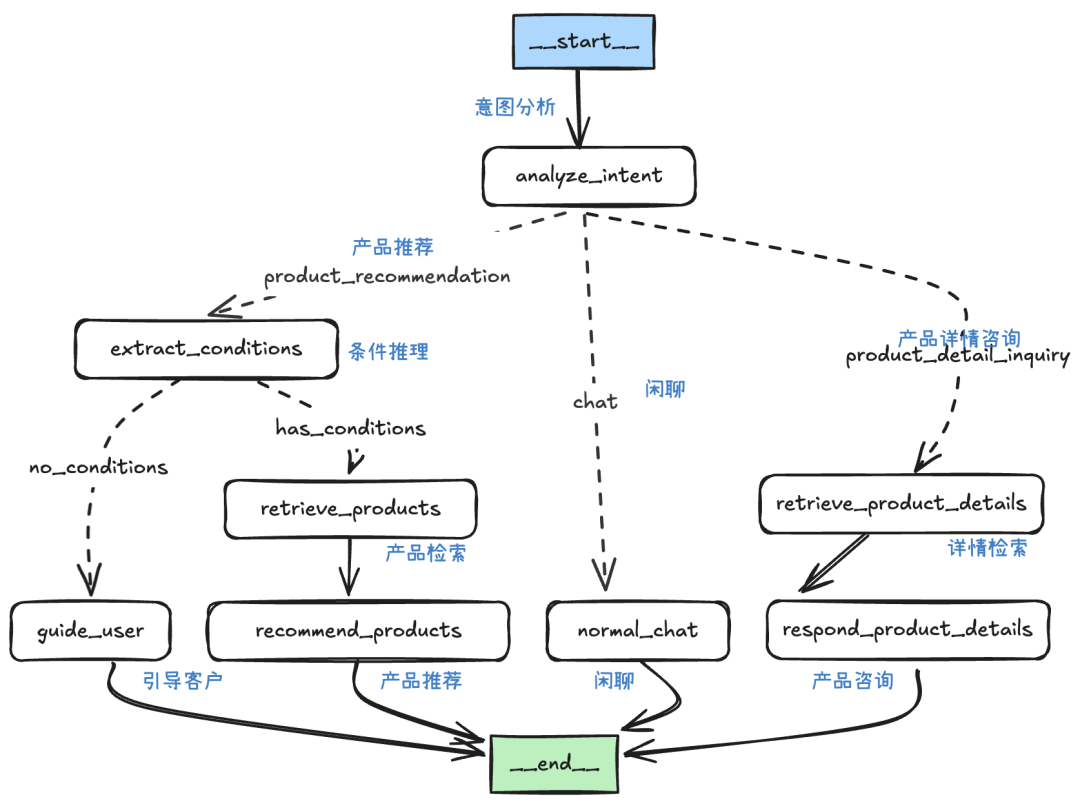
这里我们重点实现产品推荐和详情咨询,以演示真实场景中的混合检索需求。
Demo中涉及到的重点Prompt有:
- 客户意图识别:主要目的是分理出复杂的产品推荐/咨询意图以做精准处理。
- 过滤条件抽取:抽取自然语言中的各种标量和向量过滤条件并结构化输出。
其他的闲聊、引导、最后的推荐结果生成等可根据需要自行设计Prompt。
【测试效果】
最后,让AI帮忙写一个简单的streamlit UI,以测试我们的Agent:
查看Agent的处理过程:
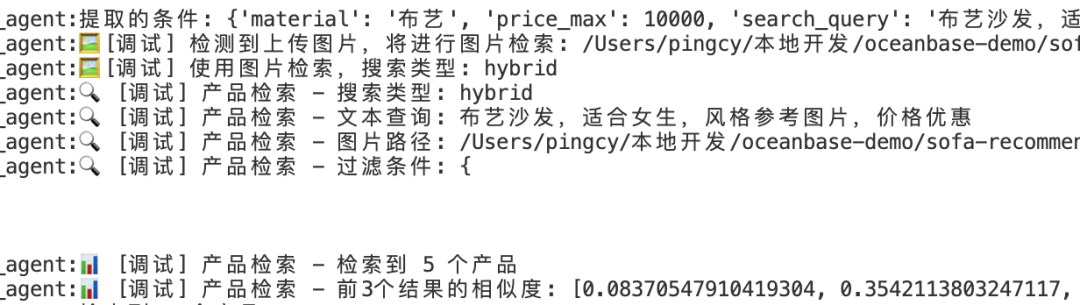
可以看到,Agent借助LLM提取了结构化的查询条件,同时也借助图片和文本的向量相似度进行了筛选排序,最终返回多个产品信息。LLM整理后做图文输出:


