







文章目录
- 一、导读
- 二、部署环境
- 三、预测结果
-
- 3.1 使用检测模型
- 3.2 使用分割模型
- 3.3 使用分类模型
- 3.4 使用pose检测模型
- 四、COCO val 数据集
-
- 4.1 在 COCO128 val 上验证 YOLOv8n
- 4.2 在COCO128上训练YOLOv8n
- 五、自己训练
-
- 5.1 训练检测模型
- 5.2 训练分割模型
- 5.3 训练分类模型
- 5.4 训练pose模型
一、导读
YOLOv8是来自Ultralytics的最新的基于YOLO的对象检测模型系列,提供最先进的性能。
利用以前的 YOLO 版本,YOLOv8模型更快、更准确,同时为训练模型提供统一框架,以执行:
- 物体检测
- 实例分割
- 图像分类
Ultralytics为YOLO模型发布了一个全新的存储库。它被构建为 用于训练对象检测、实例分割和图像分类模型的统一框架。
以下是有关新版本的一些主要功能:
- 用户友好的 API(命令行 + Python)。
- 更快更准确。
- 支持:物体检测、实例分割和图像分类
- 可扩展到所有以前的版本。
- 新骨干网络。
- 新的无锚头。
- 新的损失函数。
YOLOv8 还高效灵活地支持多种导出格式,并且该模型可以在 CPU 和 GPU 上运行。
YOLOv8 模型的每个类别中有五个模型用于检测、分割和分类。YOLOv8 Nano 是最快和最小的,而 YOLOv8 Extra Large (YOLOv8x) 是其中最准确但最慢的。

YOLOv8 捆绑了以下预训练模型:
- 在图像分辨率为 640 的 COCO 检测数据集上训练的对象检测检查点。
- 在图像分辨率为 640 的 COCO 分割数据集上训练的实例分割检查点。
- 在图像分辨率为 224 的 ImageNet 数据集上预训练的图像分类模型。
二、部署环境
要充分发挥YOLOv8的潜力,需要从存储库和ultralytics包中安装要求。要安装要求,我们首先需要克隆存储库。
git clone https://github.com/ultralytics/ultralytics.git
pip install -r requirements.txt
在最新版本中,Ultralytics YOLOv8提供了完整的命令行界面 (CLI) API 和 Python SDK,用于执行训练、验证和推理。要使用yoloCLI,我们需要安装ultralytics包。
pip install ultralytics
我们的环境部署为:
%pip install ultralytics
import ultralytics
ultralytics.checks()

三、预测结果
YOLOv8 可以直接在命令行界面 (CLI) 中使用“yolo”命令来执行各种任务和模式,并接受其他参数,即“imgsz=640”。 查看可用 yolo 参数 的完整列表以及 YOLOv8 预测文档 中的其他详细信息 /train/)。
3.1 使用检测模型
!yolo predict model = yolov8n.pt source = '/kaggle/input/personpng/1.jpg'
import matplotlib.pyplot as plt
from PIL import Image
image = Image.open('/kaggle/working/runs/detect/predict/1.jpg')
plt.figure(figsize=(12, 8))
plt.imshow(image)
plt.axis('off')
plt.show()
结果展示为:

3.2 使用分割模型
!yolo task = segment mode = predict model = yolov8x-seg.pt source = '/kaggle/input/personpng/1.jpg'
image = Image.open('/kaggle/working/runs/segment/predict/1.jpg')
plt.figure(figsize=(12, 8))
plt.imshow(image)
plt.axis('off')
plt.show()

3.3 使用分类模型
!yolo task = classify mode = predict model = yolov8x-cls.pt source = '/kaggle/input/personpng/1.jpg'
image = Image.open('/kaggle/working/runs/classify/predict/1.jpg')
plt.figure(figsize=(20, 10))
plt.imshow(image)
plt.axis('off')
plt.show()

3.4 使用pose检测模型
!yolo task = pose mode = predict model = yolov8n-pose.pt source = '/kaggle/input/personpng/1.jpg'
image = Image.open('/kaggle/working/runs/pose/predict/1.jpg')
plt.figure(figsize=(12, 8))
plt.imshow(image)
plt.axis('off')
plt.show()

四、COCO val 数据集
文件的大小为780M,共计5000张图像。
import torch
torch.hub.download_url_to_file('https://ultralytics.com/assets/coco2017val.zip', 'tmp.zip')
!unzip -q tmp.zip -d datasets && rm tmp.zip

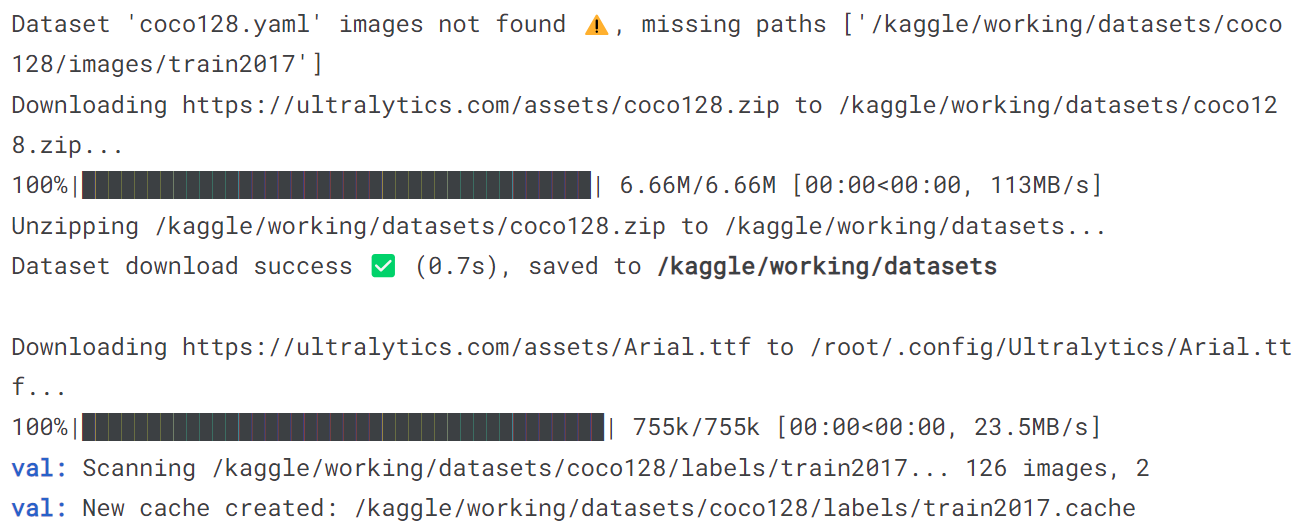
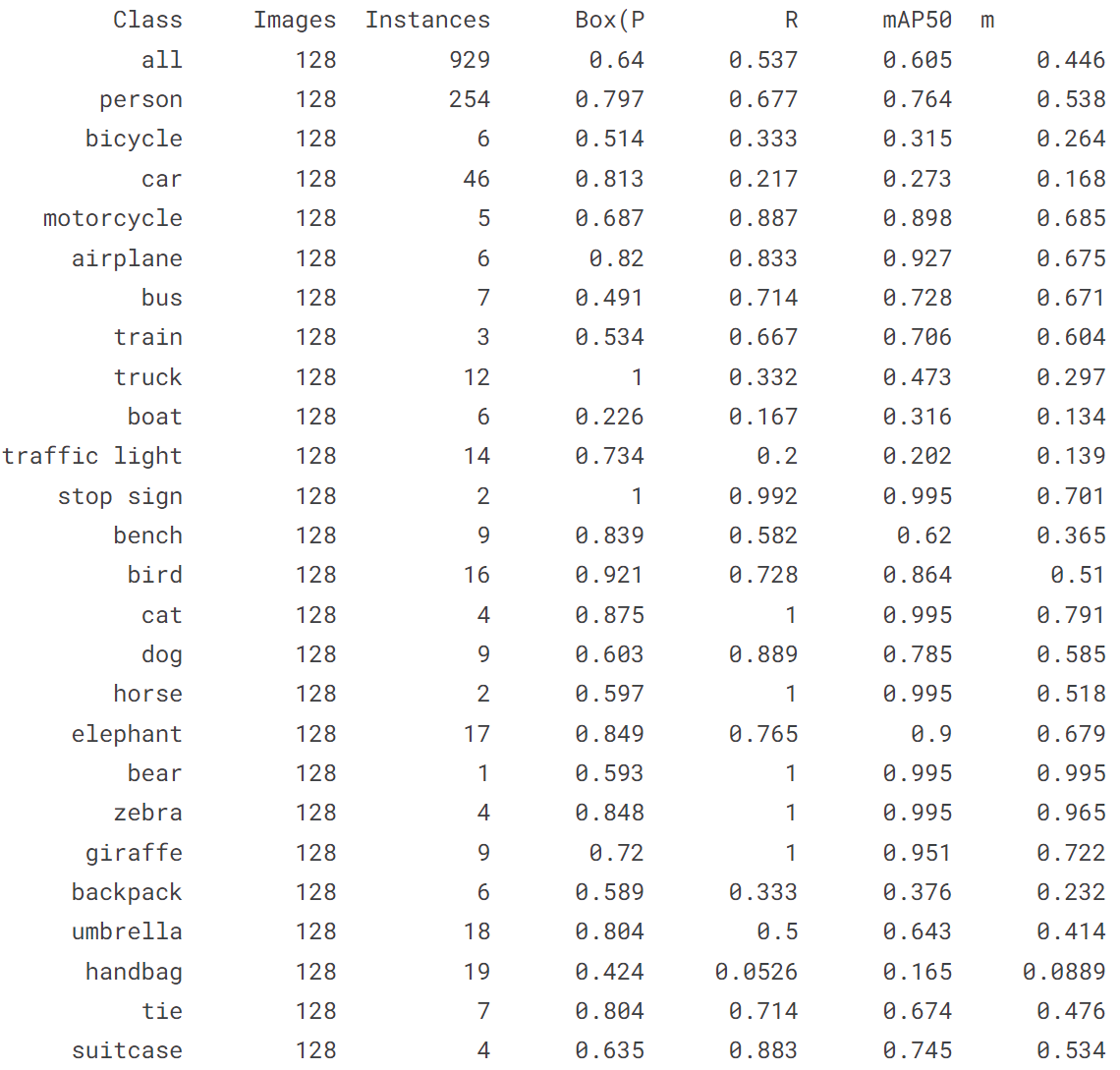
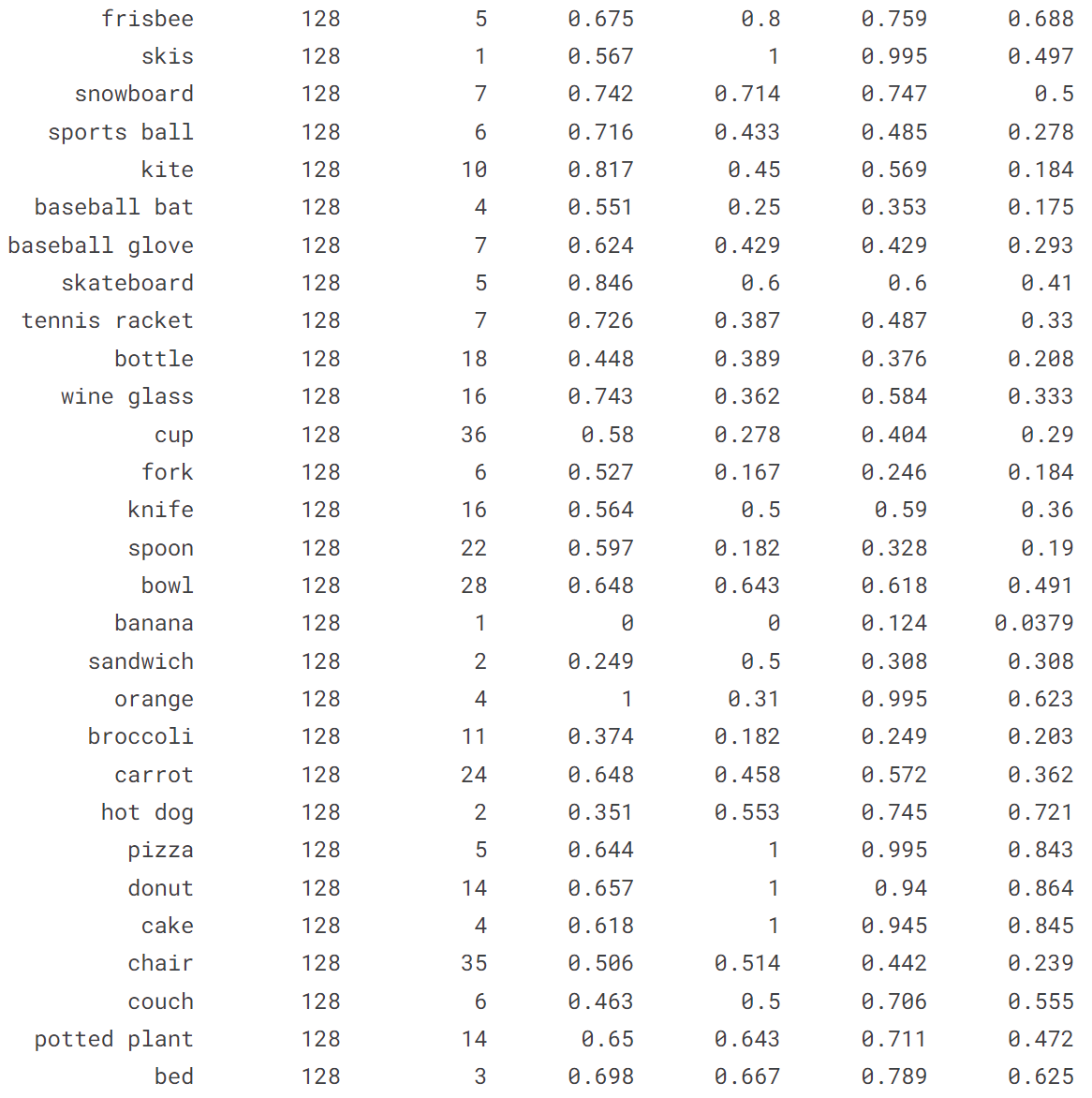
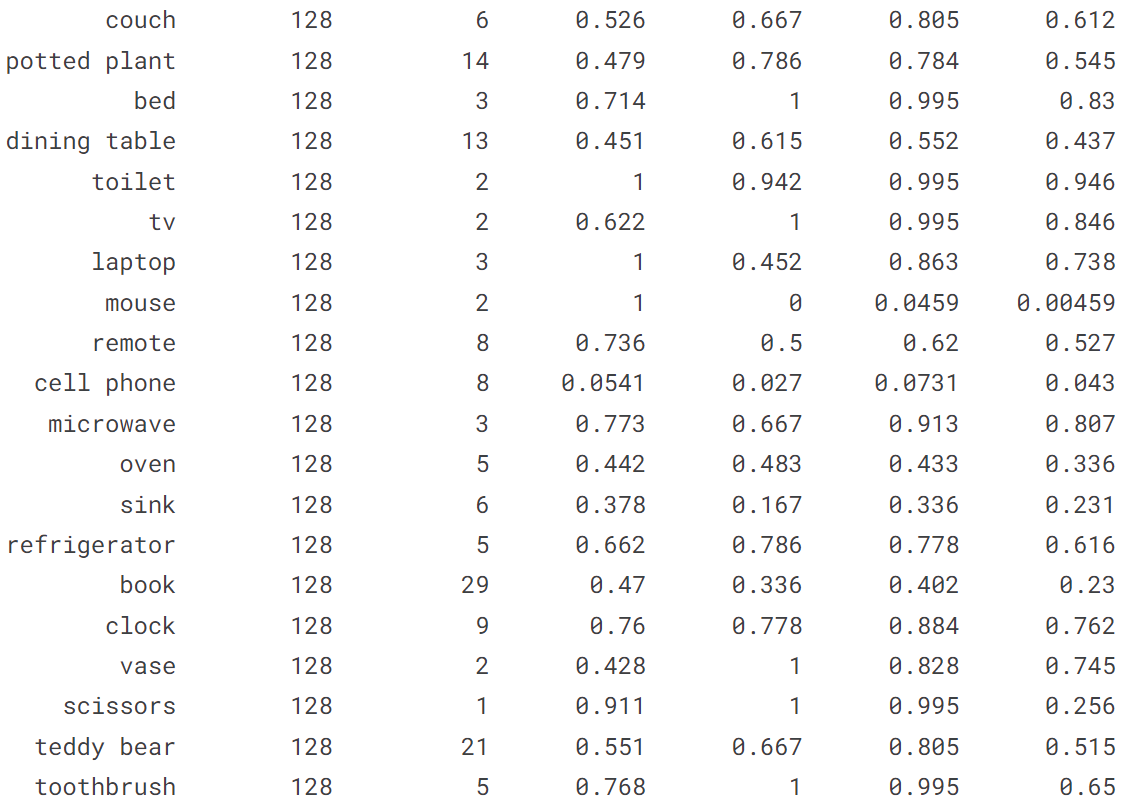
4.1 在 COCO128 val 上验证 YOLOv8n
!yolo val model = yolov8n.pt data = coco128.yaml
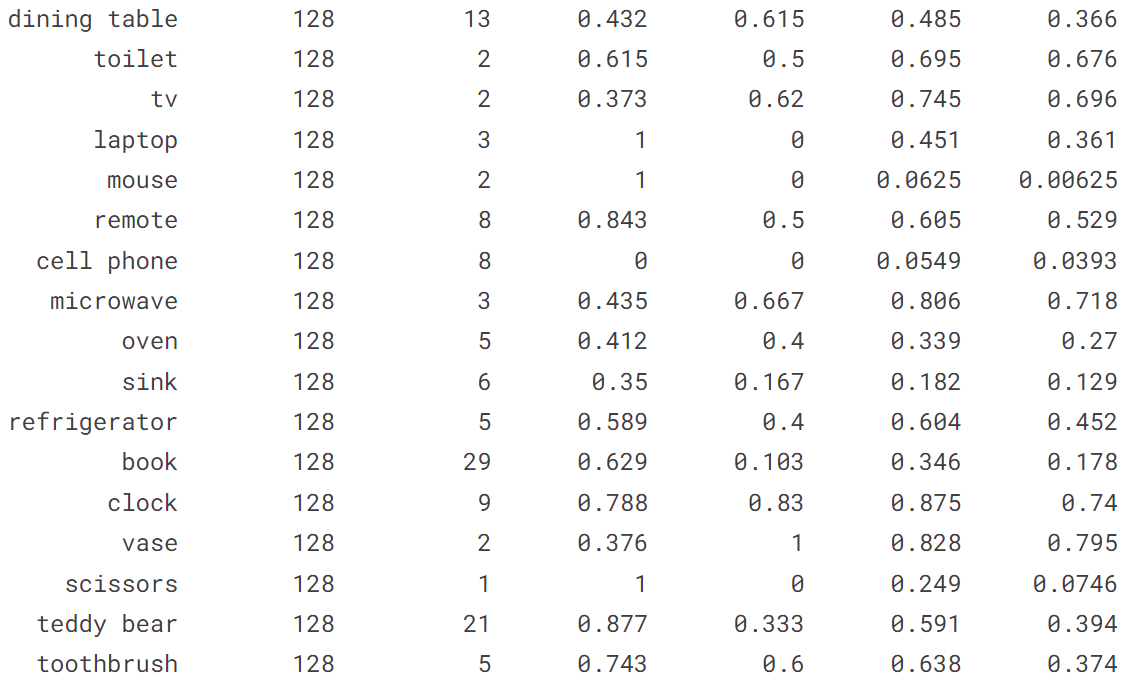

import os
folder_path = '/kaggle/working/runs/detect/val'
image_extensions = ['.jpg', '.jpeg', '.png'] # 支持的图片文件扩展名
image_paths = []
for file in os.listdir(folder_path):
if any(file.endswith(extension) for extension in image_extensions):
image_paths.append(os.path.join(folder_path, file))
for image_path in image_paths:
image = plt.imread(image_path)
plt.figure(figsize=(12, 8))
plt.imshow(image)
plt.axis('off')
plt.show()
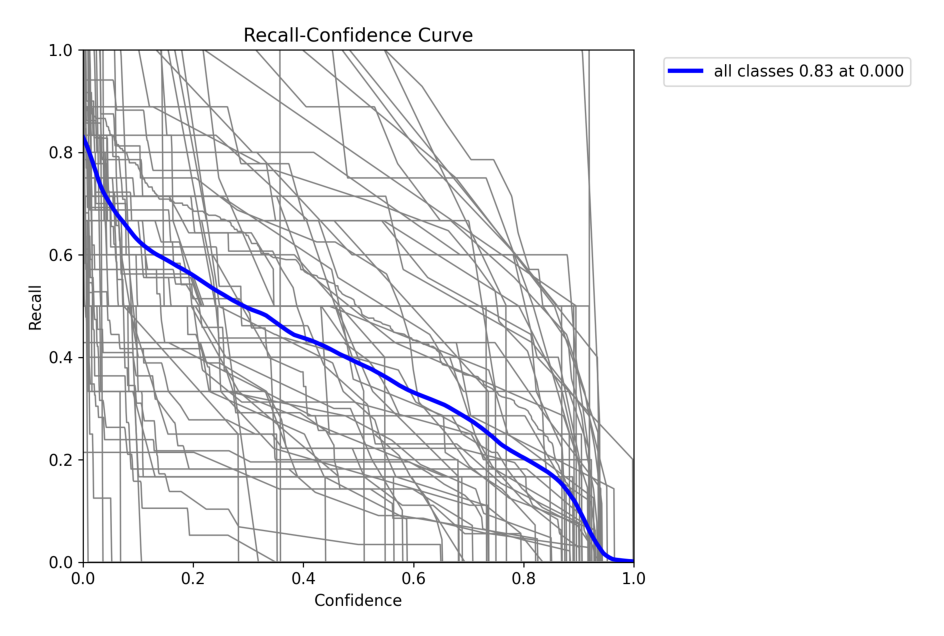


