







数据中心运维工作普遍不受重视,不像客户市场工作那样灵活,不像设计建设工作那样有成就感,但却承担着巨大的压力和责任。周而复始,枯燥单调,还会遇到各种挑战和困难,背锅和道歉已经成为常态。
通常情况下,我们提到数据中心运维工作,主要是从IDC服务商的角度考虑,更多是指基础设施的运维工作,也就是风火水电。随着业务的融合和发展,越来越多的数据中心服务商成为云服务商和智算服务商,也就包括了对物理资源、虚拟资源、平台资源、应用和数据的运维管理工作。

图片为AI生成
同时,随着数据中心从传统的数据机房向着园区化方向发展,运维工作也从最初的电气、暖通、监控、IT、网络、资源等专业,扩展增加了消防、安防、保洁等原物业相关专业。
在实际工作中,不同的数据中心会根据自身管理需求和业务情况,对运维工作进行不同的定位。现阶段主要是两种模式,一种是将基础设施和物业相关专业放在一起,另一种是把平台等业务系统也纳入进来,做成大运维,集中管理和调度。
数据中心运维工作中具有很多特点,这里只是列举了其中7个比较典型特点,欢迎补充。
一、运维工作绝不是被动救火
数据中心运维绝不是出现问题后的被动救火,更应该是通过良好的维护,确保运营的质量、稳定和安全。通过对隐患、事故的全面管控,做好事故发生前的预防,降低事故发生的概率,通过完善的应急管理体系降低事故发生后产生的影响。

图片来源于网络
运维绝不是被动救火,更应该是防患于未然,运维管理对风险隐患管控思路的演进可分为四个阶段:
①发生事故的被动处理,②风险隐患的主动排查,③风险隐患的早期预警,④风险隐患的主动预防。
逐步将关口前移才是风险管控应该有的样子,但是由于专业性和复杂性,现阶段大部分数据中心还处于被动处理和主动排查的第一二阶段,很少能真正做到早期预警的,而主动预防更是少之又少。
二、99.5分也是不及格
《战国策·秦策五》是说到“行百里者半九十”,运维工作也是一样,严格意义上讲,99.5分很可能意味着不及格。
可用率是一项比较重要的运维指标,一个可用率为99.99%的系统,每年换算的平均故障时间约等于52.56分钟,但这不意味着每年此系统可以出现52.56分钟的故障。99.99%的可用率看着挺高,如果出现影响业务类的故障,哪怕只是出现1秒钟中断,也可能面临客户严格的SLA考核,面临费用减免甚至赔偿。
运维工作做的就是细节工作,要做到的就是精益求精,尽可能的确保100%的可用率。
三、默默无闻就是常态
运维工作不受重视、没有好评、默默无闻是常态。当一切正常时,面对运维团队,管理者只会想到降本增效,心里会想“真搞不懂雇你们来干嘛”。当出现问题时,管理者不会深究问题的原因出在设计、建设还是运维上,还会想“真搞不懂雇你们来干嘛”。
