 新手入门:大模型推理能力实现与学习资源
新手入门:大模型推理能力实现与学习资源




大模型可分为推理大模型与非推理大模型两类,具体如下:
推理大模型
- 定义:在传统大语言模型的基础上,借助强化学习、神经符号推理、元学习等先进技术,强化了推理、逻辑分析和决策能力的模型。
- 优势:在逻辑推理、数学推理和实时问题解决方面表现突出,能逐步推导出复杂问题的答案。
- 示例:DeepSeek-R1、GPT-o3,二者在逻辑推理、数学推理和复杂问题解决上有卓越表现。
- 适用场景:适用于需要多步骤逻辑推导的复杂任务,如数学计算、编程问题、复杂逻辑推理等;适合用于需要深入思考且可接受较长响应时间的场景。
- 不足:计算效率较低。
非推理大模型
- 定义:侧重于语言生成、上下文理解和自然语言处理,通过对大量文本数据的训练,掌握语言规律并能生成合适内容,不强调深度推理能力的模型。
- 优势:通过直接生成答案处理任务,计算效率和响应速度具有优势。
- 示例:GPT-3、GPT-4、BERT等,主要用于语言生成、语言理解、文本分类和翻译等任务。
- 适用场景:适用于常规的文本生成任务,如自然语言回答、文章撰写、翻译、摘要和常识问答等;适合用于需要快速处理的任务。
- 不足:在处理复杂逻辑推理任务时可能表现不佳。
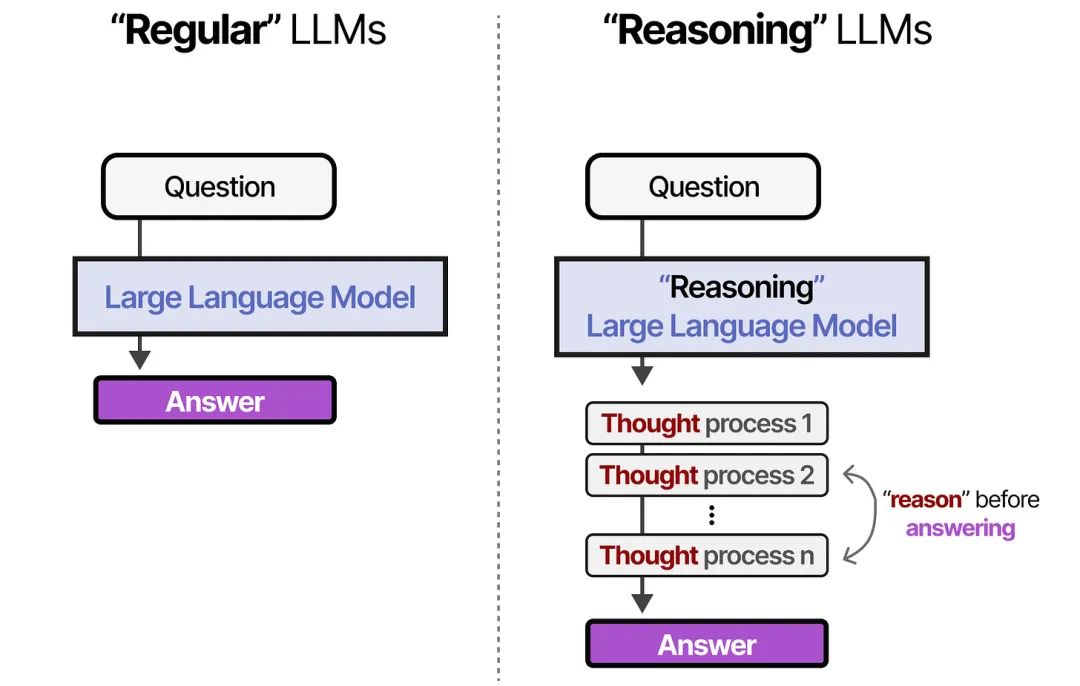
与非推理大模型相比,推理大模型的核心差异在于,在回答问题前会进行“思考”。正是这种推理能力,让人们直接感受到大模型所具备的“智”的特质。
DeepSeek-R1是一款专注于推理能力的大模型,它是全球首个能直接展示中间思考过程(即推理显示化)的大模型。其出现恰逢大模型发展从“生成”向“推理”范式转变的关键节点,不仅让人们直观领略到其强大的推理能力,在人工智能领域引发了巨大反响,也推动着大模型技术的发展重心从“生成”向“推理”进化与转变。