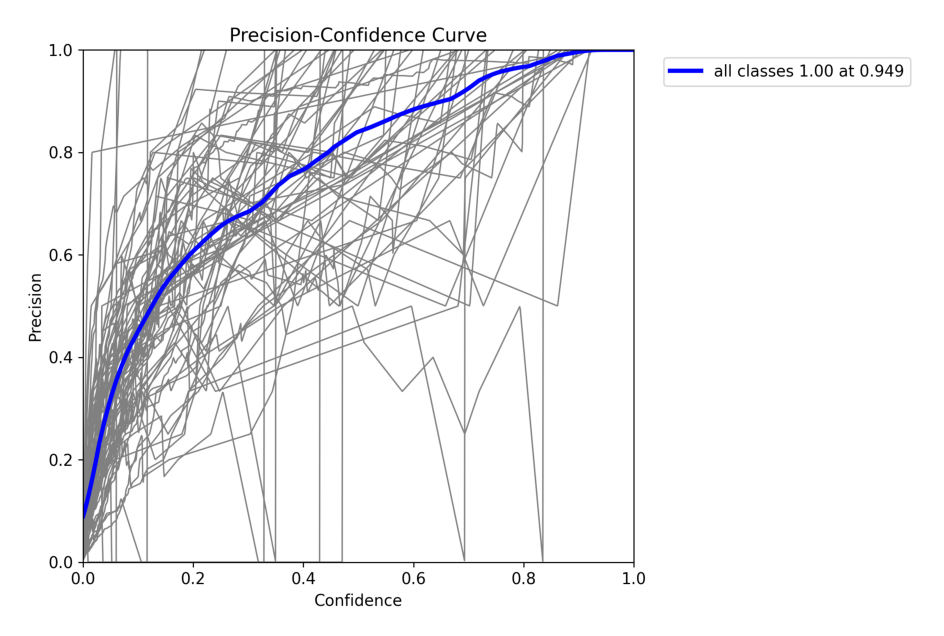

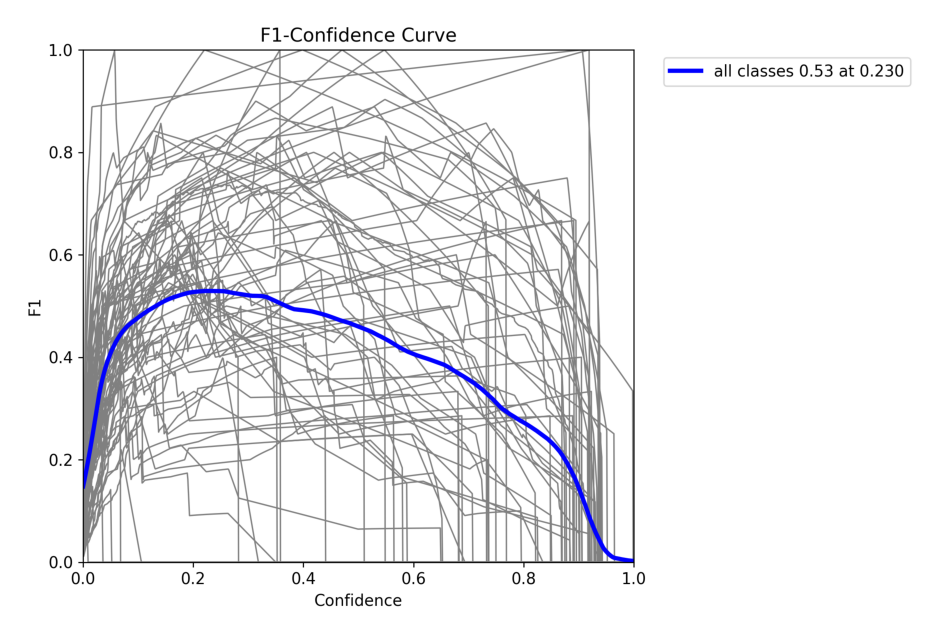


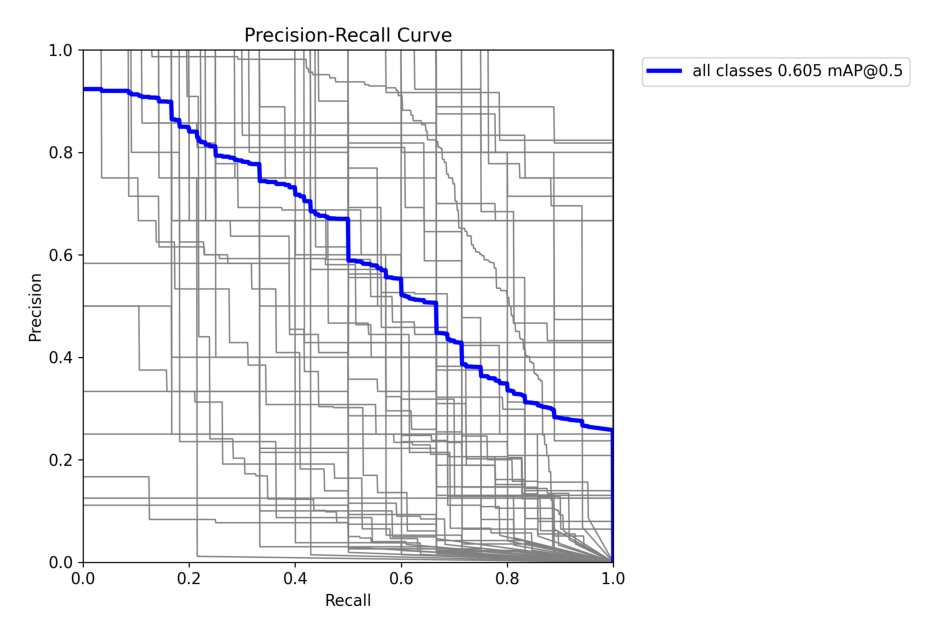
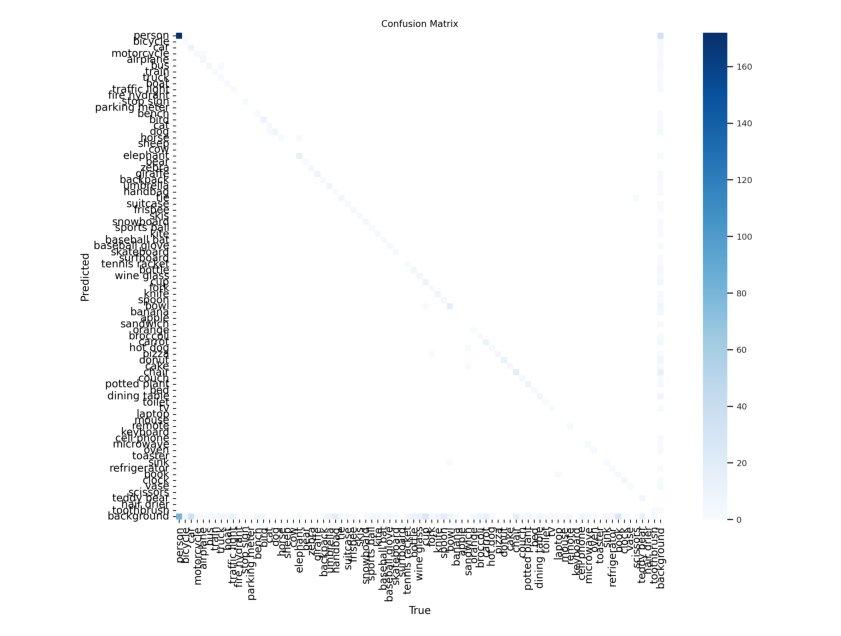

