



引言
Embedding是 LLM 的语义支柱,它可以将原始文本转换为向量形式来方便模型理解。当你在使用 LLM 帮助您调试代码时,你的输入文本、代码会被转换为高维向量,从而将其中的语义转化成数学关系。
本文主要介绍Embedding的基础知识,带你一文了解Embedding。介绍什么是Embedding,它们是如何从统计方法演变成为当前Embedding技术的,了解它们在实践中的实现方式,并介绍总结一些最重要的Embedding技术,以及 LLM (DS-Qwen1.5B) 的Embedding在图表示中的样子。文章结构安排:
-
何为Embedding?
-
理想Embedding
-
传统Embedding
-
静态Embedding
-
上下文Embeding
-
大模型Embedding
-
DS-Qwen1.5B Embedding
-
Embedding的图理解
-
结论
何为Embedding
在自然语言处理 (NLP) 任务中,处理文本需要将每个单词转换成对应的数字表示。大多数Embedding方法都归结为将单词或标记转换为向量。各种嵌入技术之间的区别在于它们如何处理这种“单词→向量”的转换。
Embedding不仅适用于文本,还可以应用于图像、音频甚至图数据。「广义上讲,Embedding是将(任何类型的)数据转换为向量的过程」。当然,每种模态的Embedding方法都各不相同且独一无二。在本文介绍的“Embedding”,主要指的是文本Embedding。(另外嵌入技术就是Embedding技术的翻译,后面可能会出现嵌入和Embedding两种描述,其实是一个意思。)
或许你在大型语言模型的语境中听说过Embedding,但实际上Embedding的历史要悠久得多。以下是各种Embedding技术的概述:
在阅读有关Embedding的内容时,会遇到**「静态Embedding与动态(或上下文化)Embedding」。区分标记Embedding(即在 LLM 一开始就分配给输入标记的固定向量)和模型更深层生成的上下文表示至关重要。虽然从技术上讲,两者都是嵌入,「但标记Embedding是静态的,而中间隐藏状态会随着穿过模型的每一层而变化,从而捕获输入的完整上下文」**。在某些研究文献中,这些上下文输出也被称为“嵌入”,这可能会造成混淆。以下是对Embedding的技术分类图示及相关代表技术/模型,本文后面将各挑一项代表技术做详细的介绍。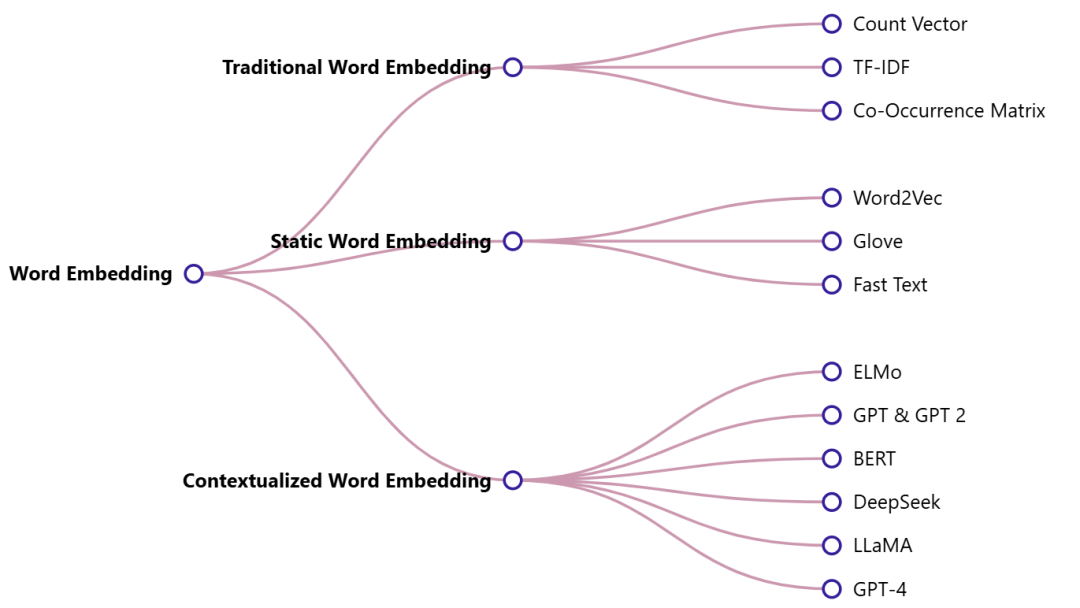