一个每天忙忙碌碌,需要加班加点处理无数问题的运维团队,和一个每天按部就班,没有过多紧急事件需要处理的团队,哪一个团队更好?实际上,会哭的孩子有奶吃在哪里都是真理。

3分建设,7分运维,运维阶段要面对能耗双控、绿色低碳、环评、成本、利润、安全、业务SLA等一系列问题。单一枯燥、压力巨大、长期坚持是最基本的样子。
四、故障无法彻底避免
《数据中心设计规范》(GB 50174-2017)中描述,A 级数据中心的基础设施宜按容错系统配置,当数据中心经历了一次突发设备故障或人为操作失误后,仍然可以满足IT 设备正常运行的基本需要。
无论从何种角度出发,故障都是不可避免的,故障率和pue一样,无限趋近于1,但是永远达不到1。良好的运维只能尽可能的降低故障发生的概率和频次,尽可能降低故障发生后的影响,尽可能实现业务的快速抢通修复。
故障都与人有关。与技术和责任相关,责任尤其重要。设备故障与设备自身的设计、制造、验收,售后相关,已经发现问题是否告知其他进行替换等。
对于故障,大家都有赌徒心理。管理人员在赌发生概率,赌故障不会发生,值班人员在赌故障不会发生在当班事件。
五、运维是首席背锅侠和道歉官
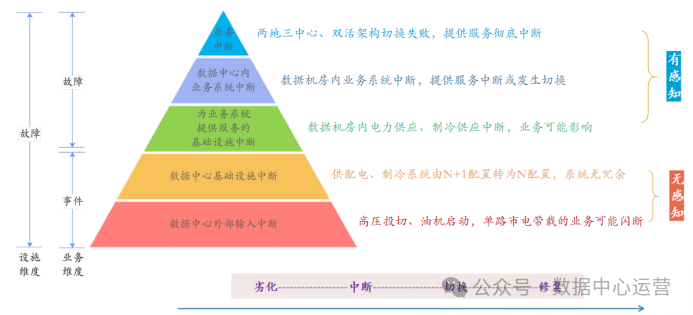
在国家标准GB/T 28827.4-2019《信息技术服务 运行维护 第4部分:数据中心服务要求》中,对数据中心所拥有的资源进行了进一步层次划分,如下图所示。

数据中心可能在多个层面出现故障,但只有基础设施部分可以归结为数据中心自身的故障,物理资源类、虚拟资源类、平台资源类、应用和数据故障都与传统的IDC没有关系。
数据中心故障影响越来越大,成本越来越高。数据中心发生故障通常会直接导致业务中断和收入损失。包括罚款、服务协议违约等商务成本,故障维修、检验检测等技术成本,以及抵消负面影响的其他成本。
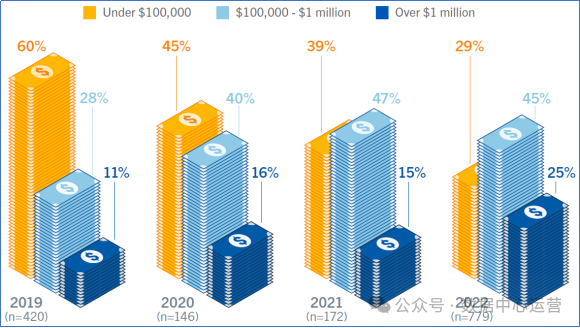
Uptime Institute Global Data Center Survey 2022
无论哪种故障,各级管理者、客户和媒体更愿意表述的是某某数据中心发生故障,引起了什么事件。而无论是客户自身问题,还是设计失误、建设质量、设备采购不达标等原因,最后基本都会被归结到运维管理方面,运维工作很容易成为首席背锅侠和首席道歉官。

六、运维人员并非越老越吃香
运维人员和其他技术类工种一样,面临这年龄上的压力。
现阶段,企业在招聘时,一方面要求运维年轻化,要求40岁甚至35岁以内的年轻人,一方面对现有50岁甚至45岁以上的运维人员进行裁员,特别是对代维人员要求更加严格。