推理大模型擅长承担复杂任务,例如解决高级数学问题和具有挑战性的编程任务。那么,推理大模型的推理能力是如何实现的?下面从推理模型的发展历程、训练侧的推理能力提升、推理侧的推理能力提升三个方面进行尽可能的解释这个问题。
一、推理模型的发展历程
1、起源与早期发展
推理模型的概念并非一夜之间凭空出现,其根基可追溯至早期的自然语言处理(NLP)研究。在NLP领域,研究人员长期致力于使计算机能够理解、生成和处理人类语言。然而,传统的NLP方法在处理复杂推理任务时显得力不从心。例如,在数学问题求解、代码生成等需要深度逻辑推理的任务中,传统模型往往难以给出准确答案。
为了突破这一局限,研究人员开始探索新的模型架构和训练方法。其中,基于大规模预训练语言模型(LLM)的推理模型逐渐成为了研究的焦点。LLM通过在海量文本数据上进行预训练,学习到了丰富的语言知识和语义表示,为后续的推理任务提供了强大的基础。
2、技术演进
闭源推理阶段: 2024年9月,OpenAI发布了o1-preview和o1-mini模型,标志着推理大模型正式成为一个新的大模型类别,大模型发展进入了推理时代。与非推理大模型相比,o1系列模型在回答问题之前会进行“思考”,即通过生成较长的思维链来逐步推导答案。o1系列模型的出现具有里程碑式的意义,它展示了推理模型在解决复杂推理任务方面的潜力。
o1系列模型会“思考”的能力所带来重要意义有两个方面:一方面,它证明了推理模型在特定领域的有效性,推理模型可以非常准确地解决可验证的任务——例如数学和编码任务;另一方面,也激发了研究人员对推理模型进一步优化和完善的热情。随后,其他公司和研究机构也纷纷加入了推理模型的研发行列,推动了该领域的快速发展。
开源推理阶段: 2025年1月,DeepSeek发布了DeepSeek-R1推理大模型,标志着推理大模型进入了普及开发和应用阶段。作为一款由中国企业研发的、免费的、开源的、低成本训练的、性能比肩OpenAI-o1正式版的大模型,DeepSeek-R1的出现,让推理大模型的技术实现不再神秘:在它的技术报告中第一次清晰完整的描述了推理模型的实现过程,揭示了创建强大推理模型的完整过程,提供了足够的技术细节以便让其他厂商进行复制实现。
DeepSeek-R1在推理能力、多语言支持和训练成本等方面均取得了显著突破。在AIME 2024基准测试中,DeepSeek-R1取得了79.8%的pass@1得分,略微超过了OpenAI的o1-1217模型。在MATH-500测试中,DeepSeek-R1更是取得了97.3%的出色成绩,远超其他模型。此外,DeepSeek-R1还在编程相关任务中展现出了强大的实力,如在代码竞赛任务中表现优异。
二、训练侧的推理能力提升
下面以DeepSeek-R1推理模型的训练过程为例,陈述推理大模型的推理能力的训练过程。
在了解训练R1模型的过程之前,这里先介绍一下所用到的两个DeepSeek模型:
DeepSeek-V3: V3是一个671B参数的混合专家(MoE)模型。为了提高训练和推理效率,V3的设计进行了一系列的优化。
DeepSeek-R1-Zero: R1-Zero的训练基于V3基础模型,直接通过准备的高质量的长思维链数据(CoT Data)进行强化学习训练。这个模型的神奇之处在于,它训练的时候,居然不用“监督数据”,也就是没有“老师”在旁边告诉它对错,自己通过强化学习就能慢慢变强,就像一个特别自律的孩子,没有家长和老师盯着,自己就能努力学习进步,它所使用的强化学习算法为GRPO。
R1-Zero是DeepSeek的第一个推理模型,该模型纯粹通过大规模的强化学习进行推理,无需任何监督微调(SFT)。该模型会自然探索并学习利用长思维链(Long CoT)通过强化学习解决复杂的推理问题,并出现了“顿悟”时刻。R1-Zero证明了无需监督训练即可开发推理能力。
R1推理模型训练大体分为四个阶段,其中包括两个有监督微调(SFT)阶段和两个强化学习(RL)阶段。每个SFT阶段的目的是为下一步的RL阶段探索提供更好的起点。

1、第一次监督微调SFT:冷启动
使用R1-Zero模型**(小学生)**生成少量长CoT输出的推理数据,并进行人工标注(人工筛选收集),这些数据被称为“冷启动”数据,基于这些“冷启动”数据对V3模型进行监督微调(SFT),为V3植入初步推理能力,模型学会了解决推理问题的可行的初始模板,完成冷启动过程。
2、第一次强化学习:使用GRPO
根据规则奖励对,直接对大模型进行推理导向的强化学习(GRPO)训练,提升推理能力,并且进行多轮迭代,也就是说从经过一轮强化学习训练的大模型中获取大量推理数据,然后用于下一轮的大模型强化学习训练。
3、第二次监督微调:多样本
在推理导向的强化学习后,使用生成的模型收集一个大型且多样化的SFT数据集,迭代生成推理和非推理样本进行微调,增强全场景能力:
模型自生成样本:在某些逻辑推理场景里,DeepSeek也会调用自家先前或其他版本模型(如R0、V3的专家组件)生成初步解答,再由新模型进行对比学习或判分。
数据规模与多样性:通过机器自学习机制,可快速扩展到海量的问答/推理对,让模型面对多样化场景;强化学习过程中,“有错误的样本”也能成为宝贵素材,帮助模型持续纠错与收敛。
4、第二次强化学习:全场景强化学习
R1训练的最后阶段是将模型与人类偏好对齐(RLHF),同时继续训练提升其推理能力,最终生成具有强大推理能力的推理大模型DeepSeek-R1(博士生)。