理想Embedding
对于 LLM 来说,Embedding可以被视为其语言的词典。好的Embedding可以让模型能够更好的理解人类语言。但是,什么才是理想的嵌入技术呢?以下是嵌入技术的两个主要特性:
-
「语义表示」 某些类型的Embedding可以捕捉单词之间的语义关系。这意味着,含义更接近的单词在向量空间中更接近。例如,“猫”和“狗”的向量肯定比“狗”和“草莓”的向量更相似。
-
「维度」 嵌入向量的大小应该是多少?15、50 还是 300?找到合适的平衡点是关键。较小的向量(较低维度)在内存中保存或处理效率更高,而较大的向量(较高维度)可以捕捉复杂的关系,但容易出现过拟合。作为参考,GPT-2 模型系列的嵌入大小至少为 768。
传统Embedding
几乎所有词向量嵌入技术都依赖于海量文本数据来提取词语之间的关系。此前,词向量嵌入方法依赖于基于文本中词语出现频率的统计方法。这种方法基于这样的假设:如果一对词语经常同时出现,那么它们之间的关系必然更密切。这些方法简单易行,计算量也不大。其中一种比较有代表性方法是TF-IDF。
TF-IDF(词频-逆文档频率)
TF-IDF 的理念是通过考虑两个因素来计算单词在文档中的重要性:
-
「词频 (TF)」 词语在文档中出现的频率。TF 值越高,表示词语对文档越重要。
-
「逆文档频率 (IDF)」 词语在文档中的稀缺性。这种方法是基于这样的假设:出现在多篇文档中的词语的重要性低于仅出现在少数文档中的词语。
TF-IDF 公式由两部分组成,分别为词频 (TF) 、逆文档频率 (IDF),总体的计算公式如下:
其中: 表示一个单词, 表示一个文档, 表示单词 在文档 中出现的次数, 表示文档 中所有单词的总次数, 表示语料库中总文档数, 表示包含单词 的文档数。
为了方便理解,这里举个实际计算的示例:
假设我们有一个包含 10 篇文档的语料库,而“cat”一词只出现在其中 2 篇文档中。 “cat” 的 IDF 为:
如果在某个文档中,“cat”在总共 100 个单词中出现了 5 次,则其 TF=5/100 为 0.05。因此,该文档中“cat”的最终 TF-IDF 得分为:
该得分告诉我们“cat”一词对于该特定文档相对于整个语料库的重要程度。得分越高,表示该词在该文档中出现的频率越高,并且在所有文档中相对较少出现,因此其在表征文档内容方面可能更有意义。
这里我们在 TinyShakespeare 数据集上使用 TF-IDF。为了模拟多文档,我们将文档分成十个块,相关代码如下:
# load the dataset with open("tinyshakespeare.txt", "r") as file: corpus = file.read() print(f"Text corpus includes {len(corpus.split())} words.") # to simulate multiple documents, we chunk up the corpus into 10 pieces N = len(corpus) // 10 documents = [corpus[i:i+N] for i in range(0, len(corpus), N)] documents = documents[:-1] #last document is residue # now we have N documents from the corpus # Text corpus includes 202651 words. from sklearn.feature_extraction.text import TfidfVectorizer # 默认会将文本中的单词转换为小写,并去除停用词(如the, is等)。在这个例子中,我们没有指定停用词,因此它会处理所有单词。 vectorizer = TfidfVectorizer() #首先会计算每个单词在文档中的TF-IDF值。它会生成一个稀疏矩阵,每一行代表一个文档,每一列代表一个单词。稀疏矩阵中的值是该单词在对应文档中的TF-IDF值。 embeddings = vectorizer.fit_transform(documents) words = vectorizer.get_feature_names_out() print(f"Word count: {len(words)} e.g.: {words[:10]}") print(f"Embedding shape: {embeddings.shape}") ### OUTPUT ### # Word count: 