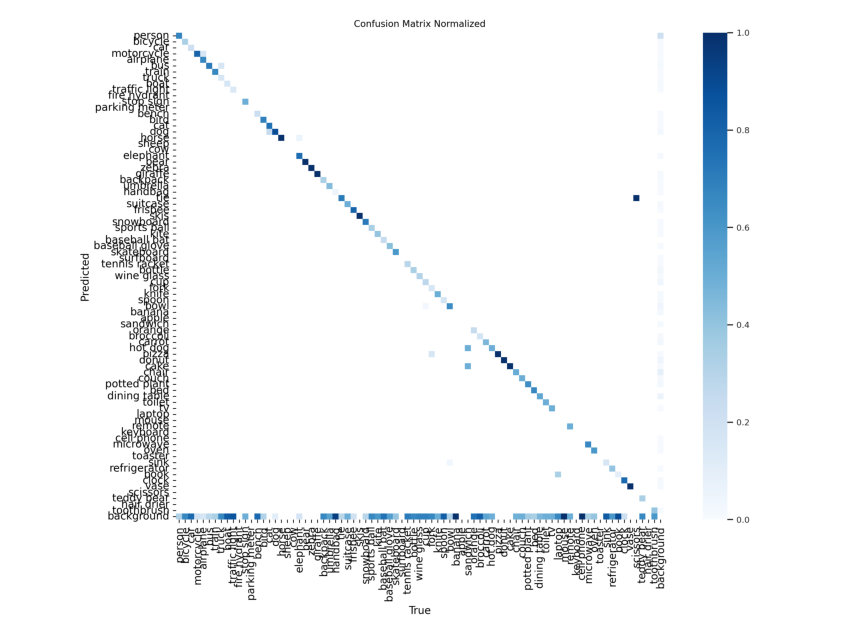
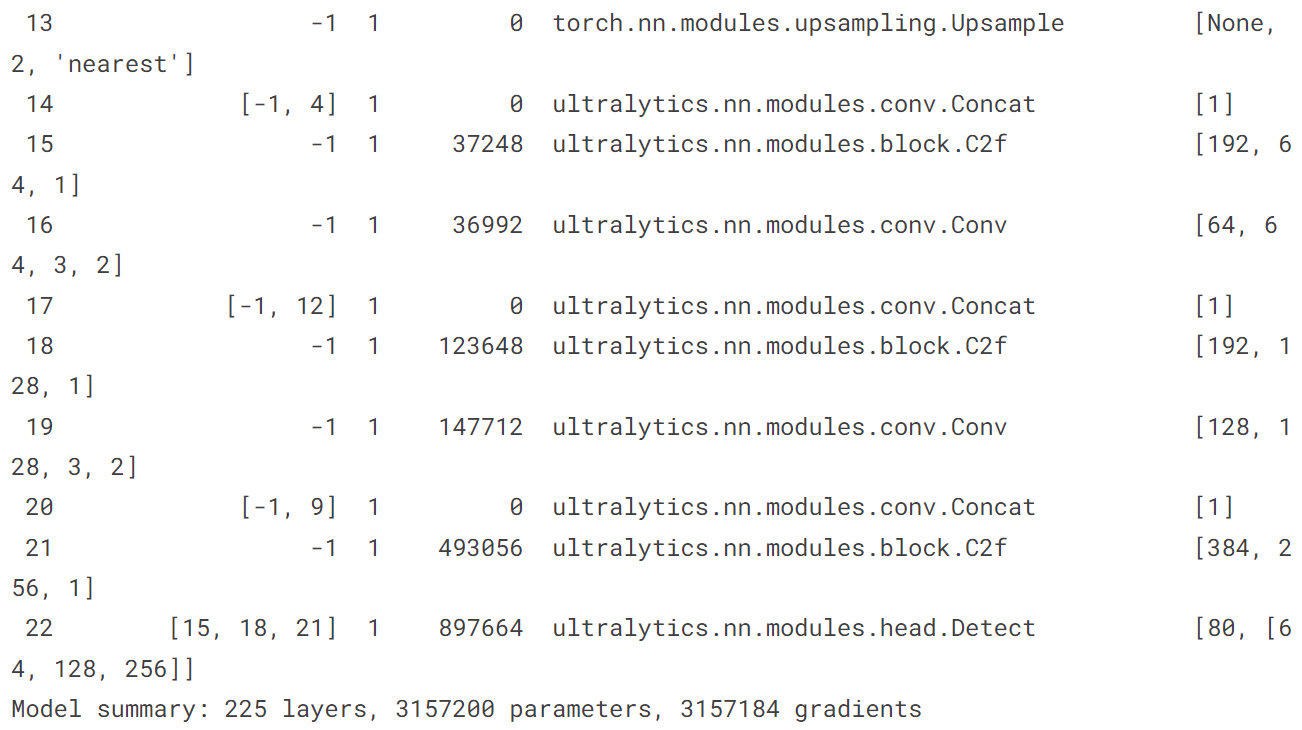
4.2 在COCO128上训练YOLOv8n
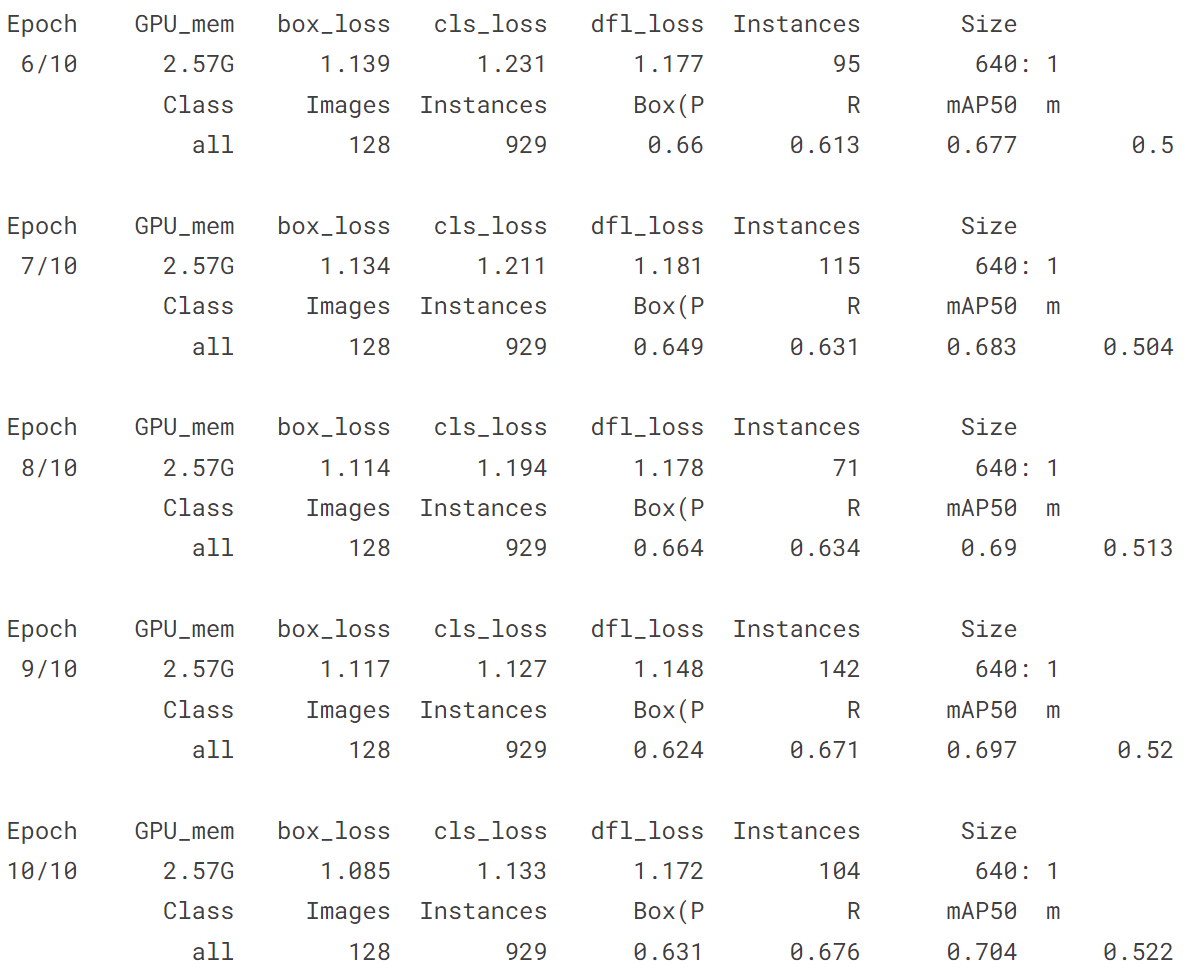
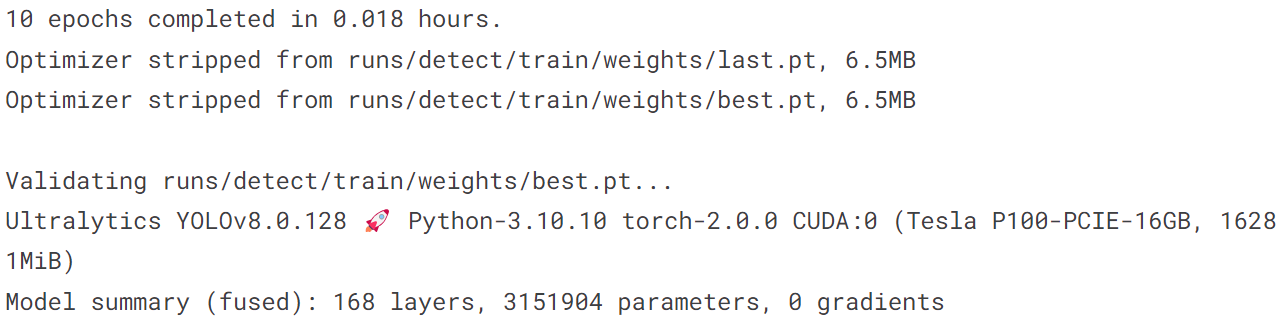
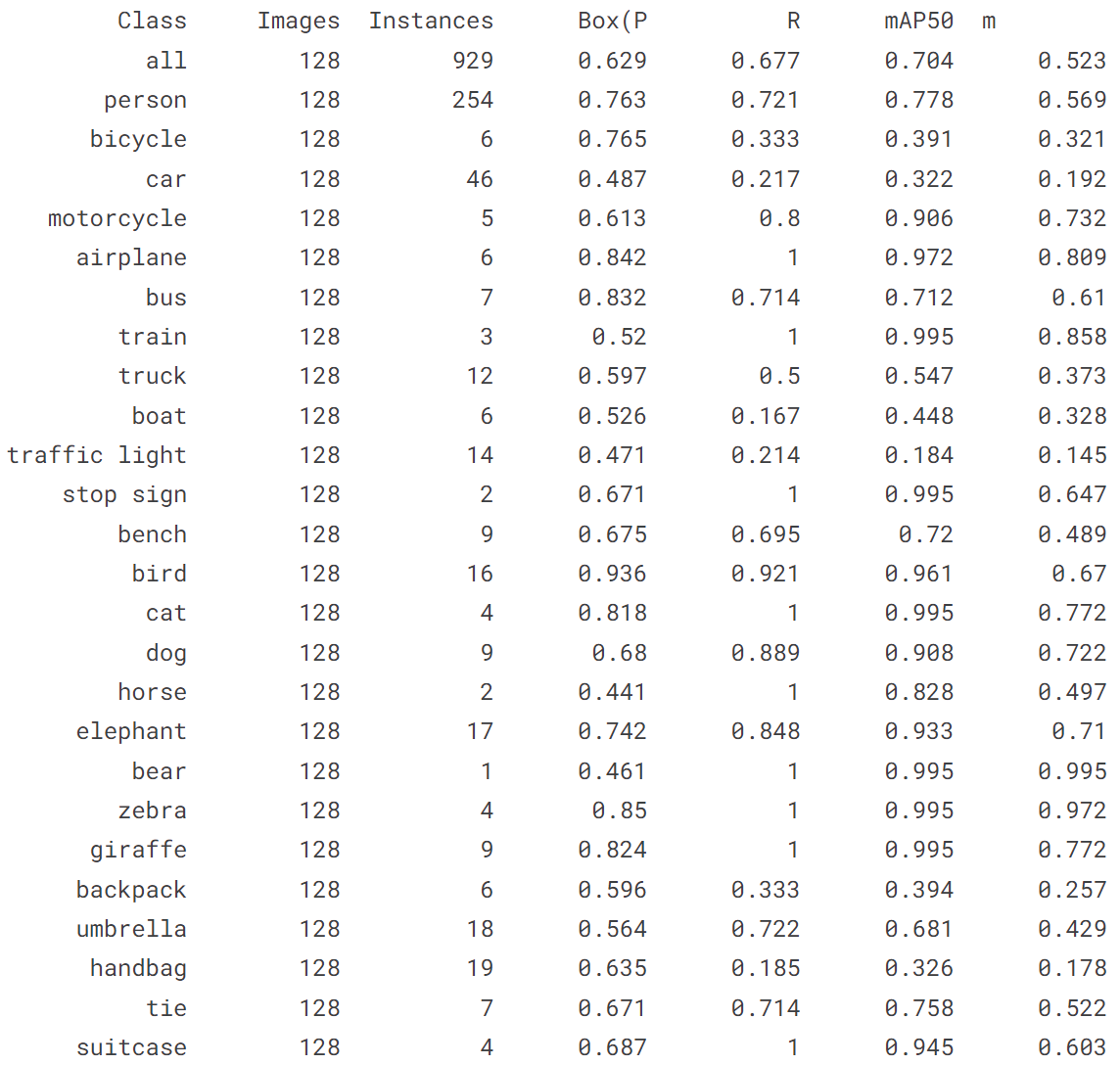
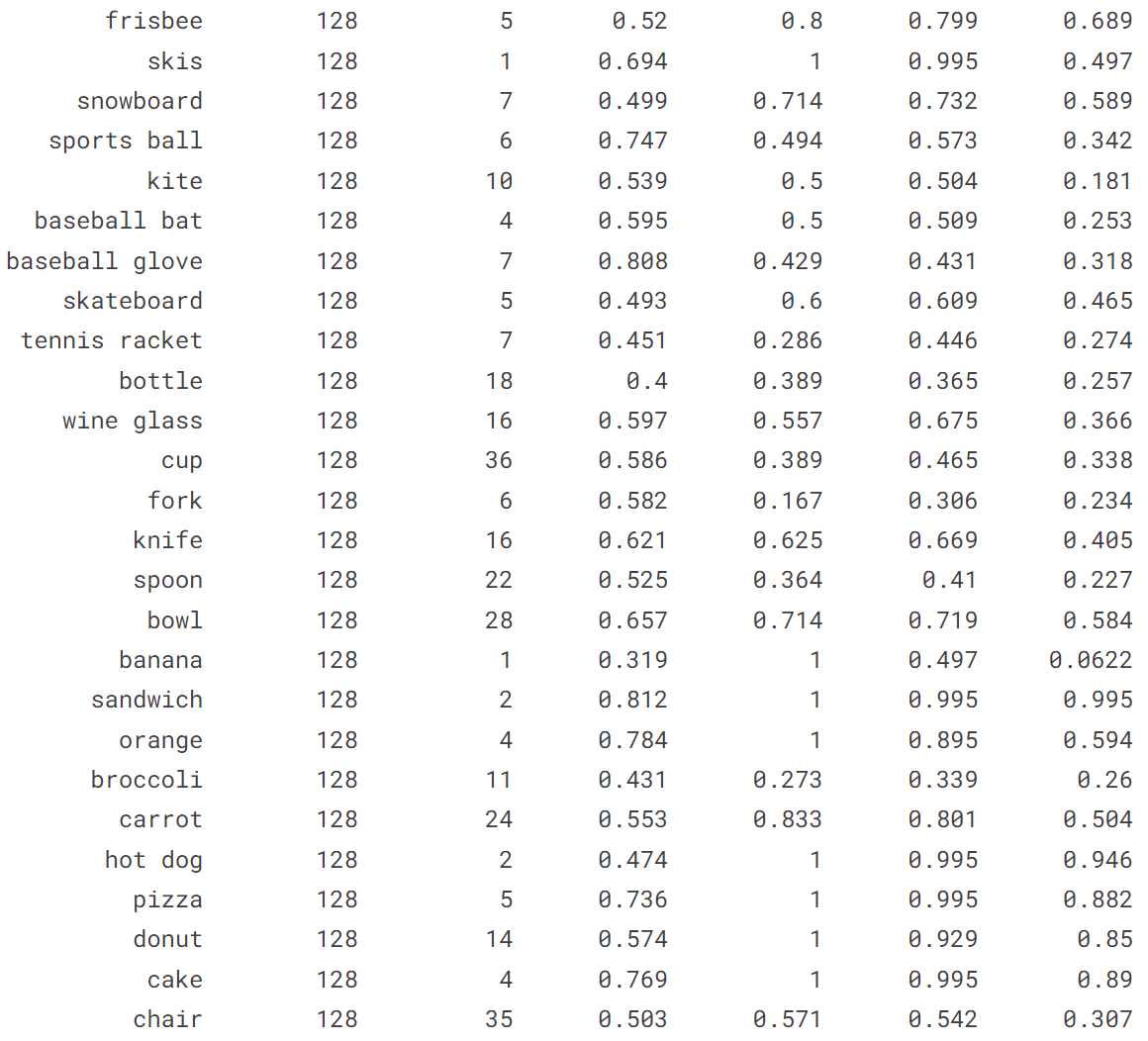
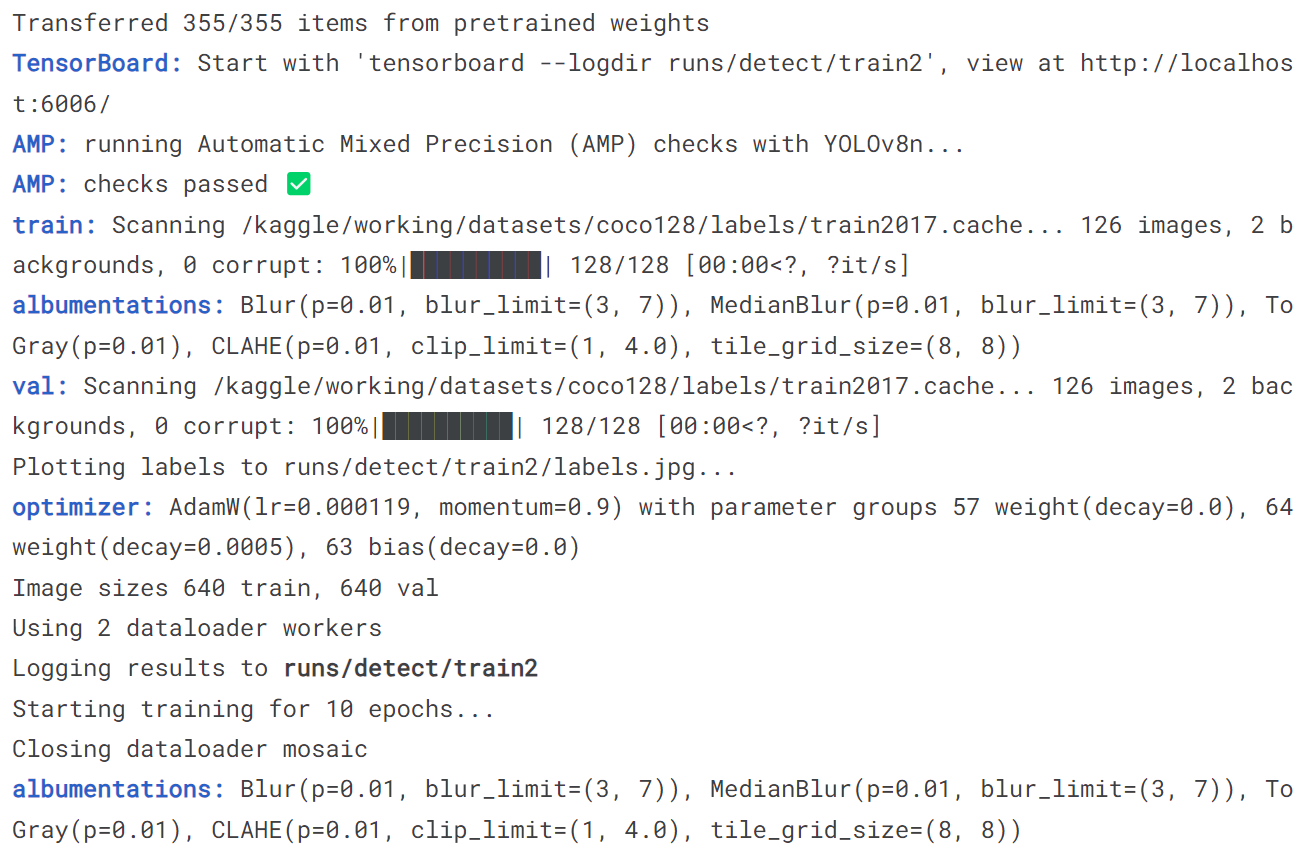
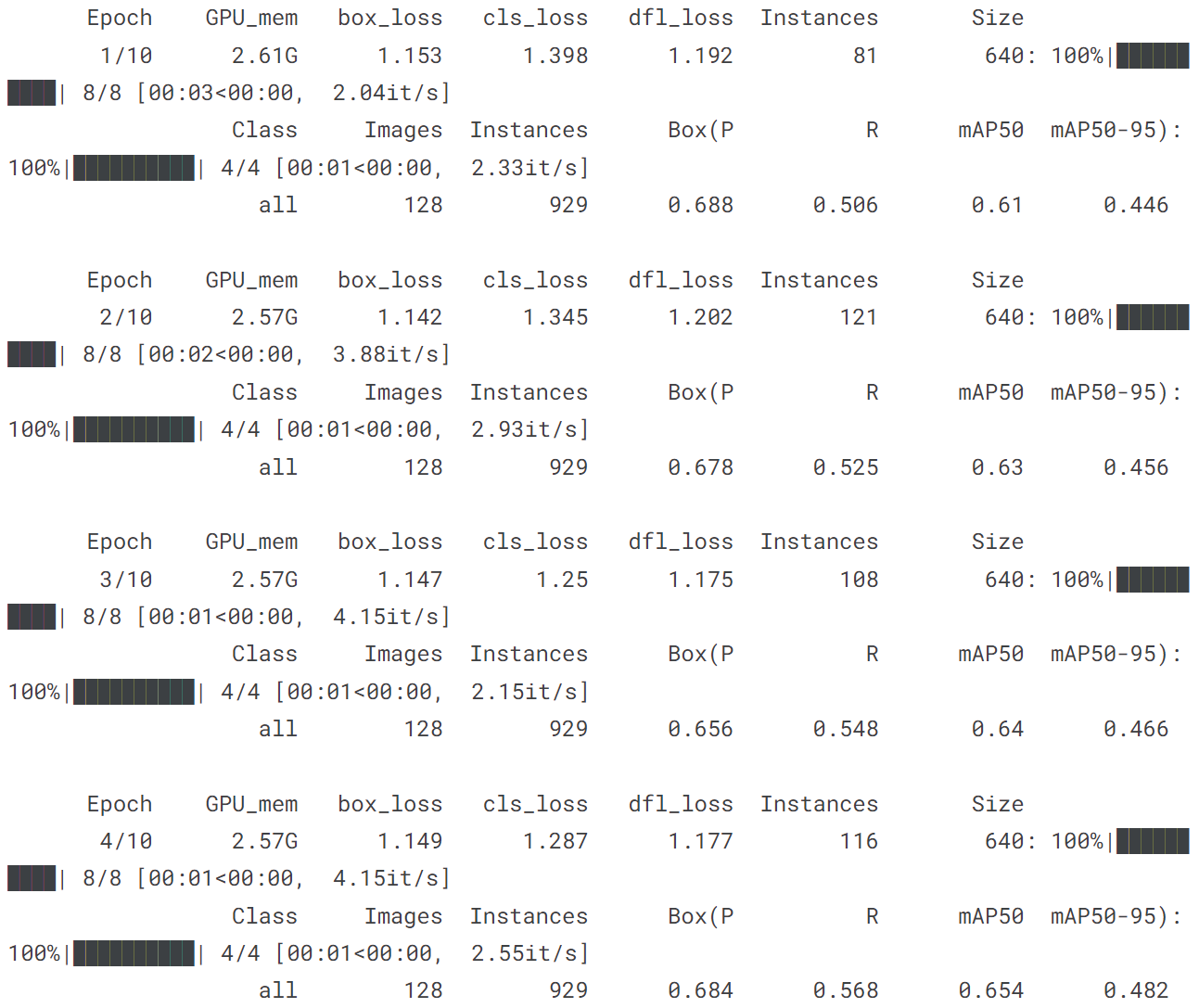
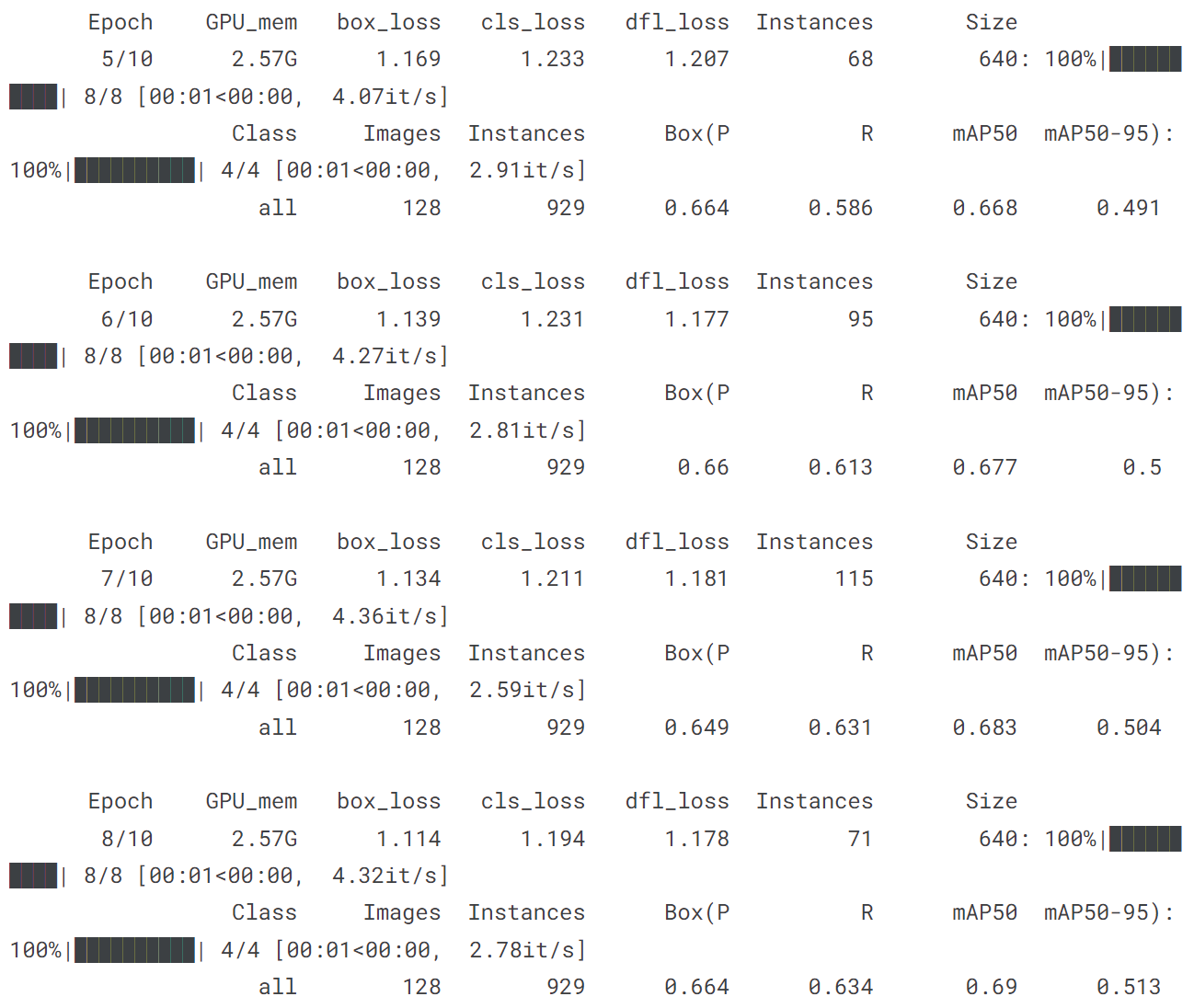
!yolo train model = yolov8n.pt data = coco128.yaml epochs = 10 imgsz = 640