三、推理侧的推理能力提升
在推理大模型中,除了训练过程赋予了大模型的“推理”能力,在推理过程中,也同样进行了优化,以使得推理大模型获得更好的”推理“能力。
1、多轮对话机制:推理Token
以OpenAI的推理大模型o1为例,o1引入了推理Token的概念:
推理模型除了输入和输出token之外还引入了推理token,模型使用这些推理token进行“思考”。在生成推理token后,模型会生成可见的补全内容作为最终答案,同时从上下文中清除推理token。
下图是用户和大模型之间的多轮对话示例。每一轮的输入和输出token被继承,而推理token被丢弃。

2、提示工程优化
推理模型的提示词和非推理模型的提示词是有很大不同的。一般来说,推理模型在高一层级(概括性好)的提示词的情况下会提供更好的结果,这与非推理模型有些不同,非推理模型通常得益于非常精确的指令。
推理模型就像一个高级同事——你可以给他们一个要实现的目标,并相信他们会解决细节问题。
非推理模型就像一个初级同事——他们将在明确的指令下表现最好,以创建特定的输出。
因此提示工程要对应进行一定的优化:
精准触发模型潜力:通过提示词明确任务目标,帮助模型快速定位推理路径。例如,在代码生成任务中,提示词需包含“生成可执行的Python函数”等明确需求。
减少冗余干预:推理模型对提示的容错性更高,过度拆解步骤可能限制其能力。例如,强行为模型预设“先计算平方和再开根号”的步骤,反而可能导致输出偏离最优解。
四、总结
推理大模型之所以拥有推理能力,根本原因在于大模型在训练过程中,通过高质量大规模逻辑数据(例如程序源代码、数学题等等)进行强化学习即可自主演化出复杂的推理能力,并出现了推理能力的“涌现”现象。
训练完成后,在使用推理大模型时再辅以Prompt优化(包括推理Token和提示词优化),进一步提升推理效果。
推理大模型不再像非推理大模型那样快速生成答案,而是像人类一样通过“长思维链”(Long CoT)分解问题、自我纠错、探索多路径解决方案,尤其在数学、编程等高难度任务中表现优异。
推理大模型的出现,使得大模型从依赖预训练的“直觉反应”转向基于逻辑的“深度思考”。与此同时,多模态大模型、Agent和开源生态的崛起,各种因素综合叠加,加速了工智能技术的发展。推理模型将加速智能体的发展,同时将加速那些更高性能和更低硬件要求的场景的应用落地,如医疗、教育、科研、法律领域等以满足更广泛的垂直领域的应用场景。
2024最新版优快云大礼包:《AGI大模型学习资源包》免费分享**
一、2025最新大模型学习路线
一个明确的学习路线可以帮助新人了解从哪里开始,按照什么顺序学习,以及需要掌握哪些知识点。大模型领域涉及的知识点非常广泛,没有明确的学习路线可能会导致新人感到迷茫,不知道应该专注于哪些内容。
我们把学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战。

L1级别:AI大模型时代的华丽登场
L1阶段:我们会去了解大模型的基础知识,以及大模型在各个行业的应用和分析;学习理解大模型的核心原理,关键技术,以及大模型应用场景;通过理论原理结合多个项目实战,从提示工程基础到提示工程进阶,掌握Prompt提示工程。

L2级别:AI大模型RAG应用开发工程
L2阶段是我们的AI大模型RAG应用开发工程,我们会去学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3级别:大模型Agent应用架构进阶实践
L3阶段:大模型Agent应用架构进阶实现,我们会去学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造我们自己的Agent智能体;同时还可以学习到包括Coze、Dify在内的可视化工具的使用。

L4级别:大模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,我们会更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调;并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

整个大模型学习路线L1主要是对大模型的理论基础、生态以及提示词他的一个学习掌握;而L3 L4更多的是通过项目实战来掌握大模型的应用开发,针对以上大模型的学习路线我们也整理了对应的学习视频教程,和配套的学习资料。
二、大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

三、大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

四、大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

五、大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