11446 e.g.: ['abandon' 'abase' 'abate' 'abated' 'abbey' 'abbot' 'abed' 'abel' 'abet' 'abhor'] # Embedding shape: (10, 11446)
这为我们提供了一个 10 维的嵌入向量,每个向量对应一个文档(这里的文档可以理解为一句话)。现在,为了更好地理解 TF-IDF 嵌入向量,我们使用 PCA 将 10 维空间映射到 2 维空间,以便更好地进行可视化。
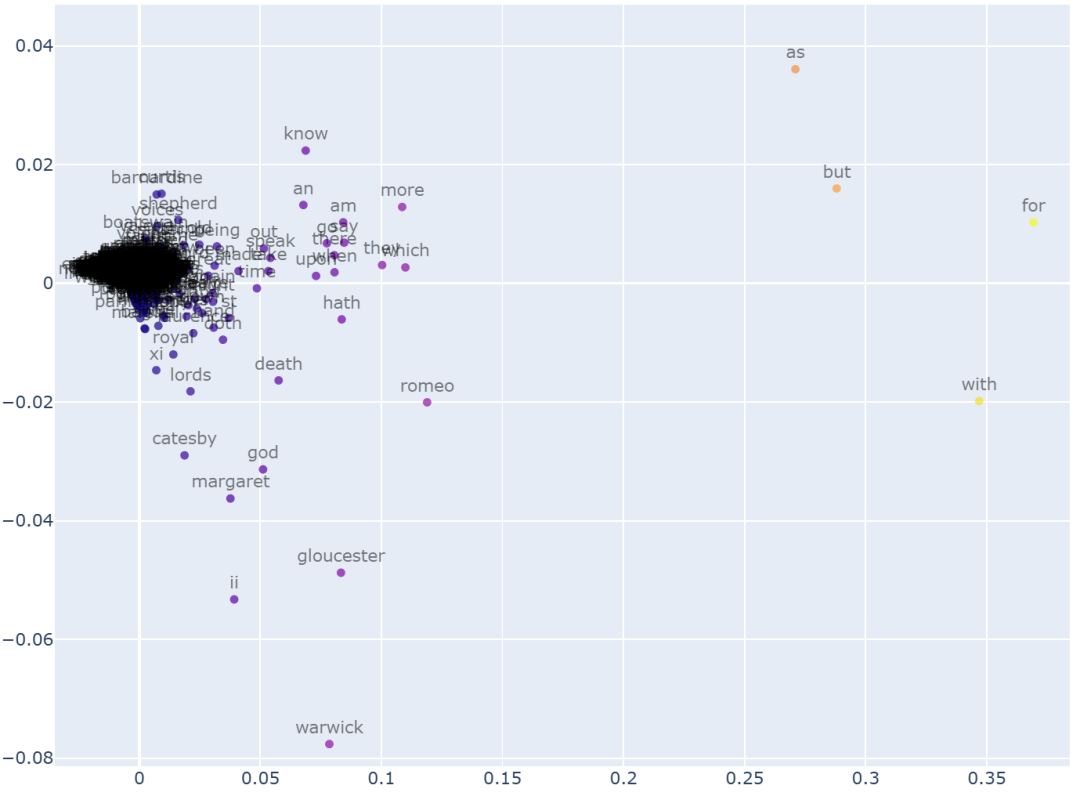
关于这个嵌入向量空间,有两点值得注意:
-
1.大多数单词都集中在一个特定的区域。这意味着在这种方法中,大多数单词的嵌入向量都很相似。这表明这些嵌入向量缺乏表达力和独特性。
-
2.这些嵌入向量之间没有语义联系。单词之间的距离与它们的含义无关。
由于 TF-IDF 基于文档中单词的出现频率,因此语义上接近的单词(例如数字)在向量空间中没有关联。TF-IDF 和类似统计方法的简单性使得它们在信息检索、关键词提取和基本文本分析等应用中非常有用。
静态Embedding
word2vec
word2vec是一种比TF-IDF更先进的技术。顾名思义,它是一个旨在将单词转换为嵌入向量的网络。它通过定义一个辅助目标来实现这一点,即优化网络的目标。
例如,「在CBOW(连续词袋)中,word2vec网络被训练成在给定一个单词的相邻词作为输入时预测该单词」。其直观理解是,你可以根据该单词周围的单词推断出该单词的嵌入。除了 CBOW 之外,另一种变体是 Skipgram,其工作原理完全相反:它旨在通过给定特定单词作为输入来预测其邻近单词。
word2vec的架构非常简单:首先通过一个隐藏层从中提取嵌入,然后外加一个输出层,预测词汇表中所有单词的概率。表面上,该网络被训练成根据相邻词预测正确的缺失词,但实际上,这是训练网络隐藏层并为每个单词找到正确嵌入向量。网络训练完成后,最后一层可以被抛弃,因为找出Embedding向量才是真正的目标。
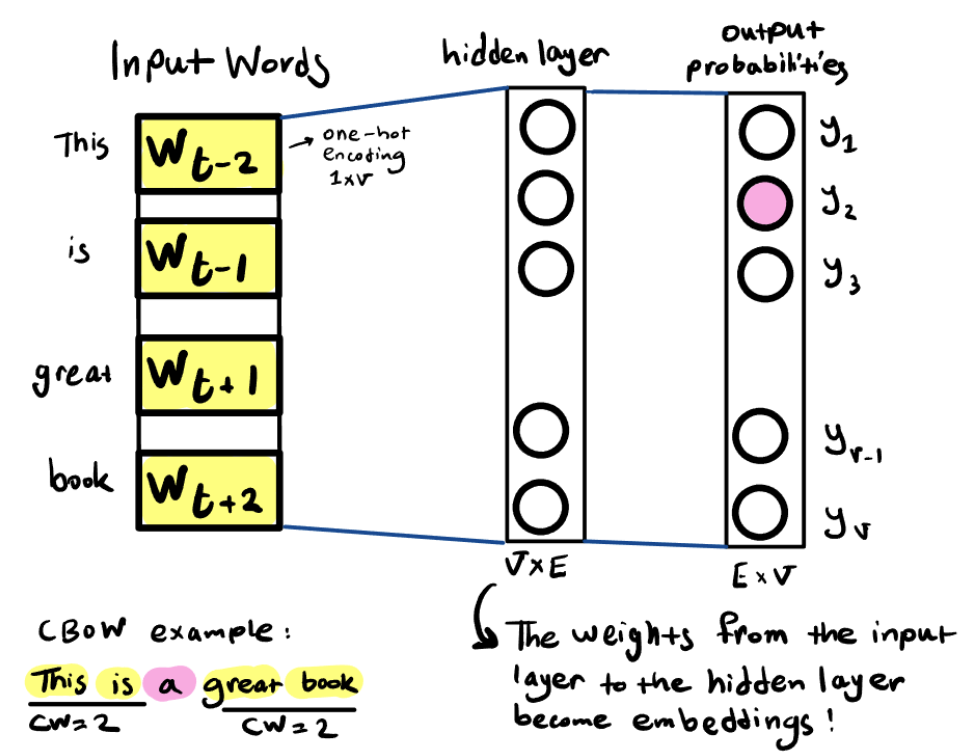
CBOW word2vec 的工作原理如下:
-
选择一个上下文窗口(例如上图上下文窗口为4)。
-
将特定单词前后两个单词作为输入。
-
将这四个上下文单词编码为one-hot向量。