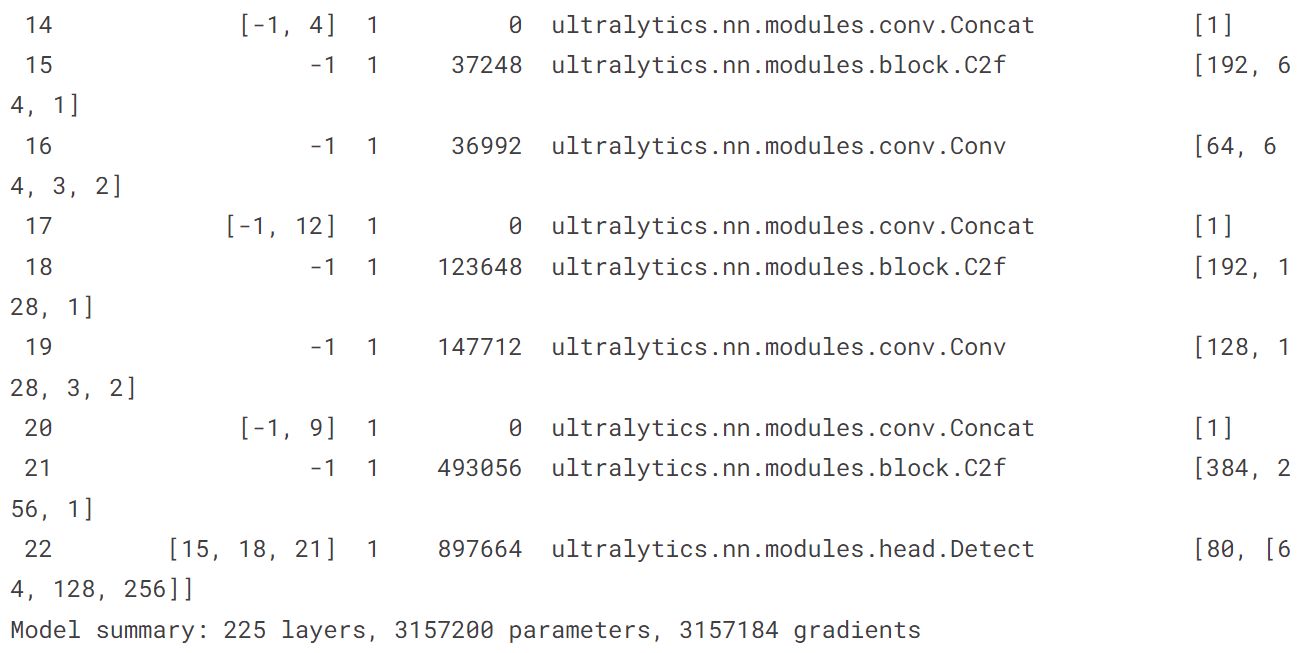
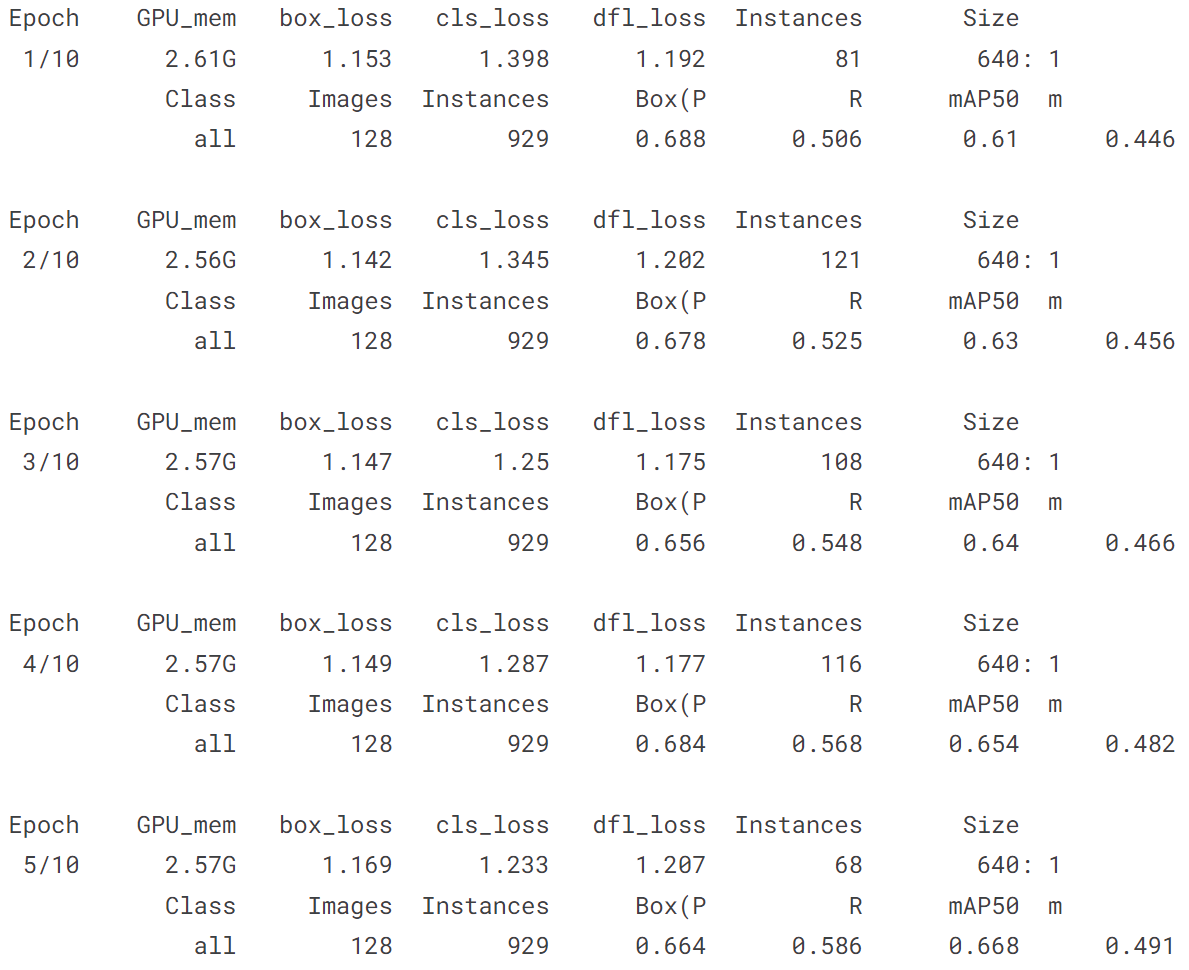
五、自己训练
5.1 训练检测模型
# 导入YOLOv8n, 在COCO128上训练10个epochs,最后用一张图片预测
from ultralytics import YOLO
model = YOLO('yolov8n.pt')
model.train(data = 'coco128.yaml', epochs = 10)
model('https://ultralytics.com/images/bus.jpg')


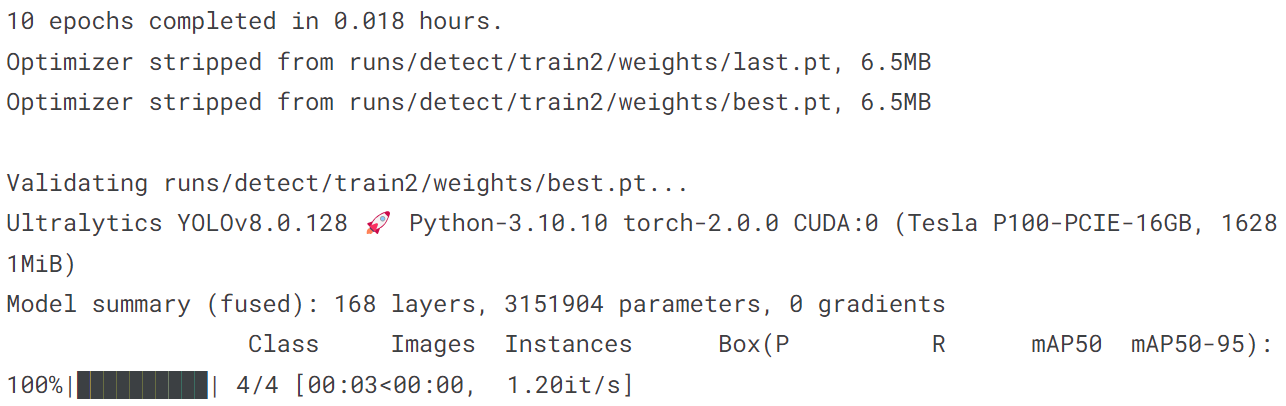
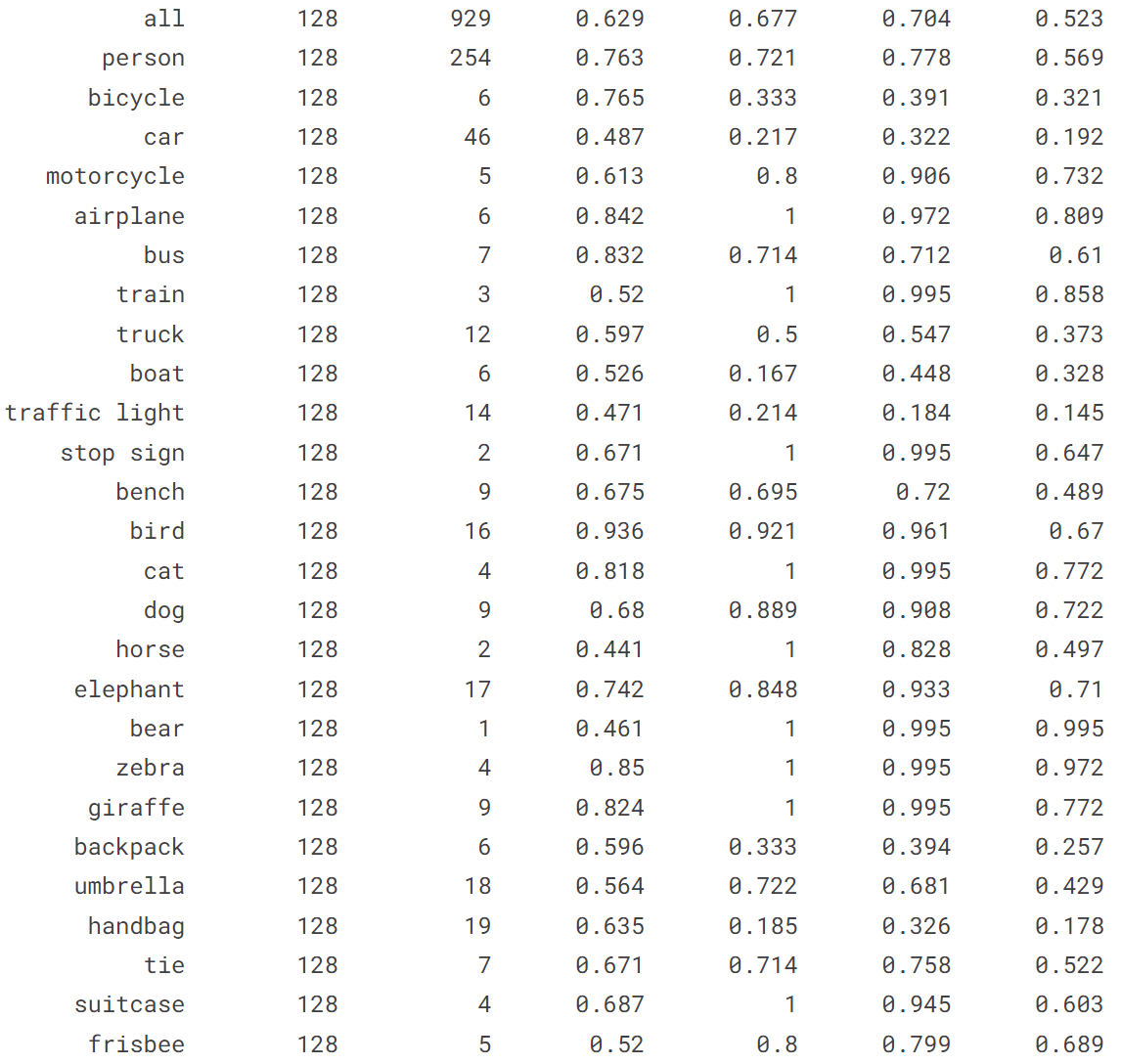
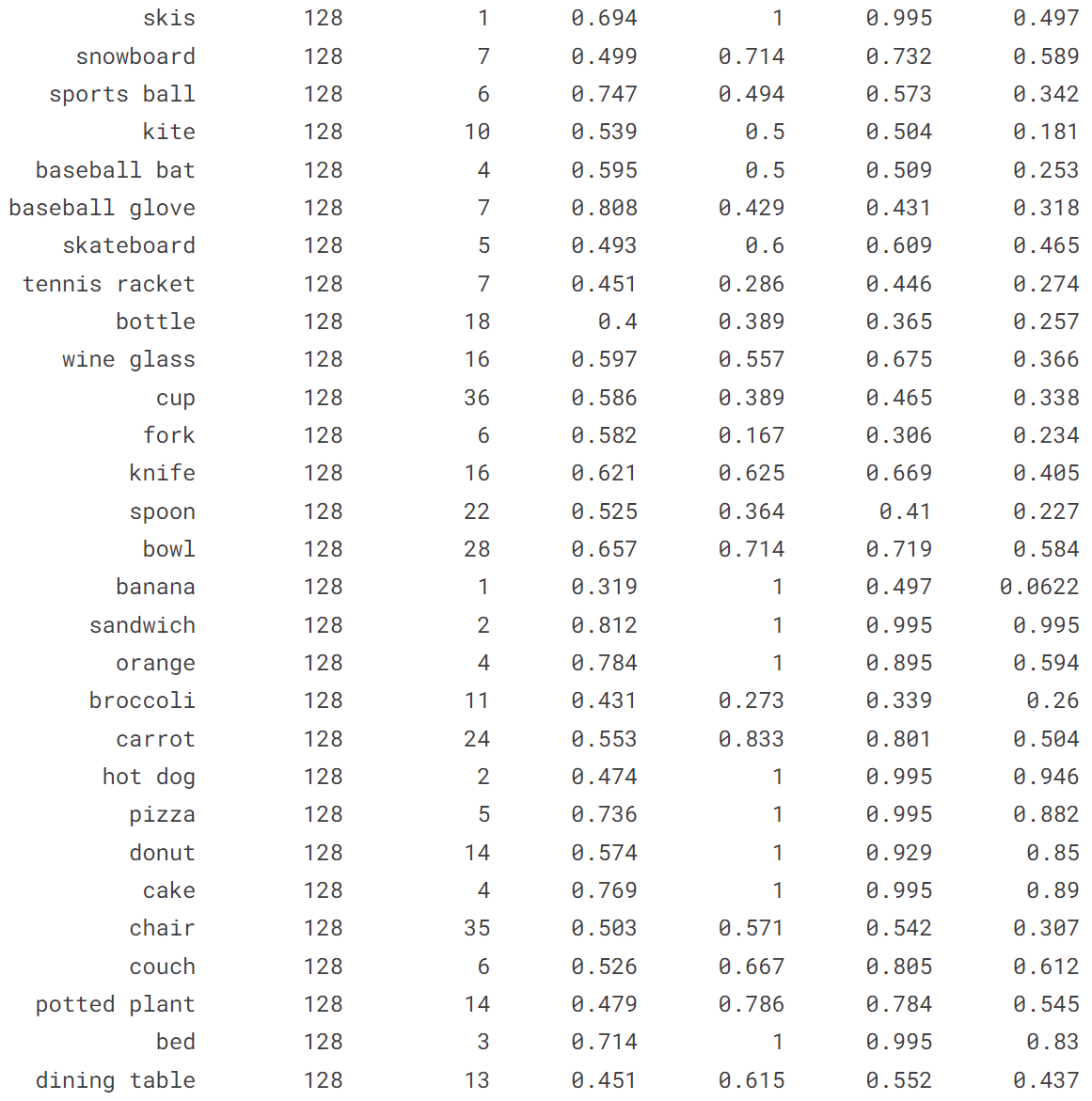
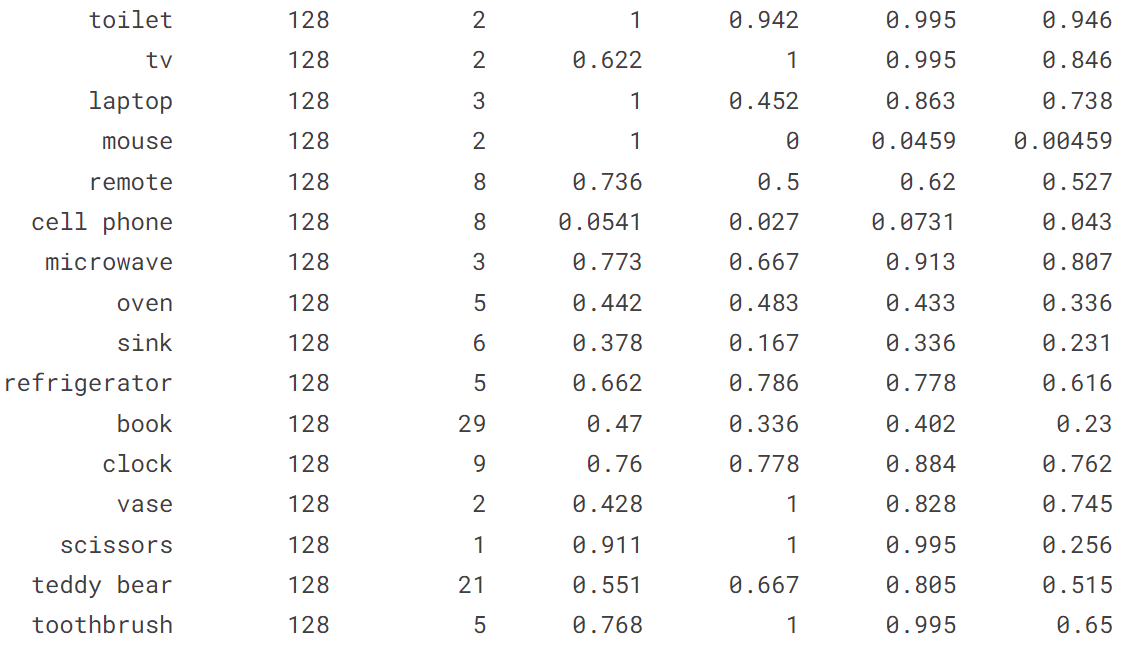
输出结果:
[ultralytics.yolo.engine.results.Results object with attributes:
boxes: ultralytics.yolo.engine.results.Boxes object
keypoints: None
keys: ['boxes']
masks: None
names: {0: 'person', 1: 'bicycle', 2: 'car', 3: 'motorcycle', 4: 'airplane', 5: 'bus', 6: 'train', 7: 'truck', 8: 'boat', 9: 'traffic light', 10: 'fire hydrant', 11: 'stop sign', 12: 'parking meter', 13: 'bench', 14: 'bird', 15: 'cat', 16: 'dog', 17: 'horse', 18: 'sheep', 19: 'cow', 20: 'elephant', 21: 'bear', 22: 'zebra', 23: 'giraffe', 24: 'backpack', 25: 'umbrella', 26: 'handbag', 27: 'tie', 28: 'suitcase', 29: 'frisbee', 30: 'skis', 31: 'snowboard', 32: 'sports ball', 33: 'kite', 34: 'baseball bat', 35: 'baseball glove', 36: 'skateboard', 37: 'surfboard', 38: 'tennis racket', 39: 'bottle', 40: 'wine glass', 41: 'cup', 42: 'fork', 43: 'knife', 44: 'spoon', 45: 'bowl', 46: 'banana', 47: 'apple', 48: 'sandwich', 49: 'orange', 50: 'broccoli', 51: 'carrot', 52: 'hot dog', 53: 'pizza', 54: 'donut', 55: 'cake', 56: 'chair', 57: 'couch', 58: 'potted plant', 59: 'bed', 60: 'dining table', 61: 'toilet', 62: 'tv', 63: 'laptop', 64: 'mouse', 65: 'remote', 66: 'keyboard', 67: 'cell phone', 68: 'microwave', 69: 'oven', 70: 'toaster', 71: 'sink', 72: 'refrigerator', 73: 'book', 74: 'clock', 75: 'vase', 76: 'scissors', 77: 'teddy bear', 78: 'hair drier', 79: 'toothbrush'}
orig_img: array([[[122, 148, 172],
[120, 146, 170],
[125, 153, 177],
...,
[157, 170, 184],
[158, 171, 185],
[158, 171, 185]],
[[127, 153, 177],
[124, 150, 174],
[127, 155, 179],
...,
[158, 171, 185],
[159, 172, 186],
[159, 172, 186]],
[[128, 154, 178],
[126, 152, 176],
[126, 154, 178],
...,
[158, 171, 185],
[158, 171, 185],
[158, 171, 185]],
...,
[[185, 185, 191],
[182, 182, 188],
[179, 179, 185],
...,
[114, 107, 112],
[115, 105, 111],
[116, 106, 112]],
[[157, 157, 163],
[180, 180, 186],
[185, 186, 190],
...,
[107, 97, 103],
[102, 92, 98],
[108, 98, 104]],
[[112, 112, 118],
[160, 160, 166],
[169, 170, 174],
...,
[ 99, 89, 95],
[ 96, 86, 92],
[102, 92, 98]]], dtype=uint8)
orig_shape: (1080, 810)
path: '/kaggle/working/bus.jpg'
probs: None
save_dir: None
speed: {'preprocess': 2.184629440307617, 'inference': 7.320880889892578, 'postprocess': 1.7354488372802734}]
我们测试的原图为:
image = Image.open('/kaggle/working/bus.jpg')
plt.figure(figsize=(12, 8))
plt.imshow(image)
plt.axis('off')
plt.show()

