 Python正则表达式:单字符匹配与实例,
Python正则表达式:单字符匹配与实例,





 本文介绍了如何使用Python的正则表达式进行单字符匹配,如查找数字、特殊字符和英文字母。通过示例展示了账户、QQ号和邮箱的匹配规则,总结了正则表达式的应用方法。
本文介绍了如何使用Python的正则表达式进行单字符匹配,如查找数字、特殊字符和英文字母。通过示例展示了账户、QQ号和邮箱的匹配规则,总结了正则表达式的应用方法。
一、单字符匹配
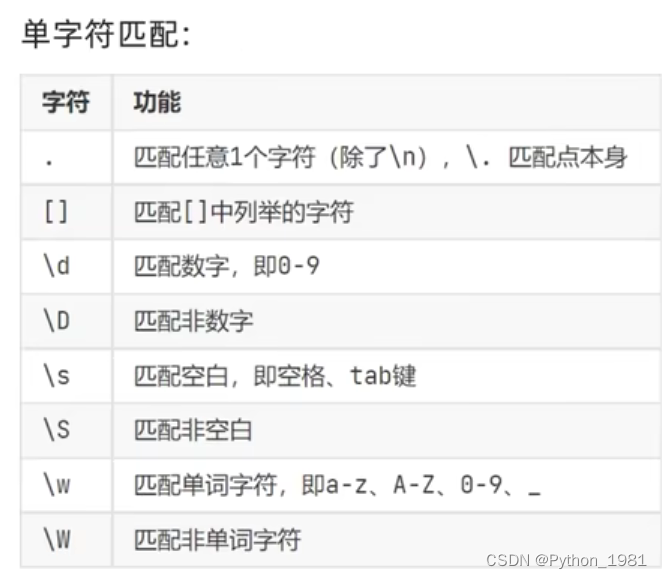
简单应用

1、找出全部数字
代码演示:
"""
正则表达式使用元字符进行匹配
"""
import re
s="dsf 231df#@##$hhrh/,ywd56156g62"
# 字符串前带上r标记,表示字符串中转义字符无效,是普通字符
result=re.findall(r"\d",s)
print(result)
运行结果:
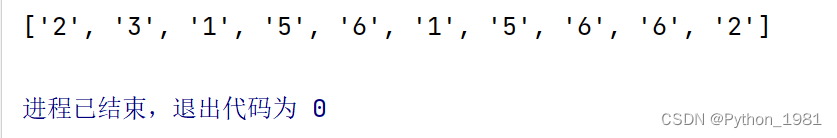
2、找出特殊字符
代码演示:
"""
正则表达式使用元字符进行匹配
"""
import re
s="dsf 231df#@##$hhrh/,ywd56156g62"
# 字符串前带上r标记,表示字符串中转义字符无效,是普通字符
result=re.findall(r"\W",s)
print(result)
运行结果:

3、找出全部英文字母
代码演示:
"""
正则表达式使用元字符进行匹配
"""
import re
s="dsf 231df#@##$hhrh/,ywd56156g62"
# 字符串前带上r标记,表示字符串中转义字符无效,是普通字符
result=re.findall(r"[a-zA-Z]",s)
print(result)
运行结果:
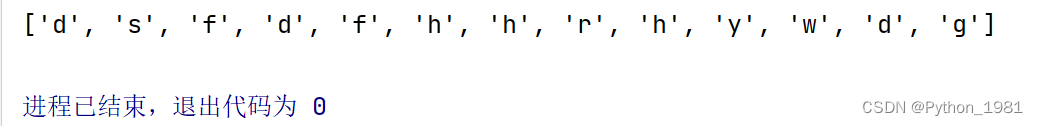
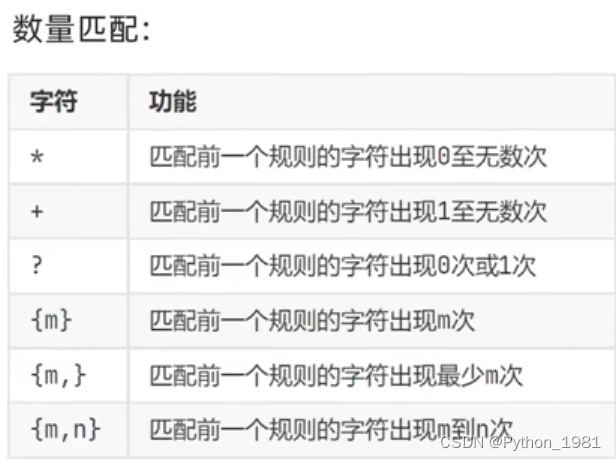
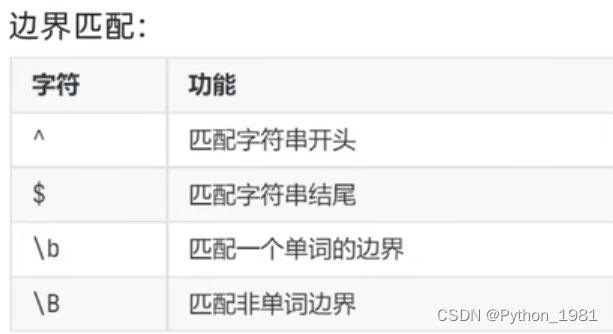
二、其他匹配规则