不可否认,随着生产模式的转变,传统的运维人员需要转型才能适应新的需求,老运维人员的技术经验已经无法适应新的技术,如果积累的只是纯技术经验,而不是思维模式和处理能力的经验,那确实压力会大一些。
运维人员还是需要主动做好职业规划,可以参考《数据中心人才需求的变革趋势与招聘应对策略研究》一文,职业规划方向分为运维内部和运维外部两个方向,具体可以参考下图。
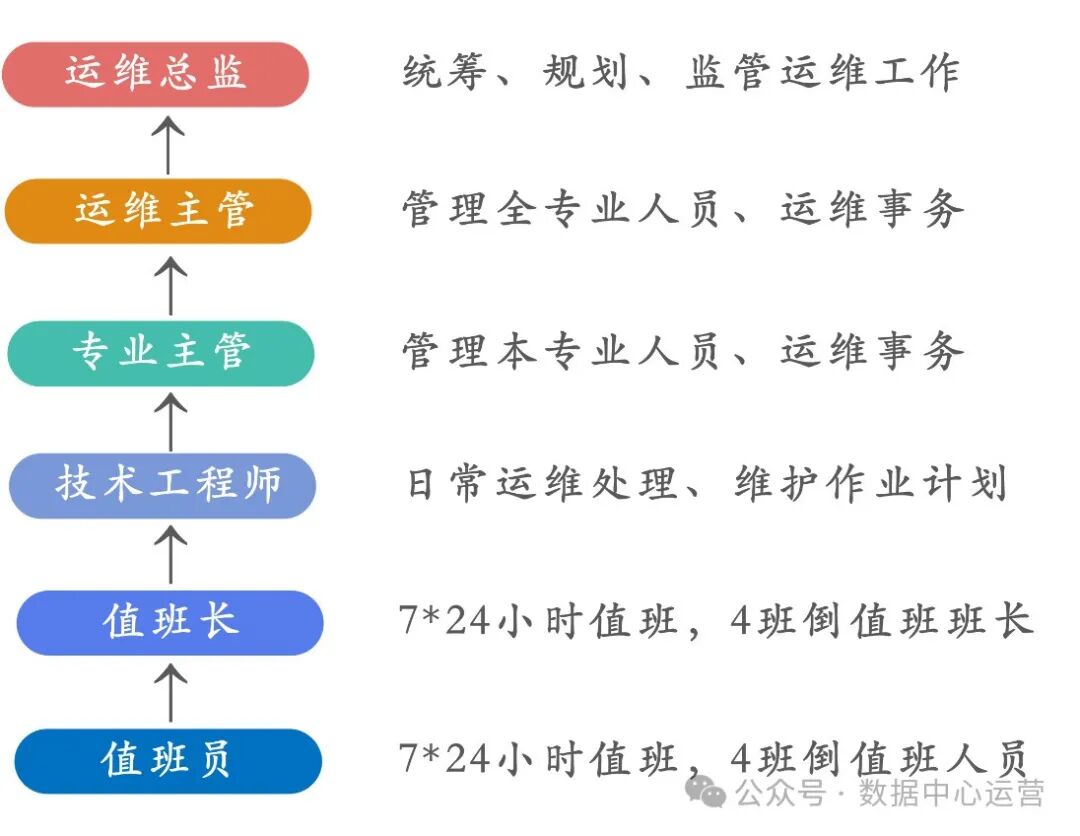
内部职业规划

外部职业规划
七、运维工作需要贯穿全生命周期
数据中心运维工作并不是从接维后才开始的,而是要贯穿数据中心规划、设计、建设、验收和运营的全过程。
设计阶段:参与架构设计、运营指标
建设阶段:把关隐蔽工程、施工质量
验收阶段:验证系统联调、关键参数
运维阶段:安全、成本、效率、质量

1.提前发现由于设计、施工期间考虑不充分导致的系统联调问题、关键参数错误、标签标识不全、运维操作不便等技术问题。
2.提前梳理需要通过成本、立项等解决的安全隐患,并在接维后第一时间解决;
3.提前调测监控系统、巡检路线、工具仪表、备品备件等维护工作
4.提前完成规章制度、标准规范、流程、规程等的制定
5.提前完成标签标识、安全警示标牌、设备资料、机历卡等资源信息的制作
6.提前完成4P文档、巡检记录、值班日志、作业计划、应急演练等日常资料的准备
7.在数据中心交付前,运维核心团队一定要以最终运维角色参与到项目验收、验证中,进行施工质量、功能验证、性能测试、资料收集、图纸整理等工作。
在数据中心规模化建设转向规模化运营的今天,高质量的运维已经成为影响数据中心持续高质量发展的重要因素。
虽然运维工作不受重视、默默无闻、经常背锅,但总需要有一群人在默默支撑着万家灯火和岁月静好。
这两年,IT行业面临经济周期波动与AI产业结构调整的双重压力,确实有很多运维与网络工程师因企业缩编或技术迭代而暂时失业。
很多人都在提运维网工失业后就只能去跑滴滴送外卖了,但我想分享的是,对于运维人员来说,即便失业以后仍然有很多副业可以尝试。
运维副业方向
运维,千万不要再错过这些副业机会!
第一个是知识付费类副业:输出经验打造个人IP
在线教育平台讲师
操作路径:在慕课网、极客时间等平台开设《CCNA实战》《Linux运维从入门到精通》等课程,或与培训机构合作录制专题课。
收益模式:课程销售分成、企业内训。
技术博客与公众号运营
操作路径:撰写网络协议解析、故障排查案例、设备评测等深度文章,通过公众号广告、付费专栏及企业合作变现。
收益关键:每周更新2-3篇原创,结合SEO优化与社群运营。