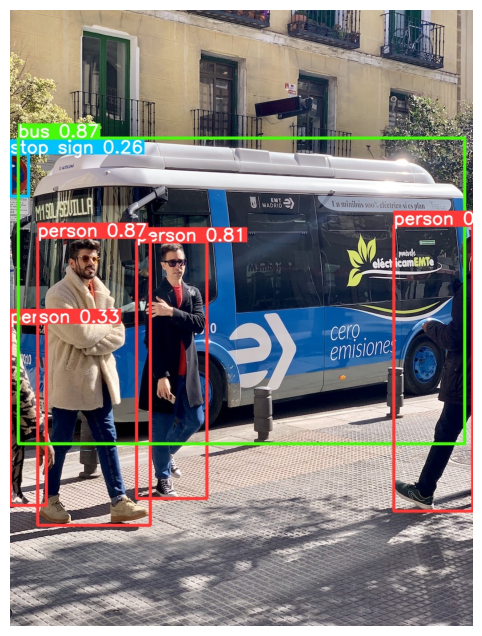
!yolo predict model = '/kaggle/working/runs/detect/train2/weights/best.pt' source = '/kaggle/working/bus.jpg'
image = Image.open('/kaggle/working/runs/detect/predict2/bus.jpg')
plt.figure(figsize=(12, 8))
plt.imshow(image)
plt.axis('off')
plt.show()
!yolo predict model = '/kaggle/working/runs/detect/train2/weights/best.pt' source = '/kaggle/input/personpng/1.jpg'
image = Image.open('/kaggle/working/runs/detect/predict3/1.jpg')
plt.figure(figsize=(12, 8))
plt.imshow(image)
plt.axis('off')
plt.show()

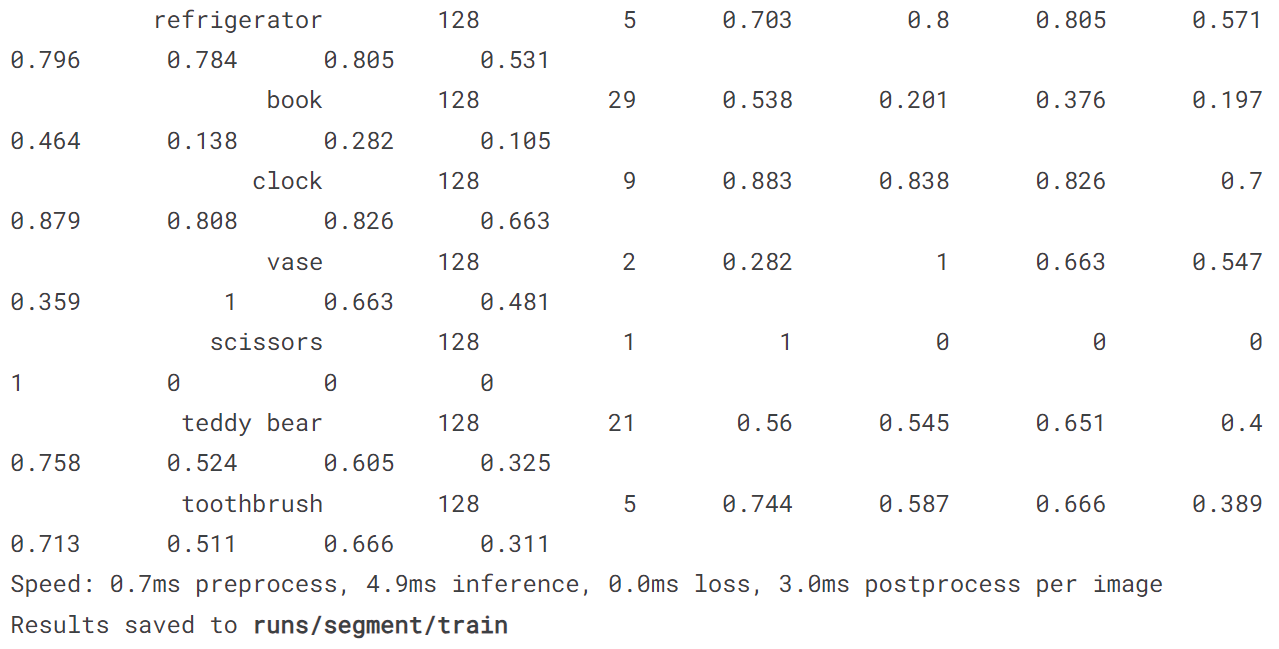
5.2 训练分割模型
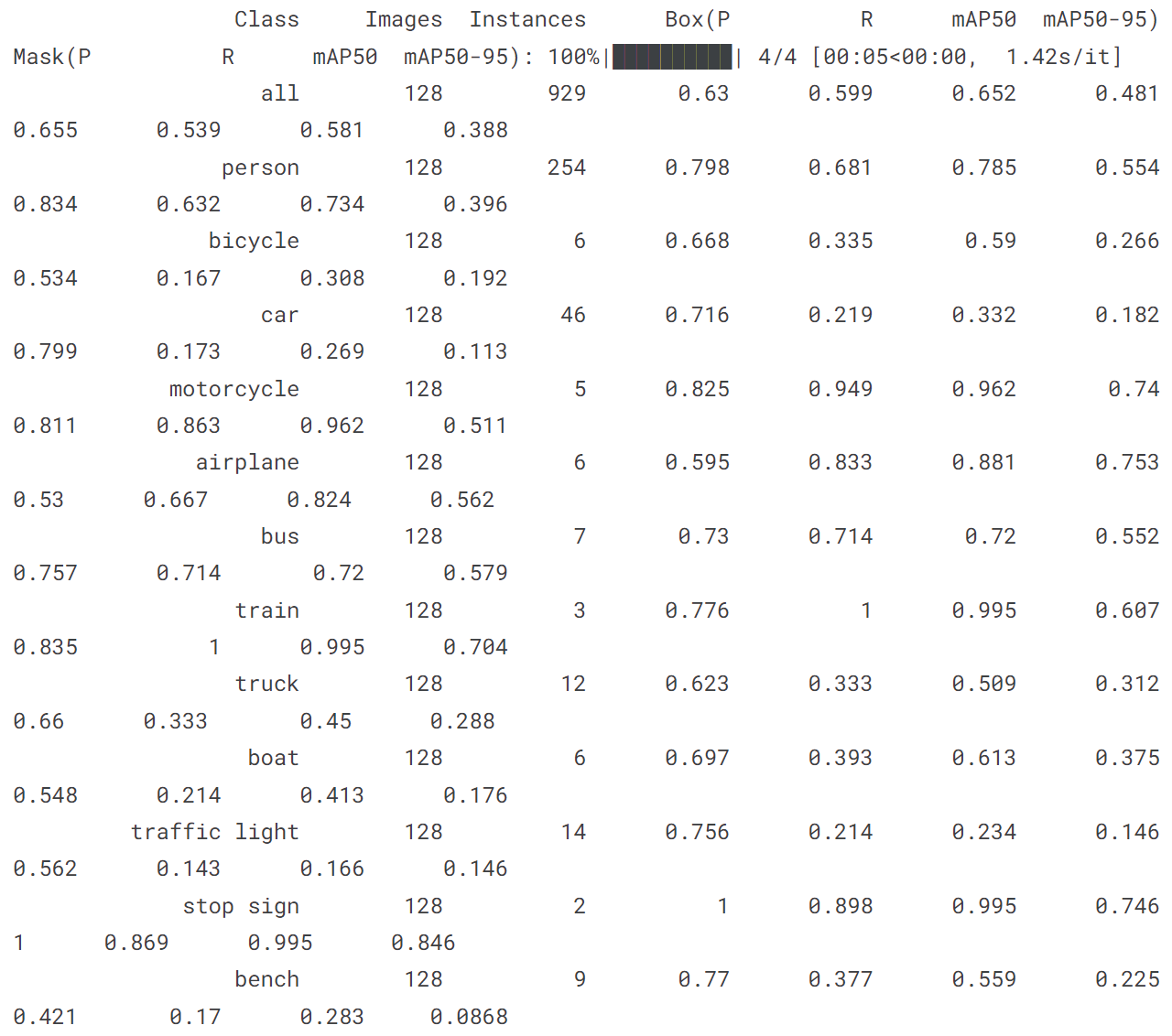
model = YOLO('yolov8n-seg.pt')
model.train(data='coco128-seg.yaml', epochs = 10)
model('https://ultralytics.com/images/bus.jpg')







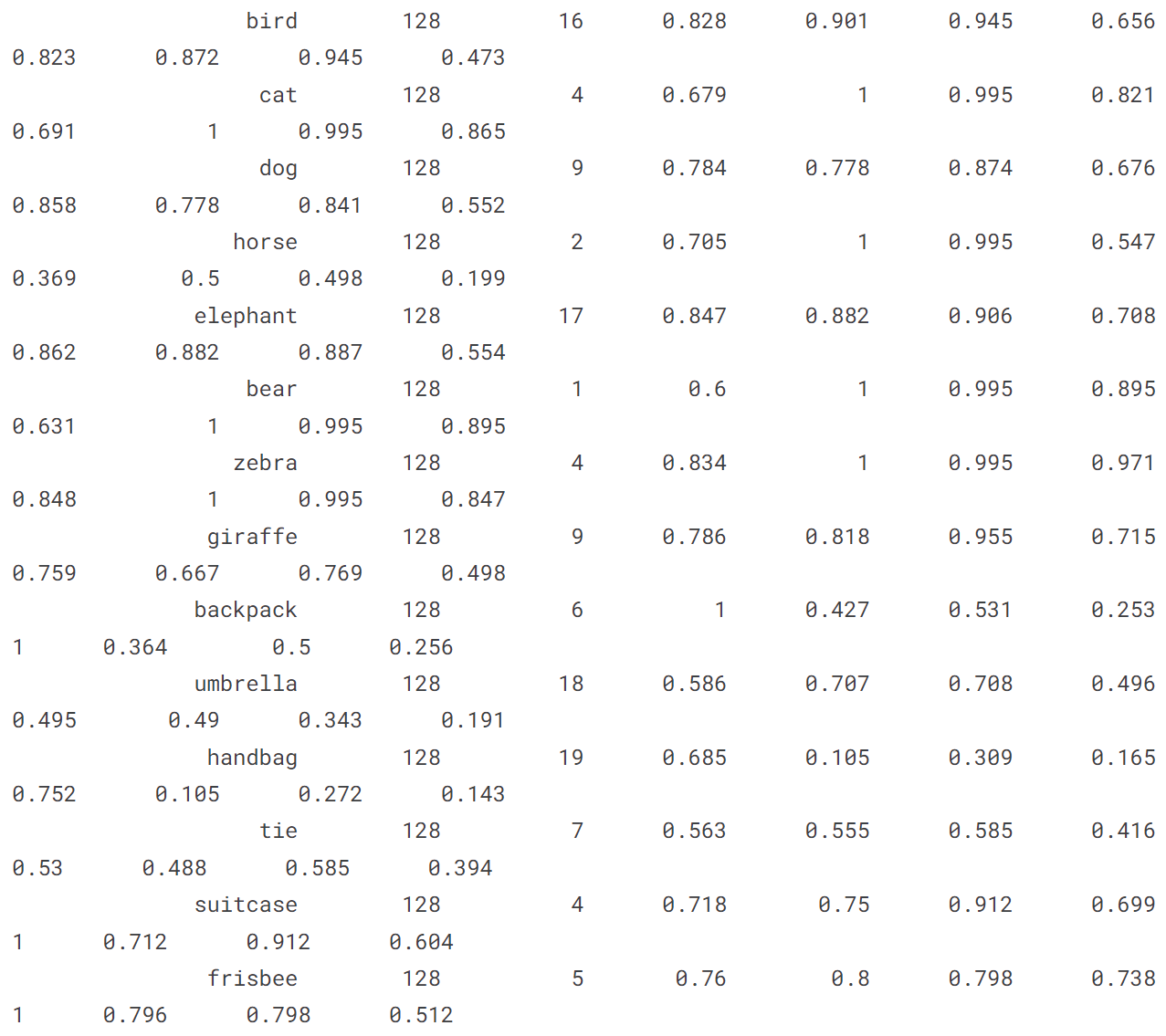
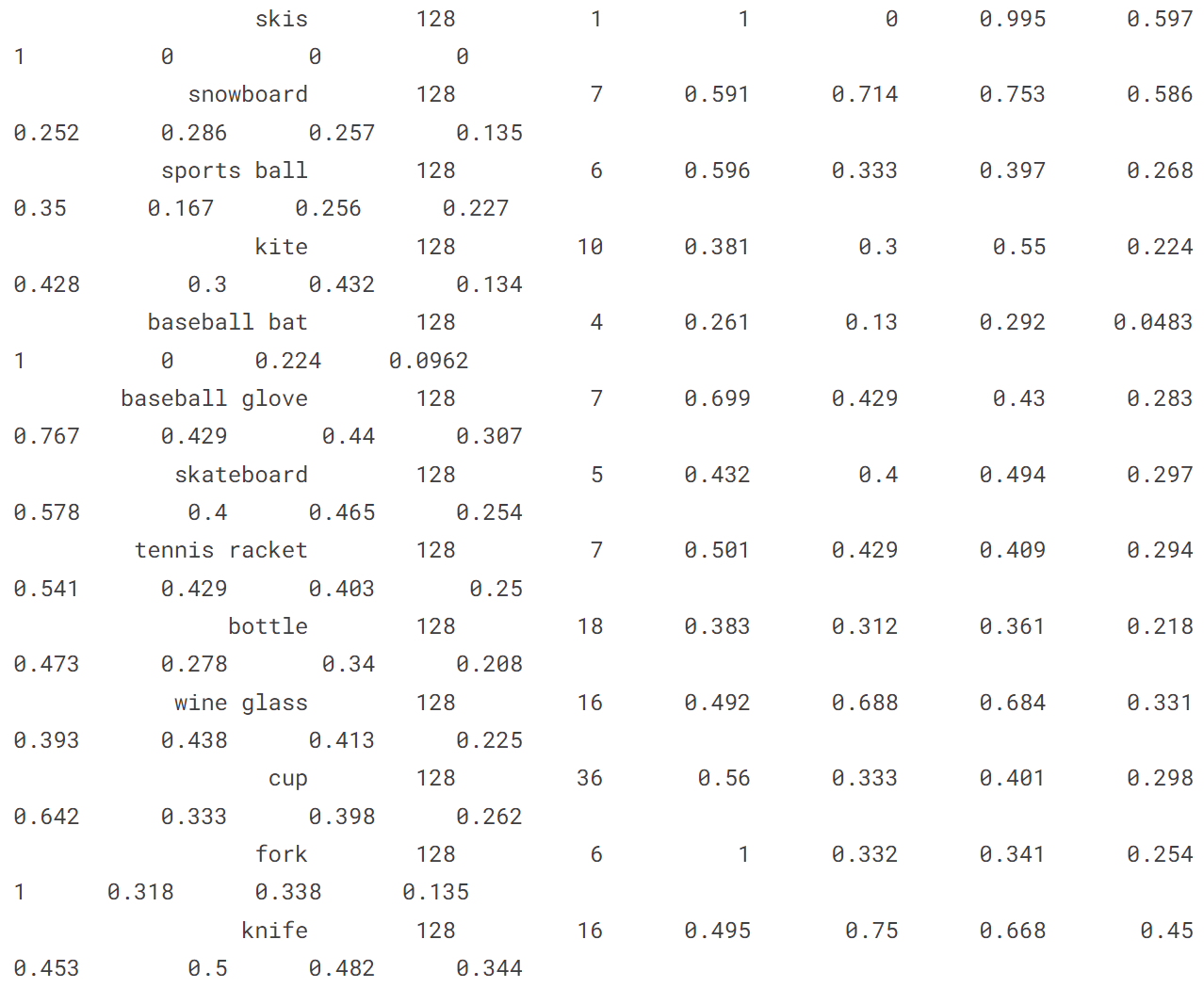
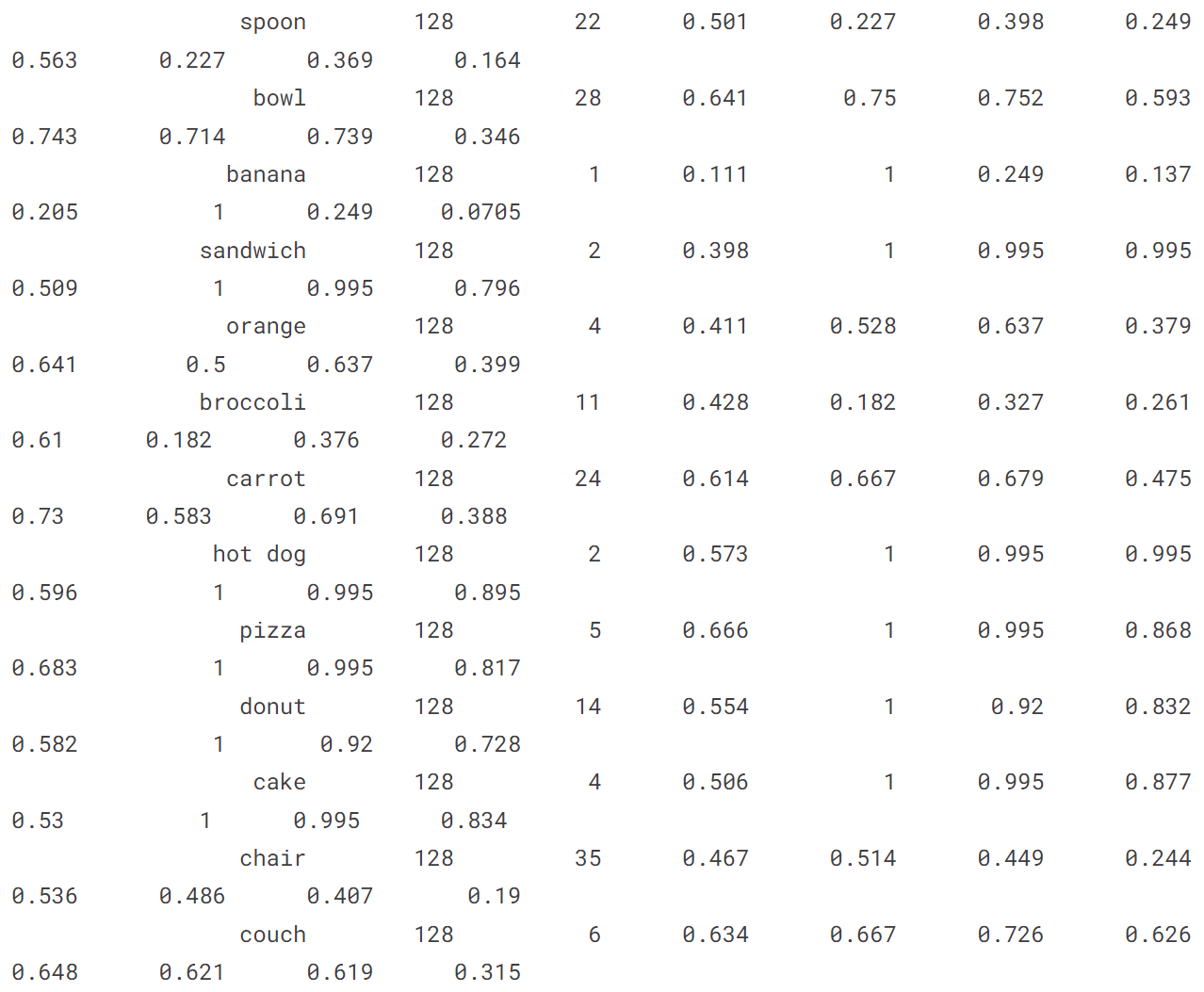
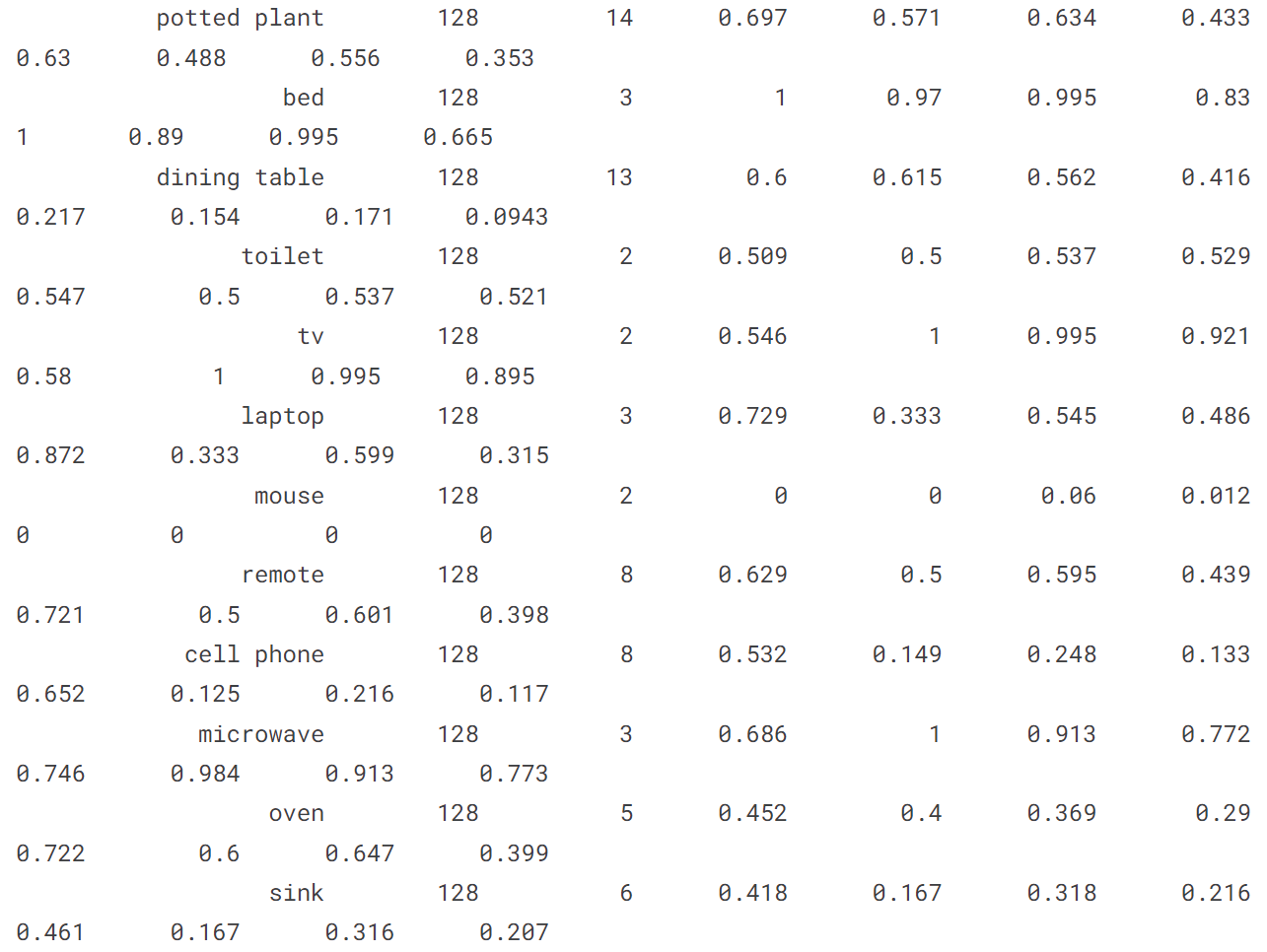