三、案例

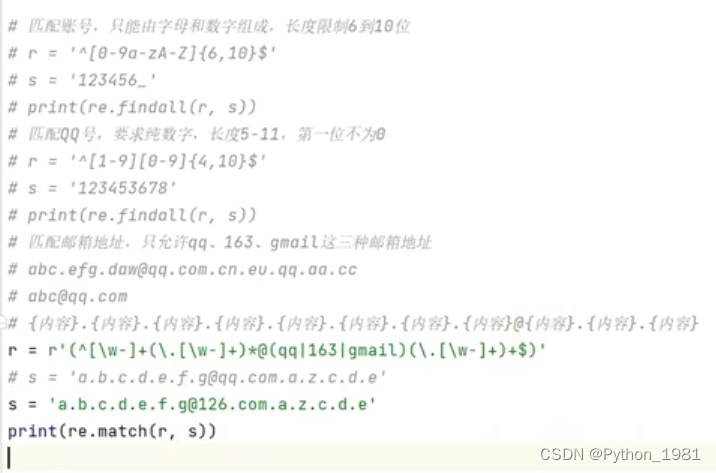
代码演示:
import re
# 匹配账户
r1="^[a-zA-Z0-9]{6,10}$"
s1="4526737sdh"
s2="265617ghsfghgh"
result1=re.findall(r1,s1)
result2=re.findall(r1,s2)
print(result1) # ['4526737sdh']
print(result2) # []
# 匹配QQ号
r2="^[1-9][0-9]{4,10}$"
s3="3gsd6231"
s4="67346"
print(re.findall(r2,s3)) # []
print(re.findall(r2,s4)) # ['67346']
# 匹配邮箱
r3=r"(^[\w-]+(\.[\w-]+)*@(qq|163|gmail)(\.[\w-]+)+$)"
s5="6437@qq.com"
s6="6437@126.com"
print(re.findall(r3,s5)) # [('6437@qq.com', '', 'qq', '.com')]
print(re.match(r3,s6)) # None
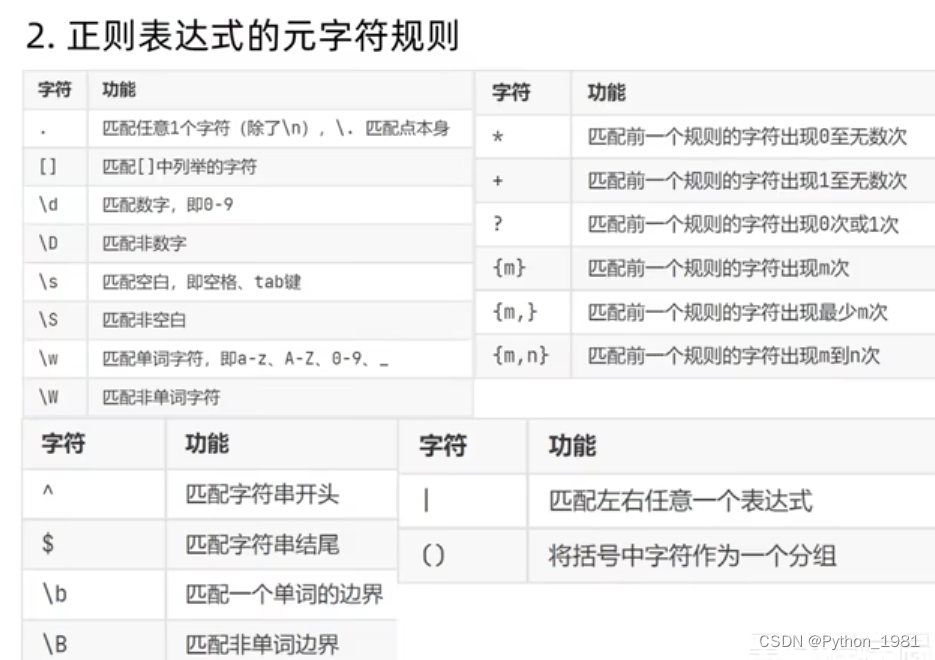
四、总结
![]()


















 162
162

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