-
将编码后的向量传入隐藏层,该层具有线性激活函数。
-
聚合隐藏层的输出(例如,使用 lambda 均值函数)。
-
将聚合后的输出输入到最后一层,该层使用 Softmax 预测每个可能单词的概率。
-
选择概率最高的 token 作为网络的最终输出。
隐藏层是存储Embedding的地方。当我们将一个单词的one-hot向量(一个除了一个元素设置为 1 之外全为 0 的向量)传入网络时,这个特定的 1 会触发该单词的嵌入传递到下一层。下面是一个简洁 word2vec 网络实现。
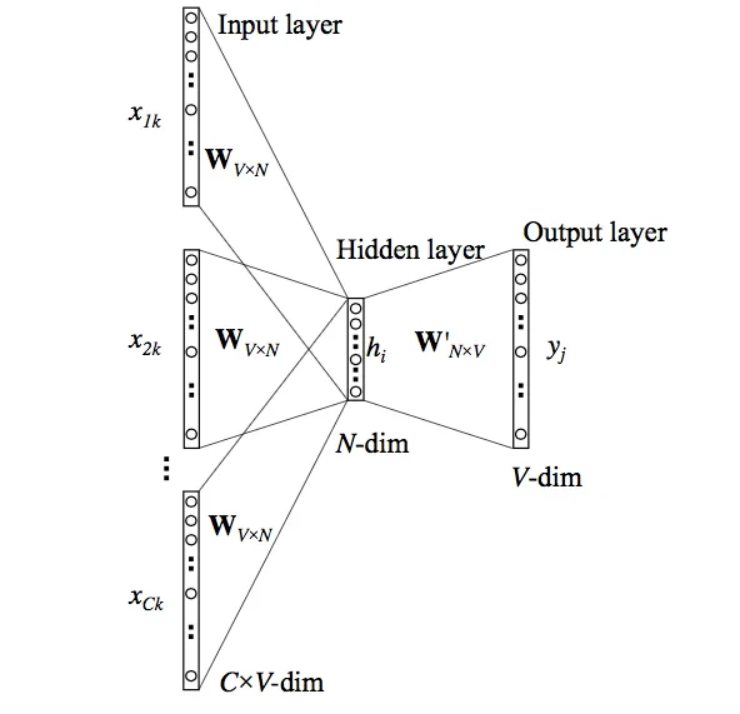
由于该网络依赖于上下文中词语之间的关系,而不是像 TF-IDF 那样依赖于单词出现的频率,因此它能够捕捉词语之间的语义关系。如果你比较感兴趣,可以去Google官网下载训练好的模型版本(下载链接:https://code.google.com/archive/p/word2vec/)。以下是实际使用 word2vec 的代码:
# 下载预训练的embedding向量模型,看看它是如何使用的。 import gensim model = gensim.models.KeyedVectors.load_word2vec_format('GoogleNews-vectors-negative300.bin.gz', binary=True) print(f"The embedding size: {model.vector_size}") print(f"The vocabulary size: {len(model)}") # italy - rome + london = england model.most_similar(positive=['london', 'italy'], negative=['rome']) ### OUTPUT ### [('england', 0.5743448734283447), ('europe', 0.537047266960144), ('liverpool', 0.5141493678092957), ('chelsea', 0.5138063430786133), ('barcelona', 0.5128480792045593)] model.most_similar(positive=['woman', 