对这个Demo做简单改造即可进一步增加对空间数据(POINT、POLYGON等类型)、半结构化数据(JSON类型)的融合检索能力,以覆盖更多复杂业务场景(比如基于位置的附近网点咨询、旅游规划等)。
04 扩展:传统方案并未消失
上面的案例展示了在融合的AI数据层上的多模态混合检索能力:一种技术、一套API、一条语句,可以同时展开多模态、多条件、多索引的数据检索。
但注意,这里的数据层是可以完全兼容传统知识库型RAG应用的需求的。
你应该注意到上述Demo的工作流中,有一条分枝用于处理客户进一步的产品详情咨询:了解某个推荐产品的手册/白皮书文档中的部分内容。我们把这些文档用经典RAG的方法进行拆分(Split)、嵌入(Embedding)、存储成向量,并与产品、原始文档、文本内容关联存放到OceanBase中即可。
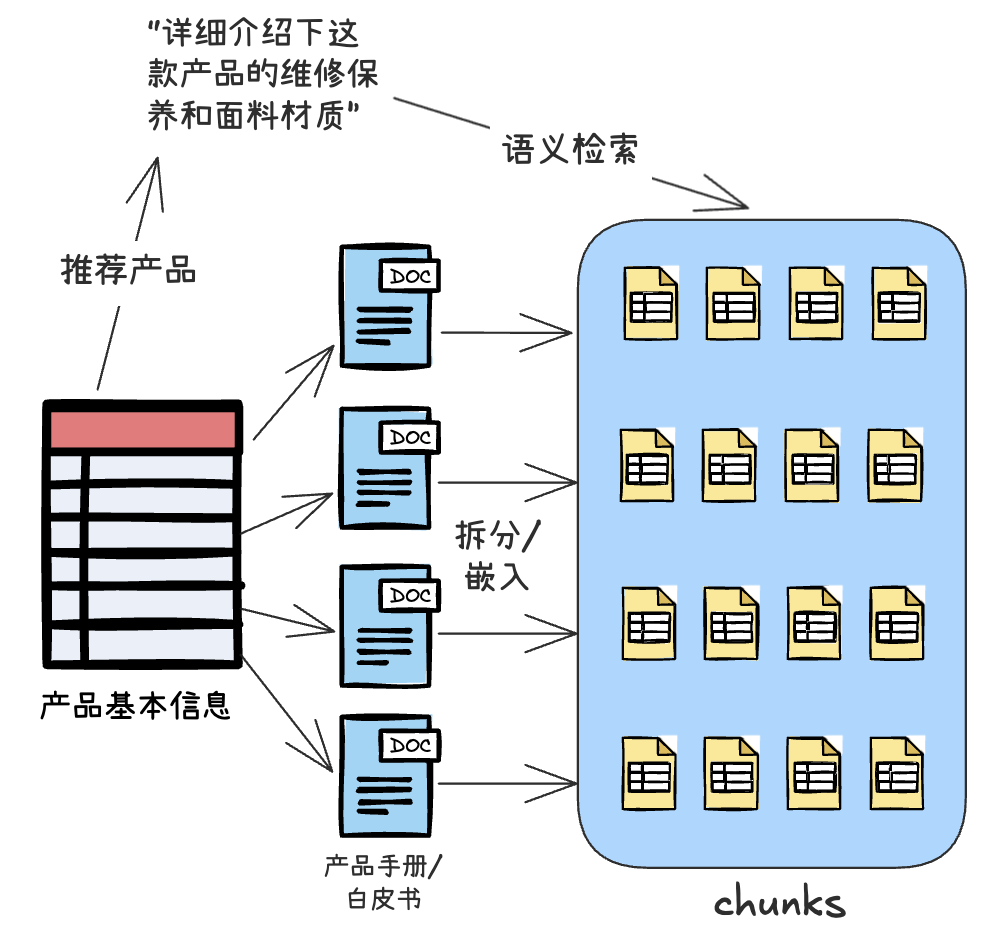
剩下就很简单,用推荐产品和用户输入做条件直接检索即可:
SELECT ......检索的字段......
cosine_distance(pd.chunk_vector, ?) as similarity_score
FROM products p
LEFT JOIN products_docs pd ON p.id = pd.product_id
WHERE p.id = ?
AND pd.chunk_vector IS NOT NULL
AND pd.chunk_content IS NOT NULL
HAVING similarity_score <= 0.8 -- 只返回相似度高于某个阈值的结果
ORDER BY similarity_score ASC
LIMIT 3;
可以看到,数据关联、相似度判断、甚至调试检查都会更简洁与“优雅”。
看下测试效果:
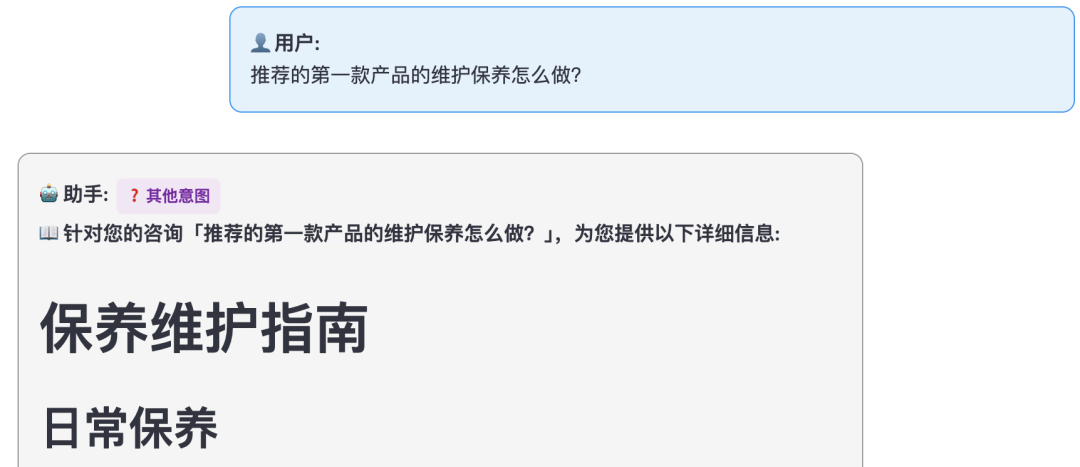
Agent后台的跟踪信息:

如果你暂时只需要构建简单的知识库RAG,但又希望预留未来的扩展能力。还有两种更简洁的方式:
-
LlamaIndex/LangChain/Dify等框架+OceanBase
诸如LlamaIndex/LangChain/Dify这些常见的主流开发框架或平台都支持让OceanBase作为AI数据层的选择,以保留面向未来的高度扩展性。
-
借助OB Cloud 的PowerRAG数据应用开发平台
如果你使用云端的OceanBase实例,可以借助OceanBase的PowerRAG - 官方一站式的RAG应用低代码开发平台。可以通过简单的知识库上传快速构建属于自己的RAG应用(目前还是预览版,更多的功能在完善中):
05 结语:一体化的AI数据底座引领未来方向
上文的Demo很好的展示了一体化融合AI数据层的价值与收益:
- 架构极简与技术栈统一
关系库、全文检索、向量库合一,减少组件数量与跨系统粘合代码;应用仅对接一种协议与驱动、一套工具链,开发、维护与升级的复杂性都得以下降。
- 单条“语句”实现混合检索
在一条 SQL/API中同时执行属性过滤、向量相似度排序,还可以结合空间数据、全文检索、JSON抽取等。避免多段式开销,减少跨系统查询与搬运。
- 相关性与精确性提升
结合传统数据库索引 + 关键词过滤 + 语义检索的联合计划,兼顾标量匹配与向量相似,减少传统方案里“结果不够 K 条”或“语义相关但条件不满足”的两难。
- 一致性与数据实时性更好
结构化字段与多模态向量共处同一事务域,可以实现数据更新天然的一致,避免异步同步导致的“新旧不一”和读写延迟等问题(很多场景中会影响用户体验)。
- 更好的企业级可用性、性能与扩展性
融合AI数据层以传统RDBMS的扩展为主,这恰恰可以让AI应用充分利用传统数据库更成熟的企业级特性:高可用性、高性能、海量数据及扩展性。
最后的思考:融合AI数据底座,传统RDBMS的新机会?
融合AI数据层解决方案由于需要兼顾多种数据形态、负载类型、融合业务,并不是把“向量库 + 关系库 + 搜索引擎”简单拼装,而是要在同一内核内把多种数据与索引类型(标量、全文、JSON、空间、向量)纳入统一的设计与优化器,并在事务、分布式处理、资源调度、性能优化、容灾、治理等多方面实现一体化。
显然,这是一项复杂的系统工程。有更强的企业级IT基建能力的传统RDBMS供应商的长期积累使其更有条件把向量等能力“吃进内核”,实现真正一体化的面向AI的数据“底座”。
或许这也是传统数据库厂商在AI时代转型的必然方向之一,甚至是像OB这样的国产数据库在AI时代弯道超车的重要机会。
如何学习大模型 AI ?
我国在AI大模型领域面临人才短缺,数量与质量均落后于发达国家。2023年,人才缺口已超百万,凸显培养不足。随着Al技术飞速发展,预计到2025年,这一缺口将急剧扩大至400万,严重制约我国Al产业的创新步伐。加强人才培养,优化教育体系,国际合作并进,是破解困局、推动AI发展的关键。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

