



你是否曾想过,如果有一个工具,能够理解你的意图并自动执行复杂的网络数据抓取任务,那会怎样?ScrapeGraphAI[1] 就是这样一个工具,它利用最新的人工智能技术,让数据提取变得前所未有地简单。

ScrapeGraphAI 是一个用于网络抓取 Python 库,它使用大语言模型(LLM)和直接图为网站、文档和 XML 文件创建抓取管道。只需说出您想要提取哪些信息,它就会为您完成!
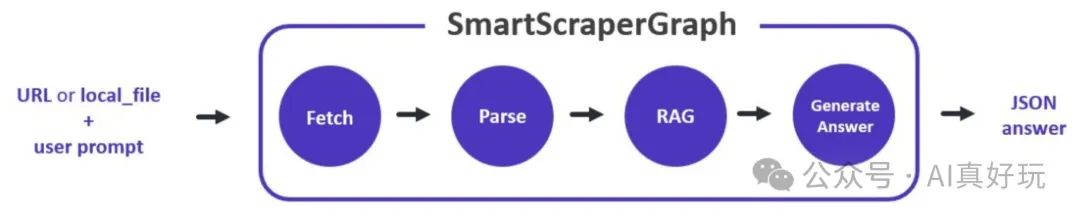
工具特点
-
简单易用:只需输入 API 密钥,您就可以在几秒钟内抓取数千个网页!
-
开发便捷:你只需要实现几行代码,工作就完成了。
-
专注业务:有了这个库,您可以节省数小时的时间,因为您只需要设置项目,人工智能就会为您完成一切。
快速开始
在线示例
1.官方 Streamlit
https://scrapegraph-ai-demo.streamlit.app/
2.Google Colab
https://colab.research.google.com/drive/1sEZBonBMGP44CtO6GQTwAlL0BGJXjtfd
本地安装
使用 pip 安装 scrapegraphai:
pip install scrapegraphai
此外,您还需要安装 Playwright[2] 抓取客户端渲染(由 JavaScript 动态渲染)的网页:
playwright install
Playwright 是一个强大的 Python 库,仅用一个 API 即可自动执行 Chromium、Firefox、WebKit 等主流浏览器自动化操作。
使用示例
ScrapeGraphAI 支持通过 API 使用不同的 LLM,例如 OpenAI、Groq、Azure 和 Gemini,或使用 Ollama 的本地模型。
ScrapeGraphAI 内置了 3 种网页爬取流程:
-
SmartScraperGraph:仅需要用户提示词和输入源的单页抓取工具; -
SearchGraph:多页抓取工具,从搜索引擎的前 n 个搜索结果中提取信息; -
SpeechGraph:单页抓取工具,从网站提取信息并生成音频文件。
示例一:使用 Ollama API 提取信息
from scrapegraphai.graphs import SmartScraperGraph graph_config = { "llm": { "model": "ollama/mistral", "temperature": 0, "format": "json", # Ollama needs the format to be specified explicitly "base_url": "http://localhost:11434", # set Ollama URL }, "embeddings": { "model": "ollama/nomic-embed-text", "base_url": "http://localhost:11434", # set Ollama URL } } smart_scraper_graph = SmartScraperGraph( prompt="List me all the articles", # also accepts a string with the already downloaded HTML code source="https://perinim.github.io/projects", config=graph_config ) result = smart_scraper_graph.run() print(result)
示例二:使用 ChatGPT API 提取信息
from scrapegraphai.graphs import SmartScraperGraph OPENAI_API_KEY = "YOUR_API_KEY" graph_config = { "llm": { "api_key": OPENAI_API_KEY, "model": "gpt-3.5-turbo", }, } smart_scraper_graph = SmartScraperGraph( prompt="List me all the articles", # also accepts a string with the already downloaded HTML code source="https://perinim.github.io/projects", config=graph_config ) result = smart_scraper_graph.run() print(result)
示例三:使用 Groq API 提取信息
from scrapegraphai.graphs import SmartScraperGraph from scrapegraphai.utils import prettify_exec_info groq_key = os.getenv("GROQ_APIKEY") graph_config = { "llm": { "model": "groq/gemma-7b-it", "api_key": groq_key, "temperature": 0 }, "embeddings": { "model": "ollama/nomic-embed-text", "temperature": 0, "base_url": "http://localhost:11434", }, "headless": False } smart_scraper_graph = SmartScraperGraph( prompt="List me all the projects with their description and the author.", source="https://perinim.github.io/projects", config=graph_config ) result = smart_scraper_graph.run() print(result)
示例四:使用 Gemini API 提取信息
from scrapegraphai.graphs import SmartScraperGraph GOOGLE_APIKEY = "YOUR_API_KEY" # Define the configuration for the graph graph_config = { "llm": { "api_key": GOOGLE_APIKEY, "model": "gemini-pro", }, } # Create the SmartScraperGraph instance smart_scraper_graph = SmartScraperGraph( prompt="List me all the articles", source="https://perinim.github.io/projects", config=graph_config ) result = smart_scraper_graph.run() print(result)
示例五、使用 Docker 提取信息
注意:使用本地模型之前记得创建 docker 容器!
docker-compose up -d docker exec -it ollama ollama pull stablelm-zephyr
您可以使用 Ollama 上可用的模型或您自己的模型来代替 stablelm-zephyr
from scrapegraphai.graphs import SmartScraperGraph。 graph_config = { "llm": { "model": "ollama/mistral", "temperature": 0, "format": "json", # Ollama needs the format to be specified explicitly # "model_tokens": 2000, # set context length arbitrarily }, } smart_scraper_graph = SmartScraperGraph( prompt="List me all the articles", # also accepts a string with the already downloaded HTML code source="https://perinim.github.io/projects", config=graph_config ) result = smart_scraper_graph.run() print(result)
随着 AI 技术的不断发展,将会为传统工具带来很大的机遇和挑战,后续会不断涌现出更多智能化的工具。
2024最新版优快云大礼包:《AGI大模型学习资源包》免费分享**
一、2025最新大模型学习路线
一个明确的学习路线可以帮助新人了解从哪里开始,按照什么顺序学习,以及需要掌握哪些知识点。大模型领域涉及的知识点非常广泛,没有明确的学习路线可能会导致新人感到迷茫,不知道应该专注于哪些内容。
我们把学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战。

L1级别:AI大模型时代的华丽登场
L1阶段:我们会去了解大模型的基础知识,以及大模型在各个行业的应用和分析;学习理解大模型的核心原理,关键技术,以及大模型应用场景;通过理论原理结合多个项目实战,从提示工程基础到提示工程进阶,掌握Prompt提示工程。

L2级别:AI大模型RAG应用开发工程
L2阶段是我们的AI大模型RAG应用开发工程,我们会去学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3级别:大模型Agent应用架构进阶实践
L3阶段:大模型Agent应用架构进阶实现,我们会去学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造我们自己的Agent智能体;同时还可以学习到包括Coze、Dify在内的可视化工具的使用。

L4级别:大模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,我们会更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调;并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

整个大模型学习路线L1主要是对大模型的理论基础、生态以及提示词他的一个学习掌握;而L3 L4更多的是通过项目实战来掌握大模型的应用开发,针对以上大模型的学习路线我们也整理了对应的学习视频教程,和配套的学习资料。
二、大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

三、大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

四、大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

五、大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取

















从零基础到精通,收藏这篇就够了!&spm=1001.2101.3001.5002&articleId=149113956&d=1&t=3&u=dae4385859084f75aee59032f6ec60db)
 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