'doctor'], negative=['man']) ### OUTPUT ### [('gynecologist', 0.7093892097473145), ('nurse', 0.6477287411689758), ('doctors', 0.6471460461616516), ('physician', 0.6438996195793152), ('pediatrician', 0.6249487996101379)]
为了高效地训练 word2vec,尤其是在词汇量较大的情况下,可以使用了一种称为负采样的优化技术。负采样不是在整个词汇表上计算完整的 softmax(这计算成本很高),而是通过只更新少量负样本(即随机选择的与上下文无关的词语)和正样本来简化任务。这可以让训练速度更快,可扩展性更强。
更多精彩内容->专注大模型、Agent、RAG等前沿分享!
上下文Embedding
BERT
BERT 全称为Bidirectional encoder representations from transformers,在自然语言处理 (NLP) 领域,BERT 无处不在。当前大模型的一些理念方法都会有BERT的影子,彻底了解 BERT有利于提高你对大模型的理解。
BERT 源自“Attention is all you need”一文中介绍的 Transformer 架构,仅使用Transformer编码器,通过预训练使其能够生成语义表征并理解语言。BERT可以解决QA问答、文本摘要、分类等任务。
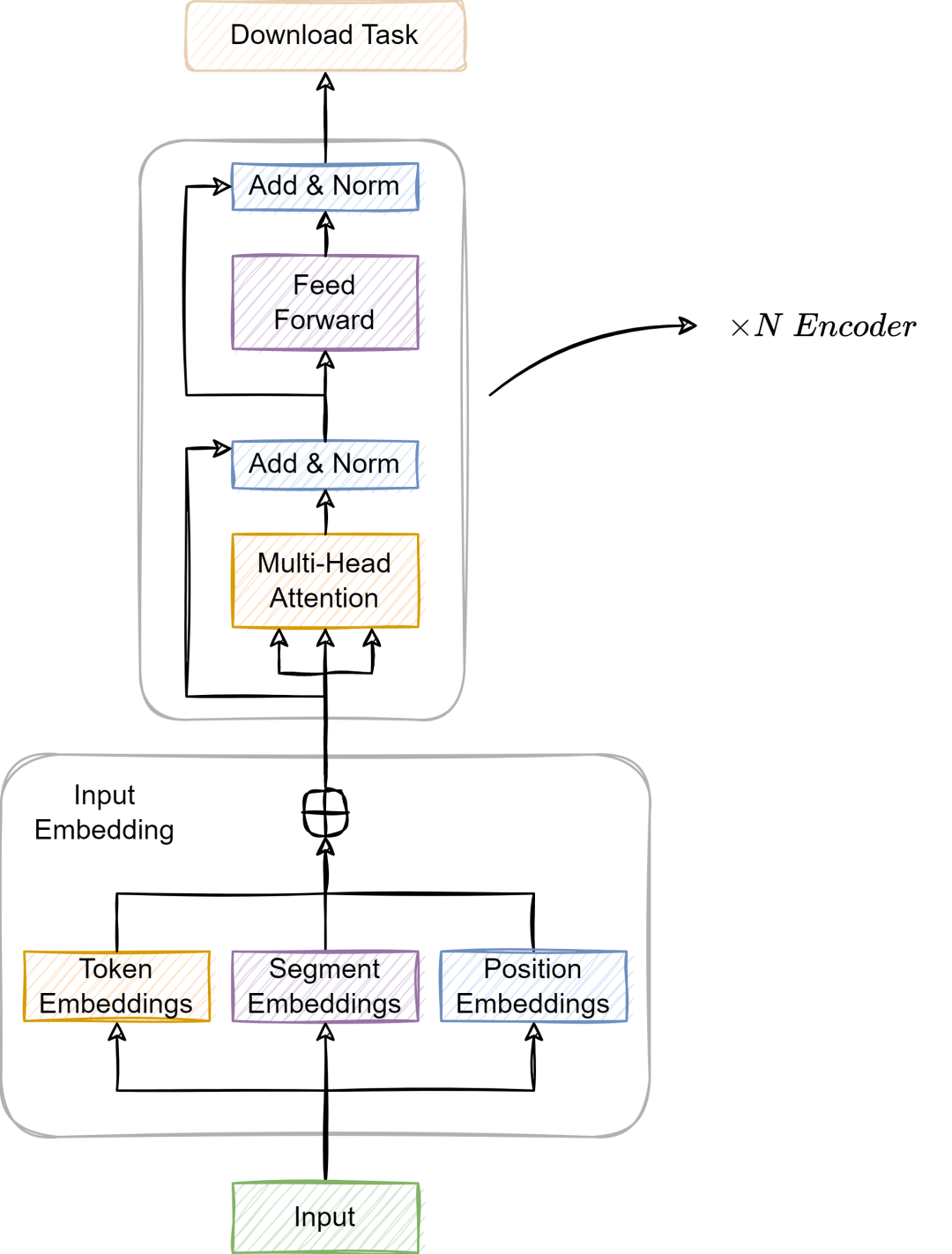
BERT 是一个仅使用编码器的 Transformer 模型,由四个主要部分组成,如上图所示:
-
分词器 (Tokenizer):将文本切分为整数序列。
-
嵌入 (Embedding):将离散标记转换为向量的模块。
-
编码器 (Encoder):一堆带有自注意力机制的 Transformer 模块。
-
任务头 (Task Head):当编码器完成表征后,这个特定于任务的头会处理这些表征,以完成标记生成或分类任务。
在预训练阶段,BERT需要同时学习两个任务:
「掩码语言模型」(Masked Language Model,MLM):预测句子中被掩码的单词(我之前 [MASKED] 过这本书 -> 阅读过)