[ultralytics.yolo.engine.results.Results object with attributes:
boxes: ultralytics.yolo.engine.results.Boxes object
keypoints: None
keys: ['boxes', 'masks']
masks: ultralytics.yolo.engine.results.Masks object
names: {0: 'person', 1: 'bicycle', 2: 'car', 3: 'motorcycle', 4: 'airplane', 5: 'bus', 6: 'train', 7: 'truck', 8: 'boat', 9: 'traffic light', 10: 'fire hydrant', 11: 'stop sign', 12: 'parking meter', 13: 'bench', 14: 'bird', 15: 'cat', 16: 'dog', 17: 'horse', 18: 'sheep', 19: 'cow', 20: 'elephant', 21: 'bear', 22: 'zebra', 23: 'giraffe', 24: 'backpack', 25: 'umbrella', 26: 'handbag', 27: 'tie', 28: 'suitcase', 29: 'frisbee', 30: 'skis', 31: 'snowboard', 32: 'sports ball', 33: 'kite', 34: 'baseball bat', 35: 'baseball glove', 36: 'skateboard', 37: 'surfboard', 38: 'tennis racket', 39: 'bottle', 40: 'wine glass', 41: 'cup', 42: 'fork', 43: 'knife', 44: 'spoon', 45: 'bowl', 46: 'banana', 47: 'apple', 48: 'sandwich', 49: 'orange', 50: 'broccoli', 51: 'carrot', 52: 'hot dog', 53: 'pizza', 54: 'donut', 55: 'cake', 56: 'chair', 57: 'couch', 58: 'potted plant', 59: 'bed', 60: 'dining table', 61: 'toilet', 62: 'tv', 63: 'laptop', 64: 'mouse', 65: 'remote', 66: 'keyboard', 67: 'cell phone', 68: 'microwave', 69: 'oven', 70: 'toaster', 71: 'sink', 72: 'refrigerator', 73: 'book', 74: 'clock', 75: 'vase', 76: 'scissors', 77: 'teddy bear', 78: 'hair drier', 79: 'toothbrush'}
orig_img: array([[[122, 148, 172],
[120, 146, 170],
[125, 153, 177],
...,
[157, 170, 184],
[158, 171, 185],
[158, 171, 185]],
[[127, 153, 177],
[124, 150, 174],
[127, 155, 179],
...,
[158, 171, 185],
[159, 172, 186],
[159, 172, 186]],
[[128, 154, 178],
[126, 152, 176],
[126, 154, 178],
...,
[158, 171, 185],
[158, 171, 185],
[158, 171, 185]],
...,
[[185, 185, 191],
[182, 182, 188],
[179, 179, 185],
...,
[114, 107, 112],
[115, 105, 111],
[116, 106, 112]],
[[157, 157, 163],
[180, 180, 186],
[185, 186, 190],
...,
[107, 97, 103],
[102, 92, 98],
[108, 98, 104]],
[[112, 112, 118],
[160, 160, 166],
[169, 170, 174],
...,
[ 99, 89, 95],
[ 96, 86, 92],
[102, 92, 98]]], dtype=uint8)
orig_shape: (1080, 810)
path: '/kaggle/working/bus.jpg'
probs: None
save_dir: None
speed: {'preprocess': 2.610445022583008, 'inference': 23.540735244750977, 'postprocess': 2.538442611694336}]
!yolo predict model = '/kaggle/working/runs/segment/train/weights/best.pt' source = '/kaggle/working/bus.jpg'
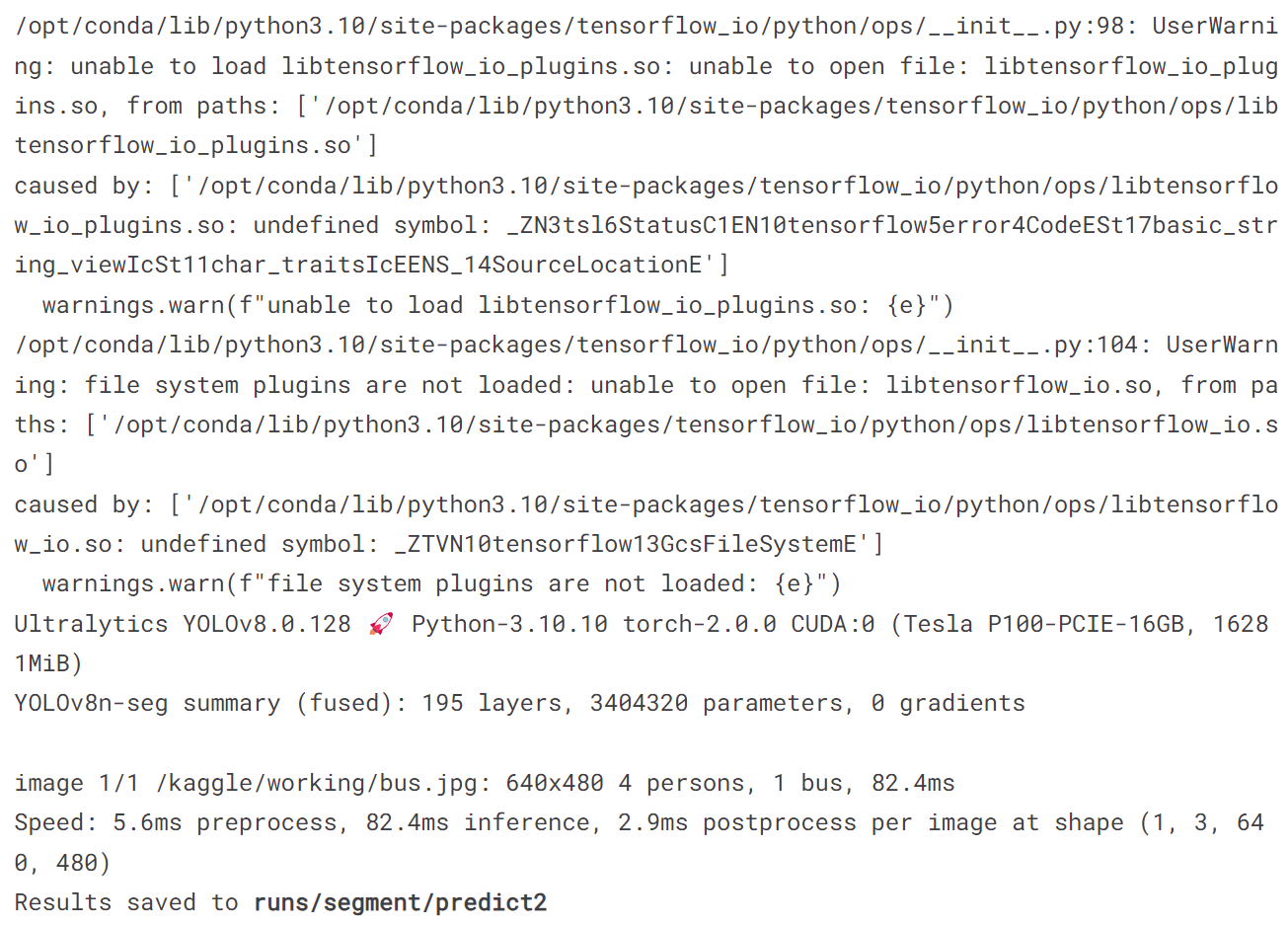
image = Image.open('/kaggle/working/runs/segment/predict2/bus.jpg')
plt.figure(figsize=(12, 8))
plt.imshow(image)
plt.axis('off')
plt.show()

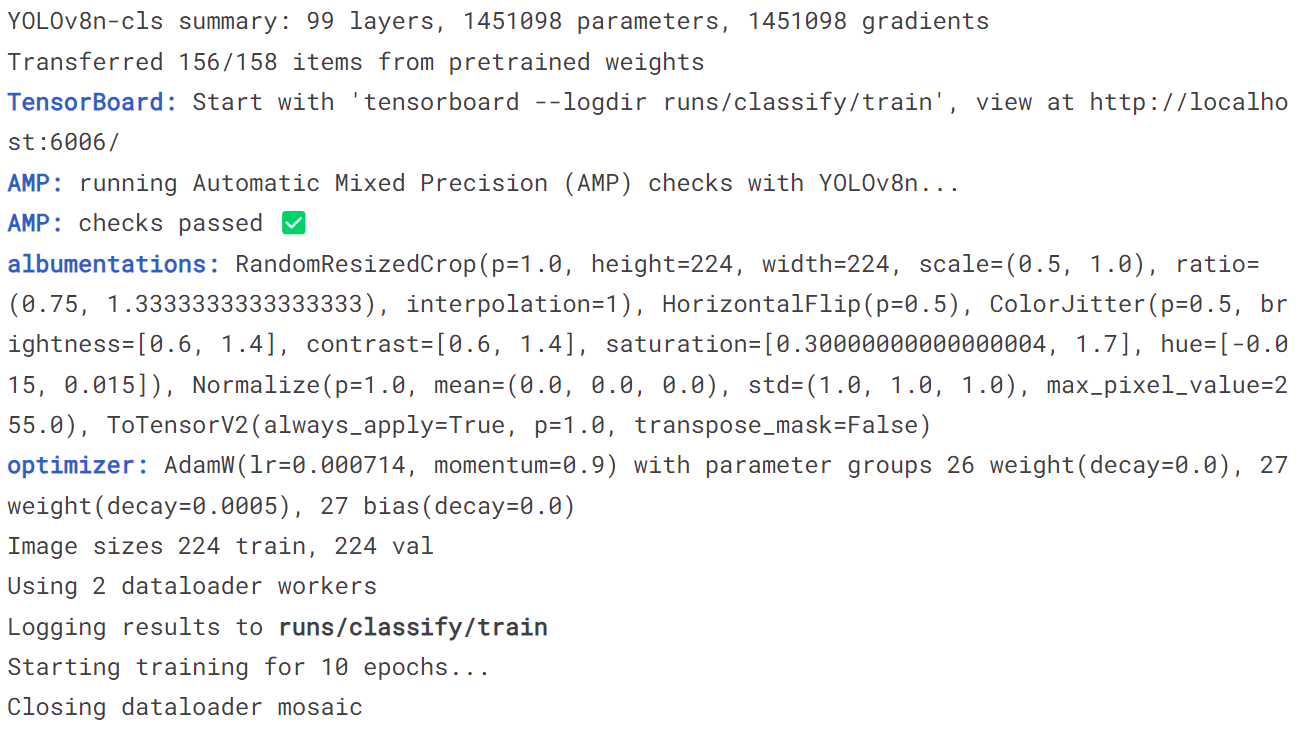
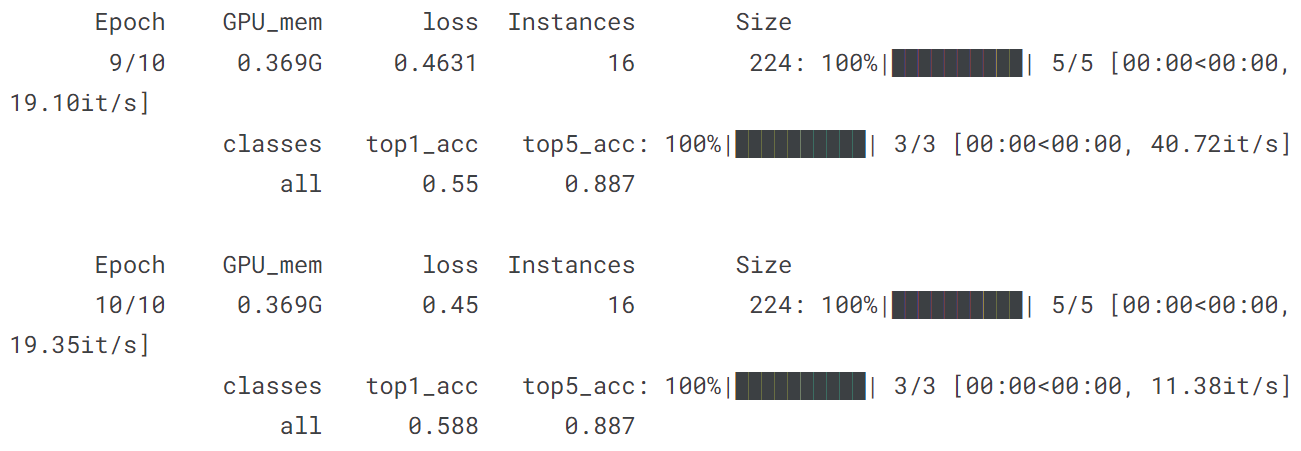
5.3 训练分类模型
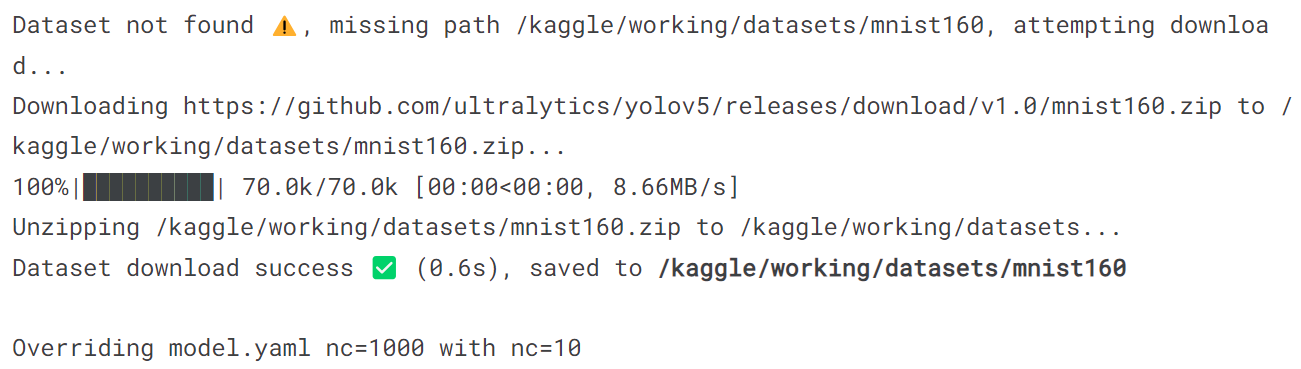
model = YOLO('yolov8n-cls.pt')
model.train(data='mnist160', epochs = 10)
model('https://ultralytics.com/images/bus.jpg')