第二个是技术类副业:深耕专业领域变现
企业网络设备配置与优化服务
操作路径:为中小型企业提供路由器、交换机、防火墙等设备的配置调试、性能优化及故障排查服务。可通过本地IT服务公司合作或自建线上接单平台获客。
收益模式:按项目收费或签订年度维护合同。
远程IT基础设施代维
操作路径:通过承接服务器监控、日志分析、备份恢复等远程代维任务。适合熟悉Zabbix、ELK等技术栈的工程师。
收益模式:按工时计费或包月服务。
网络安全顾问与渗透测试
操作路径:利用OWASP Top 10漏洞分析、Nmap/BurpSuite等工具,为企业提供漏洞扫描、渗透测试及安全加固方案。需考取CISP等认证提升资质。
收益模式:单次渗透测试报告收费;长期安全顾问年费。
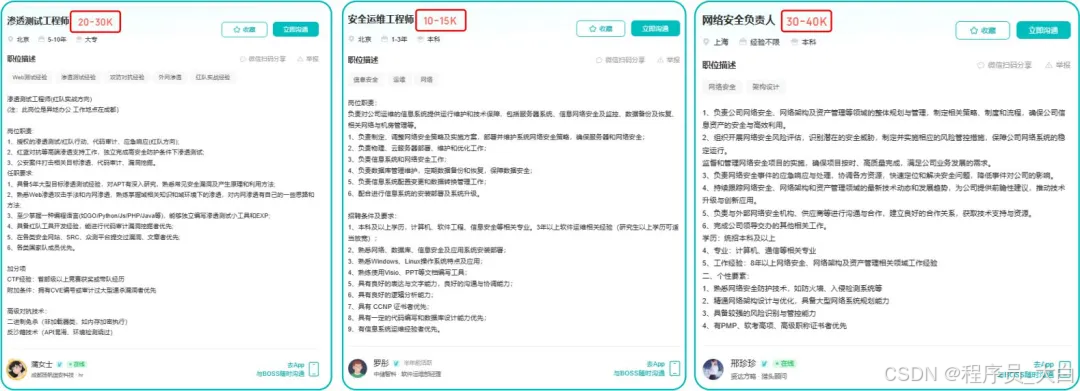
比如不久前跟我一起聊天的一个粉丝,他自己之前是大四实习的时候做的运维,发现运维7*24小时待命受不了,就准备转网安,学了差不多2个月,然后开始挖漏洞,光是补天的漏洞奖励也有个四五千,他说自己每个月的房租和饭钱就够了。
为什么我会推荐你网安是运维人员的绝佳副业&转型方向?
1.你的经验是巨大优势: 你比任何人都懂系统、网络和架构。漏洞挖掘、内网渗透、应急响应,这些核心安全能力本质上是“攻击视角下的运维”。你的运维背景不是从零开始,而是降维打击。
2.越老越吃香,规避年龄危机: 安全行业极度依赖经验。你的排查思路、风险意识和对复杂系统的理解能力,会随着项目积累而愈发珍贵,真正做到“姜还是老的辣”。
3.职业选择极其灵活: 你可以加入企业成为安全专家,可以兼职“挖洞“获取丰厚奖金,甚至可以成为自由顾问。这种多样性为你提供了前所未有的抗风险能力。
4.市场需求爆发,前景广阔: 在国家级政策的推动下,从一线城市到二三线地区,安全人才缺口正在急剧扩大。现在布局,正是抢占未来先机的黄金时刻。
运维转行学习路线
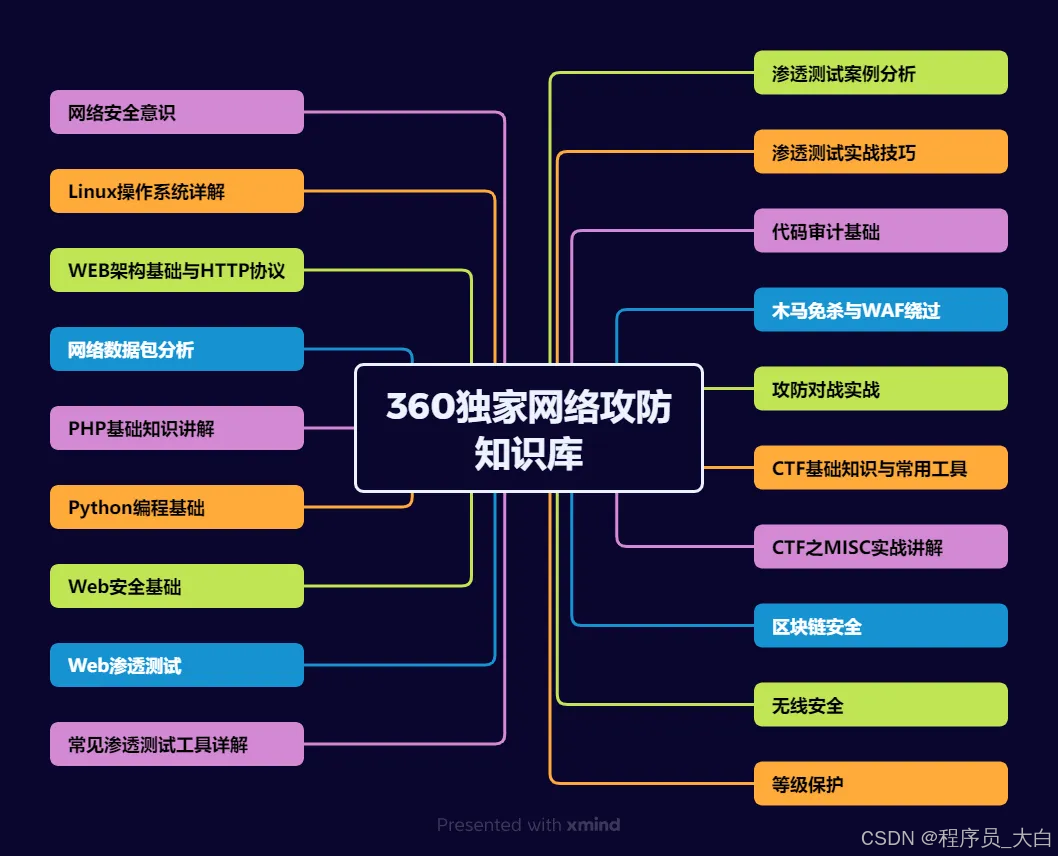
(一)第一阶段:网络安全筑基
1. 阶段目标
你已经有运维经验了,所以操作系统、网络协议这些你不是零基础。但要学安全,得重新过一遍——只不过这次我们是带着“安全视角”去学。
2. 学习内容
