




CSS偏移反爬虫,利用爬虫程序无法渲染css,但是浏览器能渲染css的特性设计出来的反爬虫手段
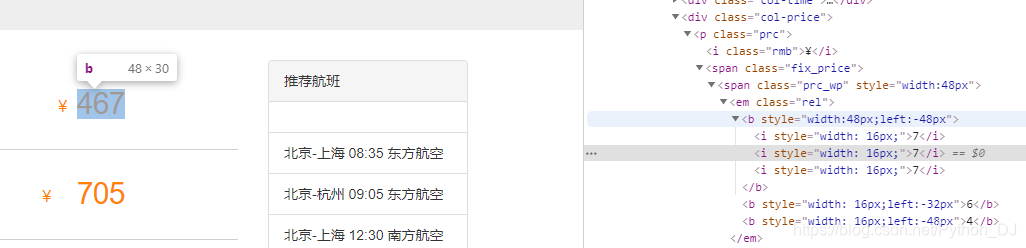
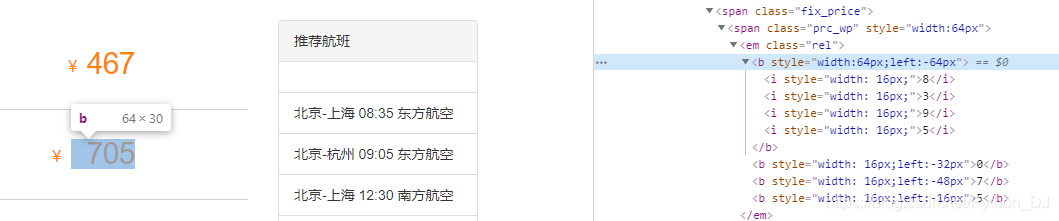
上面的网页信息,页面显示的内容和实际的HTML文档不一样,这样爬虫就不能拿到准确的数据,因为网页显示数据不仅使用来i标签的数据,也使用来b标签的数据
观察发现:没有i标签的b标签都有一个left属性,利用left的值来做偏移,覆盖掉i标签中的数据
import requests
import re
from parsel import Selector
url = "http://www.porters.vip/confusion/flight.html"
resp = requests.get(url)
sel = Selector(resp.text)
em = sel.css("em.rel").extract() # 定位到所有的em标签
# 提取数据
for element in em:
element = Selector(element)
# 定位所有b标签
element_b = element.css("b").extract()
b1 = Selector(element_b.pop(0)) # 删除0号元素,并返回0号元素
# print(element)
# print(element_b)
# print(b1)
# 获取第一对b标签中的值(列表)
# base_price = b1.css("i::text").extract() # - 需要删减的行
b1_style = b1.css("b::attr('style')").get() # + 需要添加的行
# 获得具体的位置
b1_width = "".join(re.findall("width:(.*)px;", b1_style))
number = int(int(b1_width) / 16)
# 取第一对b标签中的值(列表)
print(number)
base_price = b1.css("i::text").extract()[:number]
# print(base_price)
# 提取其他b标签的偏移值和数字
alternate_price = []
for eb in element_b:
eb = Selector(eb)
# 提取style属性
style = eb.css("b::attr('style')").get()
# print(style)
# 获取具体的位置
position = "".join(re.findall("left:(.*)px", style))
# print(position)
# 获得该标签下的数字
value = eb.css("b::text").get()
# 将b标签的位置信息和数字以字典的格式添加到替补票价列表中
alternate_price.append({"position": position, "value": value})
# 然后根据偏移量决定基准数据列表的覆盖元素
for al in alternate_price:
position = int(al.get("position"))
value = al.get("value")
# 判断位置的数值是否为正数
plus = True if position >= 0 else False
# 计算下标,以16px为基准
index = int(position / 16)
# 替换第一对b标签里面的值,也就是完成值覆盖操作
base_price[index] = value
print(base_price)
# 输出结果中第一组正常,第二组不同,因为第二个基准数据值有4个值
# 覆盖操作是根据偏移量计算得出的下标进行的,实际上就是列表元素的替换,当基准值的元素数量
# 超过实际的宽度时就进行切片,有时候网页显示错误也是正常的情况
# print(em)
# 总结:
# 首先需要几个基准值,就是单个字符偏移的值,是一个常数的倍数
# 拿到每个数据的偏移量,与基准值做商
# 以商为列表索引,替换列表里面的数据

















 677
677

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