[ultralytics.yolo.engine.results.Results object with attributes:
boxes: None
keypoints: None
keys: ['probs']
masks: None
names: {0: '0', 1: '1', 2: '2', 3: '3', 4: '4', 5: '5', 6: '6', 7: '7', 8: '8', 9: '9'}
orig_img: array([[[122, 148, 172],
[120, 146, 170],
[125, 153, 177],
...,
[157, 170, 184],
[158, 171, 185],
[158, 171, 185]],
[[127, 153, 177],
[124, 150, 174],
[127, 155, 179],
...,
[158, 171, 185],
[159, 172, 186],
[159, 172, 186]],
[[128, 154, 178],
[126, 152, 176],
[126, 154, 178],
...,
[158, 171, 185],
[158, 171, 185],
[158, 171, 185]],
...,
[[185, 185, 191],
[182, 182, 188],
[179, 179, 185],
...,
[114, 107, 112],
[115, 105, 111],
[116, 106, 112]],
[[157, 157, 163],
[180, 180, 186],
[185, 186, 190],
...,
[107, 97, 103],
[102, 92, 98],
[108, 98, 104]],
[[112, 112, 118],
[160, 160, 166],
[169, 170, 174],
...,
[ 99, 89, 95],
[ 96, 86, 92],
[102, 92, 98]]], dtype=uint8)
orig_shape: (1080, 810)
path: '/kaggle/working/bus.jpg'
probs: ultralytics.yolo.engine.results.Probs object
save_dir: None
speed: {'preprocess': 1.3382434844970703, 'inference': 2.797365188598633, 'postprocess': 0.07772445678710938}]
!yolo predict model = '/kaggle/working/runs/classify/train/weights/best.pt' source = '/kaggle/working/bus.jpg'
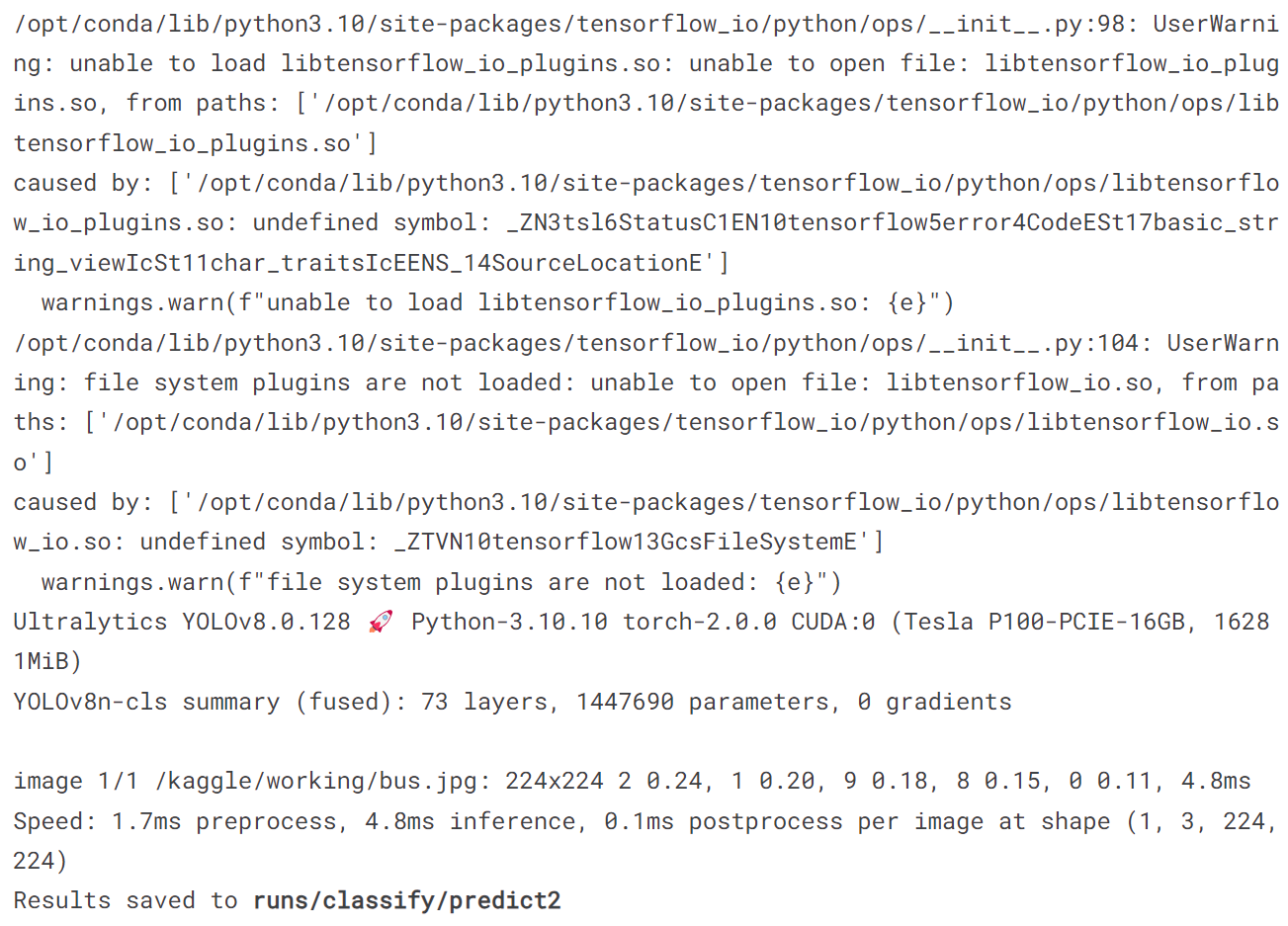
image = Image.open('/kaggle/working/runs/classify/predict2/bus.jpg')
plt.figure(figsize=(12, 8))
plt.imshow(image)
plt.axis('off')
plt.show()

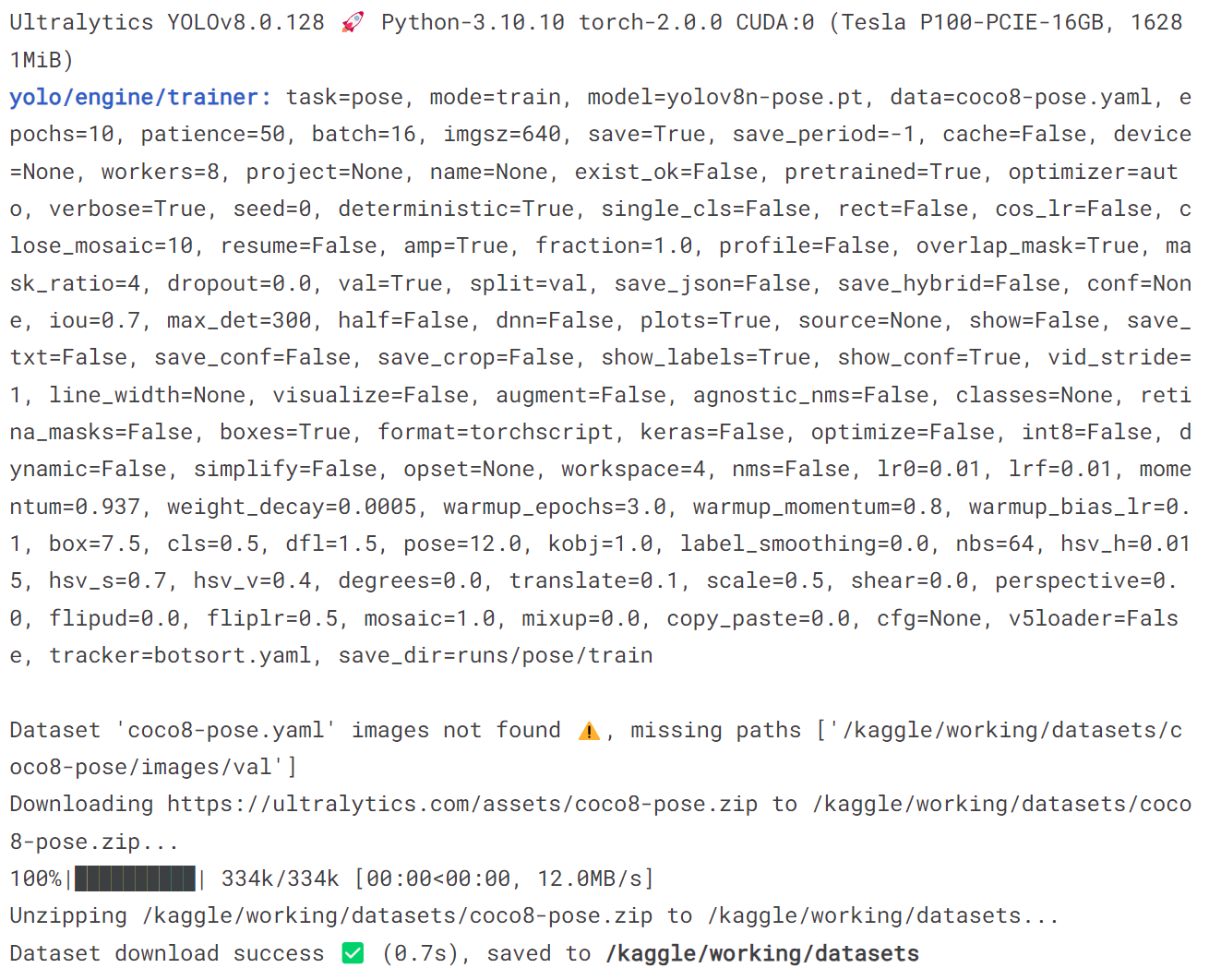
5.4 训练pose模型
model = YOLO('yolov8n-pose.pt')
model.train(data='coco8-pose.yaml', epochs = 10)
model('https://ultralytics.com/images/bus.jpg')

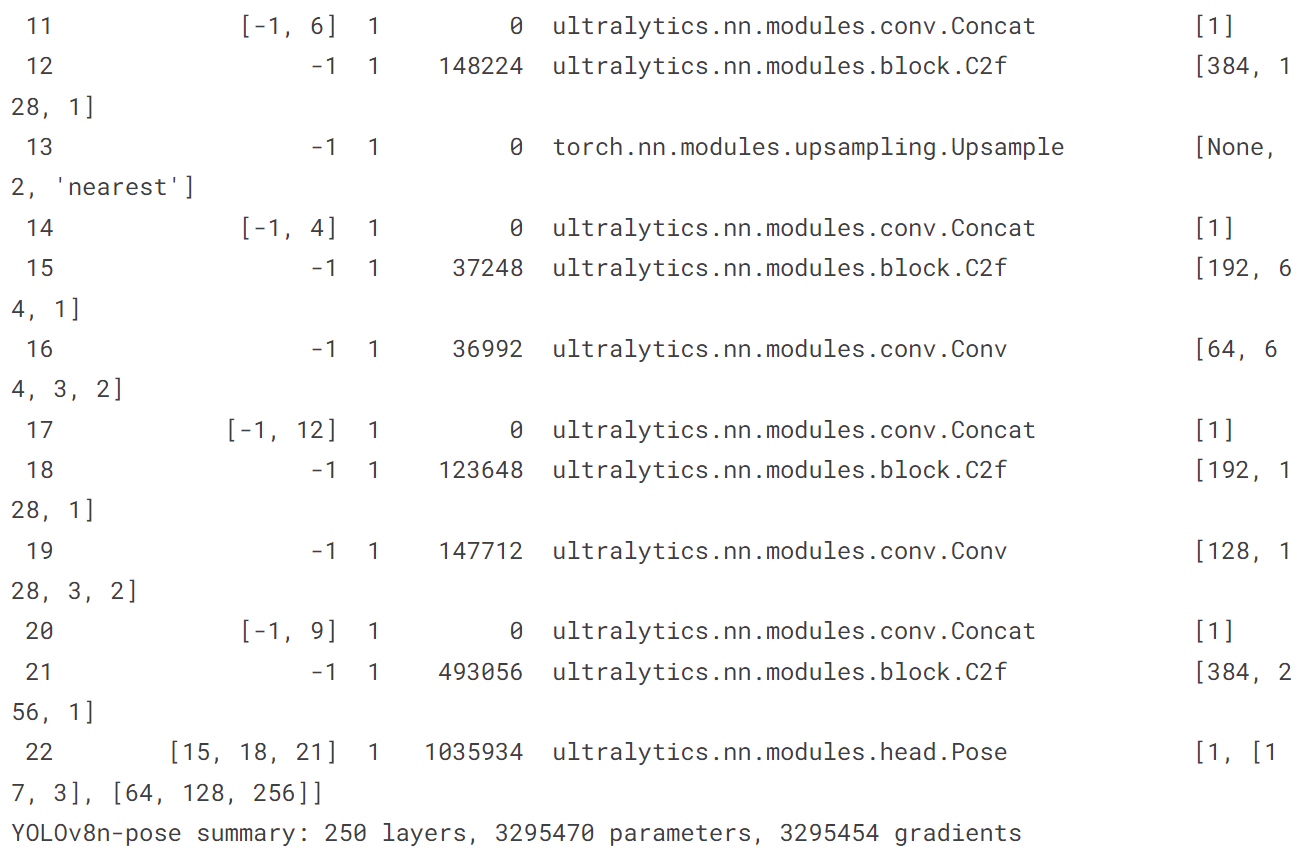
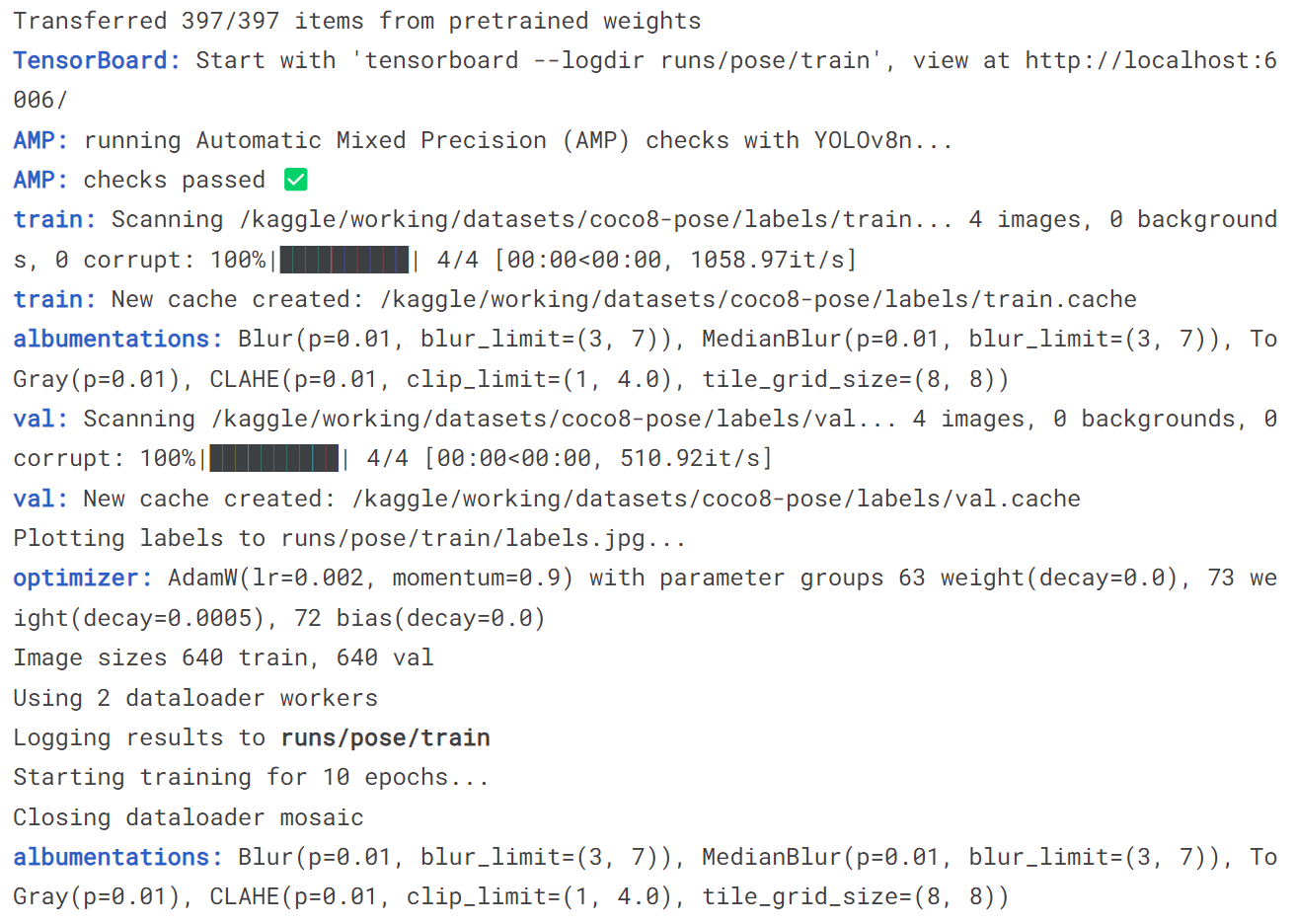