2025最新大模型学习路线
明确的学习路线至关重要。它能指引新人起点、规划学习顺序、明确核心知识点。大模型领域涉及的知识点非常广泛,没有明确的学习路线可能会导致新人感到迷茫,不知道应该专注于哪些内容。
对于从来没有接触过AI大模型的同学,我帮大家准备了从零基础到精通学习成长路线图以及学习规划。可以说是最科学最系统的学习路线。

针对以上大模型的学习路线我们也整理了对应的学习视频教程,和配套的学习资料。
大模型经典PDF书籍
新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路!

配套大模型项目实战
所有视频教程所涉及的实战项目和项目源码等

博主介绍+AI项目案例集锦
MoPaaS专注于Al技术能力建设与应用场景开发,与智学优课联合孵化,培养适合未来发展需求的技术性人才和应用型领袖。


这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

为什么要学习大模型?
2025人工智能大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。

适合人群
- 在校学生:包括专科、本科、硕士和博士研究生。学生应具备扎实的编程基础和一定的数学基础,有志于深入AGI大模型行业,希望开展相关的研究和开发工作。
- IT行业从业人员:包括在职或失业者,涵盖开发、测试、运维、产品经理等职务。拥有一定的IT从业经验,至少1年以上的编程工作经验,对大模型技术感兴趣或有业务需求,希望通过课程提升自身在IT领域的竞争力。
- IT管理及技术研究领域人员:包括技术经理、技术负责人、CTO、架构师、研究员等角色。这些人员需要跟随技术发展趋势,主导技术创新,推动大模型技术在企业业务中的应用与改造。
- 传统AI从业人员:包括算法工程师、机器视觉工程师、深度学习工程师等。这些AI技术人才原先从事机器视觉、自然语言处理、推荐系统等领域工作,现需要快速补充大模型技术能力,获得大模型训练微调的实操技能,以适应新的技术发展趋势。

课程精彩瞬间
大模型核心原理与Prompt:掌握大语言模型的核心知识,了解行业应用与趋势;熟练Python编程,提升提示工程技能,为Al应用开发打下坚实基础。
RAG应用开发工程:掌握RAG应用开发全流程,理解前沿技术,提升商业化分析与优化能力,通过实战项目加深理解与应用。
Agent应用架构进阶实践:掌握大模型Agent技术的核心原理与实践应用,能够独立完成Agent系统的设计与开发,提升多智能体协同与复杂任务处理的能力,为AI产品的创新与优化提供有力支持。
模型微调与私有化大模型:掌握大模型微调与私有化部署技能,提升模型优化与部署能力,为大模型项目落地打下坚实基础。




顶尖师资,深耕AI大模型前沿技术
实战专家亲授,让你少走弯路

一对一学习规划,职业生涯指导
- 真实商业项目实训
- 大厂绿色直通车
人才库优秀学员参与真实商业项目实训
以商业交付标准作为学习标准,具备真实大模型项目实践操作经验可写入简历,支持项目背调
大厂绿色直通车,冲击行业高薪岗位


文中涉及到的完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