**操作系统强化:**你需要重点学习 Windows、Linux 操作系统安全配置,对比运维工作中常规配置与安全配置的差异,深化系统安全认知(比如说日志审计配置,为应急响应日志分析打基础)。
**网络协议深化:**结合过往网络协议应用经验,聚焦 TCP/IP 协议簇中的安全漏洞及防护机制,如 ARP 欺骗、TCP 三次握手漏洞等(为 SRC 漏扫中协议层漏洞识别铺垫)。
**Web 与数据库基础:**补充 Web 架构、HTTP 协议及 MySQL、SQL Server 等数据库安全相关知识,了解 Web 应用与数据库在网安中的作用。
**编程语言入门:**学习 Python 基础语法,掌握简单脚本编写,为后续 SRC 漏扫自动化脚本开发及应急响应工具使用打基础。
**工具实战:**集中训练抓包工具(Wireshark)、渗透测试工具(Nmap)、漏洞扫描工具(Nessus 基础版)的使用,结合模拟场景练习工具应用(掌握基础扫描逻辑,为 SRC 漏扫工具进阶做准备)。
(二)第二阶段:漏洞挖掘与 SRC 漏扫实战
1. 阶段目标
这阶段是真正开始“动手”了。信息收集、漏洞分析、工具联动,一样不能少。
熟练运用漏洞挖掘及 SRC 漏扫工具,具备独立挖掘常见漏洞及 SRC 平台漏扫实战能力,尝试通过 SRC 挖洞搞钱,不管是低危漏洞还是高危漏洞,先挖到一个。
2. 学习内容
信息收集实战:结合运维中对网络拓扑、设备信息的了解,强化基本信息收集、网络空间搜索引擎(Shodan、ZoomEye)、域名及端口信息收集技巧,针对企业级网络场景开展信息收集练习(为 SRC 漏扫目标筛选提供支撑)。
漏洞原理与分析:深入学习 SQL 注入、CSRF、文件上传等常见漏洞的原理、危害及利用方法,结合运维工作中遇到的类似问题进行关联分析(明确 SRC 漏扫重点漏洞类型)。
工具进阶与 SRC 漏扫应用:
-
系统学习 SQLMap、BurpSuite、AWVS 等工具的高级功能,开展工具联用实战训练;
-
专项学习 SRC 漏扫流程:包括 SRC 平台规则解读(如漏洞提交规范、奖励机制)、漏扫目标范围界定、漏扫策略制定(全量扫描 vs 定向扫描)、漏扫结果验证与复现;
-
实战训练:使用 AWVS+BurpSuite 组合开展 SRC 平台目标漏扫,练习 “扫描 - 验证 - 漏洞报告撰写 - 平台提交” 全流程。
SRC 实战演练:选择合适的 SRC 平台(如补天、CNVD)进行漏洞挖掘与漏扫实战,积累实战经验,尝试获取挖洞收益。
恭喜你,如果学到这里,你基本可以下班搞搞副业创收了,并且具备渗透测试工程师必备的「渗透技巧」、「溯源能力」,让你在黑客盛行的年代别背锅,工作实现升职加薪的同时也能开创副业创收!
如果你想要入坑黑客&网络安全,笔者给大家准备了一份:全网最全的网络安全资料包需要保存下方图片,微信扫码即可前往获取!
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取