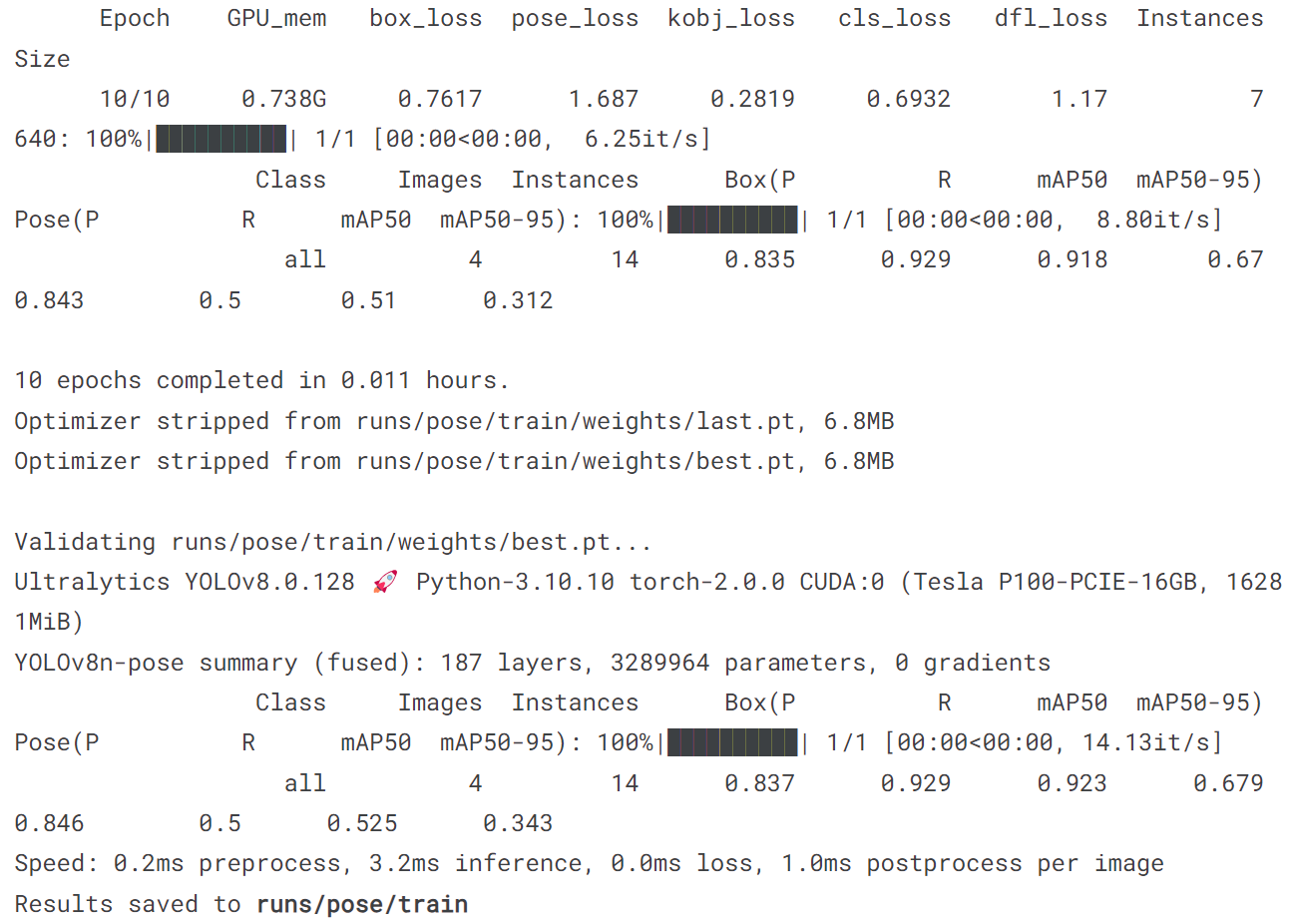

[ultralytics.yolo.engine.results.Results object with attributes:
boxes: ultralytics.yolo.engine.results.Boxes object
keypoints: ultralytics.yolo.engine.results.Keypoints object
keys: ['boxes', 'keypoints']
masks: None
names: {0: 'person'}
orig_img: array([[[122, 148, 172],
[120, 146, 170],
[125, 153, 177],
...,
[157, 170, 184],
[158, 171, 185],
[158, 171, 185]],
[[127, 153, 177],
[124, 150, 174],
[127, 155, 179],
...,
[158, 171, 185],
[159, 172, 186],
[159, 172, 186]],
[[128, 154, 178],
[126, 152, 176],
[126, 154, 178],
...,
[158, 171, 185],
[158, 171, 185],
[158, 171, 185]],
...,
[[185, 185, 191],
[182, 182, 188],
[179, 179, 185],
...,
[114, 107, 112],
[115, 105, 111],
[116, 106, 112]],
[[157, 157, 163],
[180, 180, 186],
[185, 186, 190],
...,
[107, 97, 103],
[102, 92, 98],
[108, 98, 104]],
[[112, 112, 118],
[160, 160, 166],
[169, 170, 174],
...,
[ 99, 89, 95],
[ 96, 86, 92],
[102, 92, 98]]], dtype=uint8)
orig_shape: (1080, 810)
path: '/kaggle/working/bus.jpg'
probs: None
save_dir: None
speed: {'preprocess': 2.290487289428711, 'inference': 22.292375564575195, 'postprocess': 1.9459724426269531}]
!yolo predict model = '/kaggle/working/runs/pose/train/weights/best.pt' source = '/kaggle/working/bus.jpg'
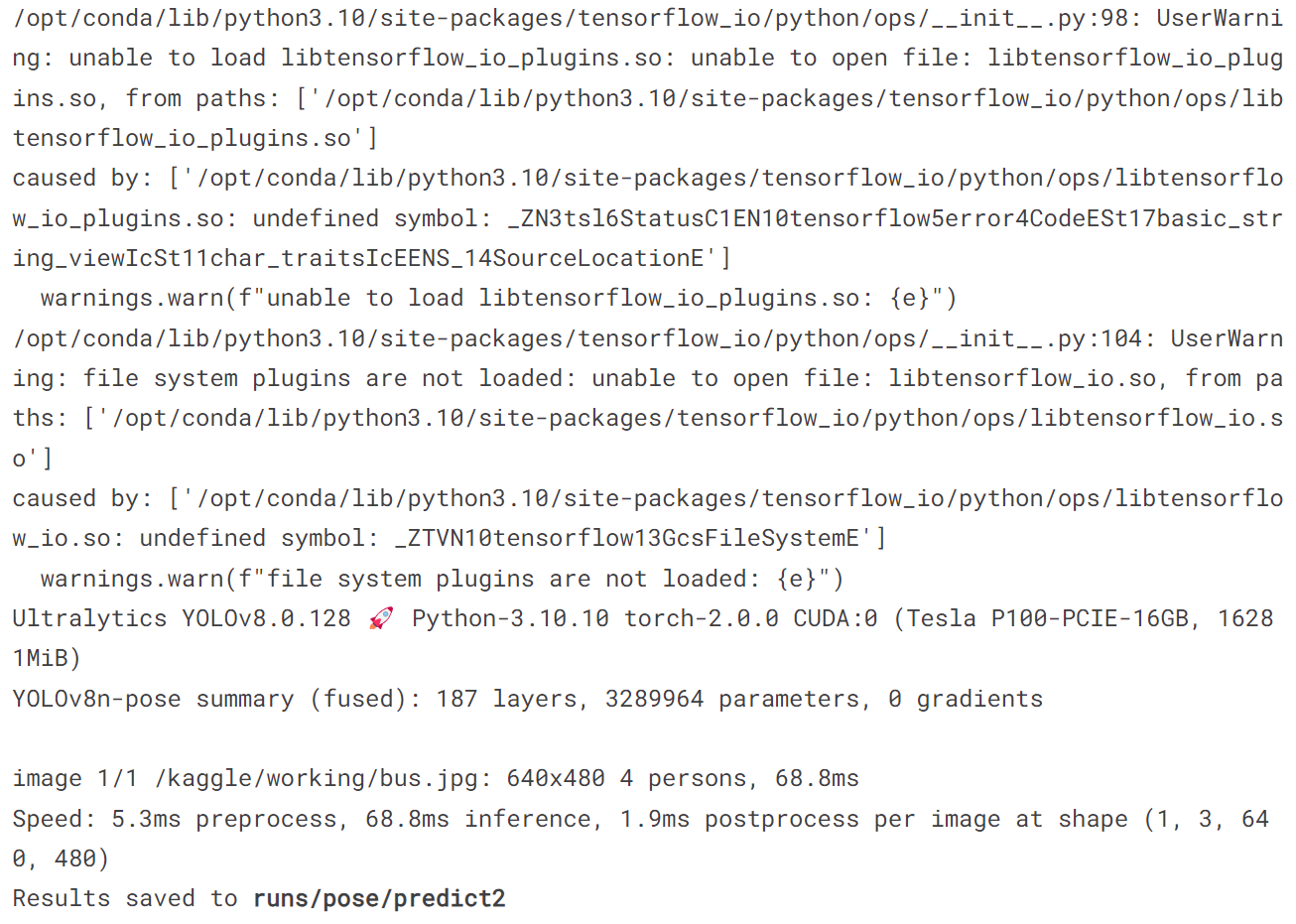
image = Image.open('/kaggle/working/runs/pose/predict2/bus.jpg')
plt.figure(figsize=(12, 8))
plt.imshow(image)
plt.axis('off')
plt.show()

这两年,IT行业面临经济周期波动与AI产业结构调整的双重压力,确实有很多运维与网络工程师因企业缩编或技术迭代而暂时失业。
很多人都在提运维网工失业后就只能去跑滴滴送外卖了,但我想分享的是,对于运维人员来说,即便失业以后仍然有很多副业可以尝试。
网工/运维/测试副业方向
运维网工,千万不要再错过这些副业机会!
第一个是知识付费类副业:输出经验打造个人IP
在线教育平台讲师
操作路径:在慕课网、极客时间等平台开设《CCNA实战》《Linux运维从入门到精通》等课程,或与培训机构合作录制专题课。
收益模式:课程销售分成、企业内训。
技术博客与公众号运营
操作路径:撰写网络协议解析、故障排查案例、设备评测等深度文章,通过公众号广告、付费专栏及企业合作变现。
收益关键:每周更新2-3篇原创,结合SEO优化与社群运营。
第二个是技术类副业:深耕专业领域变现
企业网络设备配置与优化服务
操作路径:为中小型企业提供路由器、交换机、防火墙等设备的配置调试、性能优化及故障排查服务。可通过本地IT服务公司合作或自建线上接单平台获客。
收益模式:按项目收费或签订年度维护合同。
远程IT基础设施代维
操作路径:通过承接服务器监控、日志分析、备份恢复等远程代维任务。适合熟悉Zabbix、ELK等技术栈的工程师。
收益模式:按工时计费或包月服务。
网络安全顾问与渗透测试
操作路径:利用OWASP Top 10漏洞分析、Nmap/BurpSuite等工具,为企业提供漏洞扫描、渗透测试及安全加固方案。需考取CISP等认证提升资质。
收益模式:单次渗透测试报告收费;长期安全顾问年费。
比如不久前跟我一起聊天的一个粉丝,他自己之前是大四实习的时候做的运维,发现运维7*24小时待命受不了,就准备转网安,学了差不多2个月,然后开始挖漏洞,光是补天的漏洞奖励也有个四五千,他说自己每个月的房租和饭钱就够了。
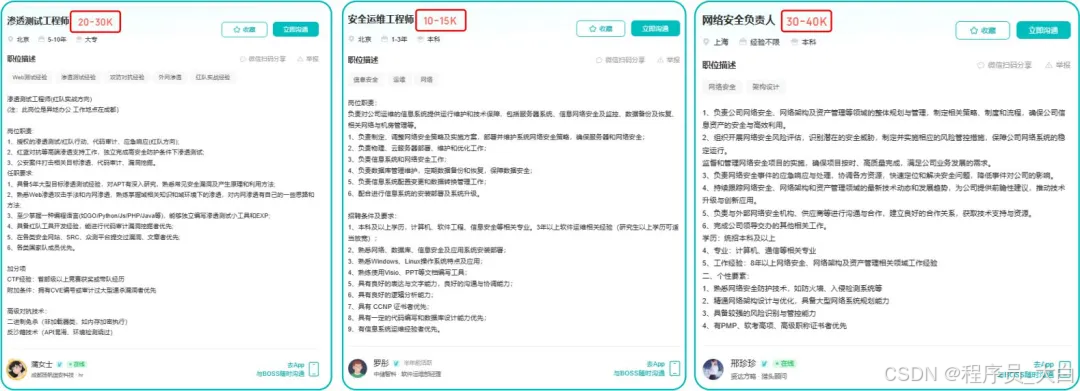
为什么我会推荐你网安是运维和网工测试人员的绝佳副业&转型方向?
1.你的经验是巨大优势: 你比任何人都懂系统、网络和架构。漏洞挖掘、内网渗透、应急响应,这些核心安全能力本质上是“攻击视角下的运维”。你的运维背景不是从零开始,而是降维打击。
2.越老越吃香,规避年龄危机: 安全行业极度依赖经验。你的排查思路、风险意识和对复杂系统的理解能力,会随着项目积累而愈发珍贵,真正做到“姜还是老的辣”。
3.职业选择极其灵活: 你可以加入企业成为安全专家,可以兼职“挖洞“获取丰厚奖金,甚至可以成为自由顾问。这种多样性为你提供了前所未有的抗风险能力。
4.市场需求爆发,前景广阔: 在国家级政策的推动下,从一线城市到二三线地区,安全人才缺口正在急剧扩大。现在布局,正是抢占未来先机的黄金时刻。
网工运维测试转行学习网络安全路线
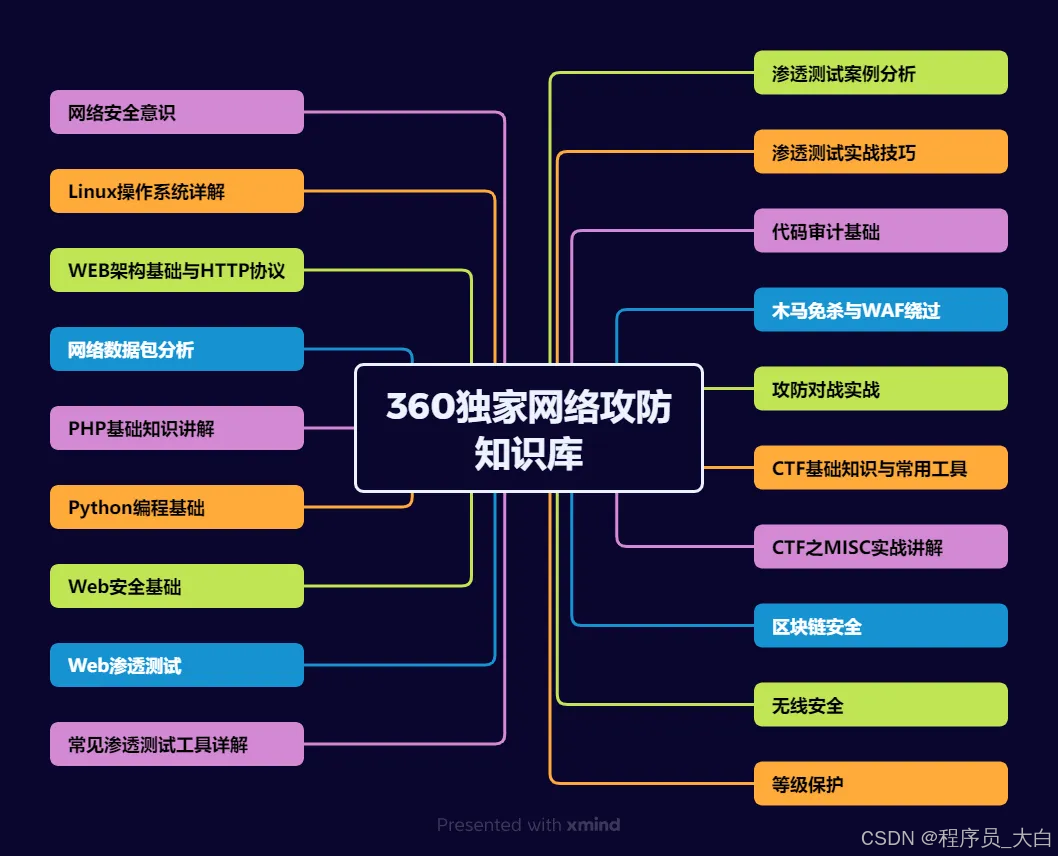
(一)第一阶段:网络安全筑基
1. 阶段目标
你已经有运维经验了,所以操作系统、网络协议这些你不是零基础。但要学安全,得重新过一遍——只不过这次我们是带着“安全视角”去学。
2. 学习内容
**操作系统强化:**你需要重点学习 Windows、Linux 操作系统安全配置,对比运维工作中常规配置与安全配置的差异,深化系统安全认知(比如说日志审计配置,为应急响应日志分析打基础)。
**网络协议深化:**结合过往网络协议应用经验,聚焦 TCP/IP 协议簇中的安全漏洞及防护机制,如 ARP 欺骗、TCP 三次握手漏洞等(为 SRC 漏扫中协议层漏洞识别铺垫)。
**Web 与数据库基础:**补充 Web 架构、HTTP 协议及 MySQL、SQL Server 等数据库安全相关知识,了解 Web 应用与数据库在网安中的作用。
**编程语言入门:**学习 Python 基础语法,掌握简单脚本编写,为后续 SRC 漏扫自动化脚本开发及应急响应工具使用打基础。
**工具实战:**集中训练抓包工具(Wireshark)、渗透测试工具(Nmap)、漏洞扫描工具(Nessus 基础版)的使用,结合模拟场景练习工具应用(掌握基础扫描逻辑,为 SRC 漏扫工具进阶做准备)。
(二)第二阶段:漏洞挖掘与 SRC 漏扫实战
1. 阶段目标
这阶段是真正开始“动手”了。信息收集、漏洞分析、工具联动,一样不能少。
熟练运用漏洞挖掘及 SRC 漏扫工具,具备独立挖掘常见漏洞及 SRC 平台漏扫实战能力,尝试通过 SRC 挖洞搞钱,不管是低危漏洞还是高危漏洞,先挖到一个。
2. 学习内容
信息收集实战:结合运维中对网络拓扑、设备信息的了解,强化基本信息收集、网络空间搜索引擎(Shodan、ZoomEye)、域名及端口信息收集技巧,针对企业级网络场景开展信息收集练习(为 SRC 漏扫目标筛选提供支撑)。
漏洞原理与分析:深入学习 SQL 注入、CSRF、文件上传等常见漏洞的原理、危害及利用方法,结合运维工作中遇到的类似问题进行关联分析(明确 SRC 漏扫重点漏洞类型)。
工具进阶与 SRC 漏扫应用:
-
系统学习 SQLMap、BurpSuite、AWVS 等工具的高级功能,开展工具联用实战训练;
-
专项学习 SRC 漏扫流程:包括 SRC 平台规则解读(如漏洞提交规范、奖励机制)、漏扫目标范围界定、漏扫策略制定(全量扫描 vs 定向扫描)、漏扫结果验证与复现;
-
实战训练:使用 AWVS+BurpSuite 组合开展 SRC 平台目标漏扫,练习 “扫描 - 验证 - 漏洞报告撰写 - 平台提交” 全流程。
SRC 实战演练:选择合适的 SRC 平台(如补天、CNVD)进行漏洞挖掘与漏扫实战,积累实战经验,尝试获取挖洞收益。
恭喜你,如果学到这里,你基本可以下班搞搞副业创收了,并且具备渗透测试工程师必备的「渗透技巧」、「溯源能力」,让你在黑客盛行的年代别背锅,工作实现升职加薪的同时也能开创副业创收!
如果你想要入坑黑客&网络安全,笔者给大家准备了一份:全网最全的网络安全资料包需要保存下方图片,微信扫码即可前往获取!
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
优快云大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享
(三)第三阶段:渗透测试技能学习
1. 阶段目标
全面掌握渗透测试理论与实战技能,能够独立完成渗透测试项目,编写规范的渗透测试报告,具备渗透测试工程师岗位能力,为护网红蓝对抗及应急响应提供技术支撑。
2. 学习内容
渗透测试核心理论:系统学习渗透测试流程、方法论及法律法规知识,明确渗透测试边界与规范(与红蓝对抗攻击边界要求一致)。
实战技能训练:开展漏洞扫描、漏洞利用、电商系统渗透测试、内网渗透、权限提升(Windows、Linux)、代码审计等实战训练,结合运维中熟悉的系统环境设计测试场景(强化红蓝对抗攻击端技术能力)。
工具开发实践:基于 Python 编程基础,学习渗透测试工具开发技巧,开发简单的自动化测试脚本(可拓展用于 SRC 漏扫自动化及应急响应辅助工具)。
报告编写指导:学习渗透测试报告的结构与编写规范,完成多个不同场景的渗透测试报告撰写练习(与 SRC 漏洞报告、应急响应报告撰写逻辑互通)。
(四)第四阶段:企业级安全攻防(含红蓝对抗)、应急响应
1. 阶段目标
掌握企业级安全攻防、护网红蓝对抗及应急响应核心技能,考取网安行业相关证书。
2. 学习内容
护网红蓝对抗专项:
-
红蓝对抗基础:学习护网行动背景、红蓝对抗规则(攻击范围、禁止行为)、红蓝双方角色职责(红队:模拟攻击;蓝队:防御检测与应急处置);
-
红队实战技能:强化内网渗透、横向移动、权限维持、免杀攻击等高级技巧,模拟护网中常见攻击场景;
-
蓝队实战技能:学习安全设备(防火墙、IDS/IPS、WAF)联动防御配置、安全监控平台(SOC)使用、攻击行为研判与溯源方法;
-
模拟护网演练:参与团队式红蓝对抗演练,完整体验 “攻击 - 检测 - 防御 - 处置” 全流程。
应急响应专项: -
应急响应流程:学习应急响应 6 步流程(准备 - 检测 - 遏制 - 根除 - 恢复 - 总结),掌握各环节核心任务;
-
实战技能:开展操作系统入侵响应(如病毒木马清除、异常进程终止)、数据泄露应急处置、漏洞应急修补等实战训练;
-
工具应用:学习应急响应工具(如 Autoruns、Process Monitor、病毒分析工具)的使用,提升处置效率;
-
案例复盘:分析真实网络安全事件应急响应案例(如勒索病毒事件),总结处置经验。
其他企业级攻防技能:学习社工与钓鱼、CTF 夺旗赛解析等内容,结合运维中企业安全防护需求深化理解。
证书备考:针对网安行业相关证书考试内容(含红蓝对抗、应急响应考点)进行专项复习,参加模拟考试,查漏补缺。
运维网工测试转行网络攻防知识库分享
网络安全这行,不是会几个工具就能搞定的。你得有体系,懂原理,能实战。尤其是从运维转过来的,别浪费你原来的经验——你比纯新人强多了。
但也要沉得住气,别学了两天Web安全就觉得自己是黑客了。内网、域渗透、代码审计、应急响应,要学的还多着呢。
如果你真的想转,按这个路子一步步走,没问题。如果你只是好奇,我劝你再想想——这行要持续学习,挺累的,但也是真有意思。
关于如何学习网络安全,笔者也给大家整理好了全套网络安全知识库,需要的可以扫码获取!
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
优快云大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享
1、网络安全意识
2、Linux操作系统
3、WEB架构基础与HTTP协议
4、Web渗透测试
5、渗透测试案例分享
6、渗透测试实战技巧

7、攻防对战实战
8、CTF之MISC实战讲解
关于如何学习网络安全,笔者也给大家整理好了全套网络安全知识库,需要的可以扫码获取!
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取


















 461
461

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