「下一句预测」(Next Sentence Prediction,NSP):给定两个句子,预测 A 是否在 B 之前。两句之间添加特殊 [SEP] 标记将两个句子分开,这个任务类似于二分类。
注意另一个特殊标记 [CLS]。这个特殊标记有助于分类任务。随着模型逐层处理输入,[CLS] 成为所有输入标记的集合,稍后可用于分类目的。
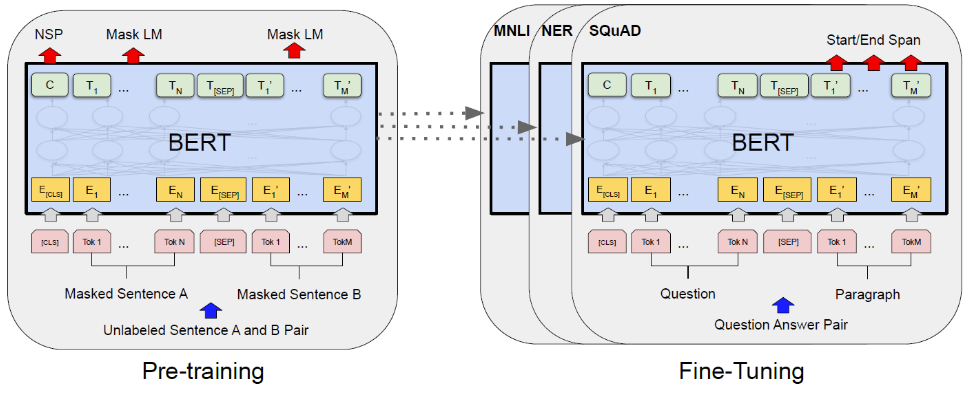
BERT模型之所这么重要是因为它是基于Transformer的语境化动态嵌入的首批应用实例之一。当输入一个句子时,BERT 模型的各层会利用自注意力机制和前馈机制来更新并整合句子中所有其它 token 的语境。每个 Transformer 层的最终输出是该单词的语境化表示。
大模型Embedding
当前Embedding仍然是大型语言模型的基础组件,也是一个广义的术语。这里我们重点介绍“嵌入”,即把词条转换为向量表征的模块,而不是隐藏层中的潜在空间。
嵌入在 LLM 中扮演什么角色?其实大模型的Embedding属于上下文Embedding的一种。简单来说,在基于 Transformer 的模型中,“嵌入”一词可以指静态嵌入和动态上下文表征:
**「静态Embedding」**往往是在第一层生成,并将词条嵌入(表示词条的向量)与位置嵌入(编码词条在序列中位置的向量)相结合,比如BERT模型就是属于静态嵌入。
动态上下文Embedding。当输入词条经过自注意力层和前馈层时,它们的嵌入会被更新,使其与上下文相关。这些动态表征根据词条周围的上下文来捕捉其含义。例如,“Bank”一词既可以出现在“river bank”短语中,也可以在“bank robbery”短语中。尽管“bank”这个词的标记嵌入在这两种情况下是相同的,但它在网络各层中进行转换时就会考虑到“bank”出现的具体上下文。
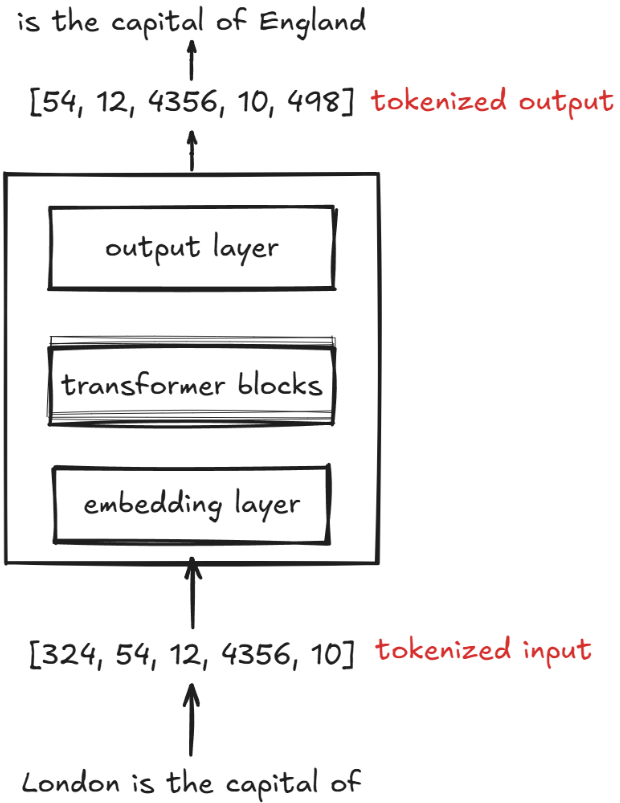
LLM的Embedding时在训练过程中进行优化的。虽然我们也可以使用 Word2Vec 等预训练模型为机器学习模型生成嵌入,但 LLM 通常会生成自己的Embedding,这些嵌入是输入层的一部分,并在训练过程中进行更新。将嵌入优化作为 LLM 训练的一部分,而不是使用 Word2Vec,其优势在于,这些嵌入会根据特定任务和数据进行优化。
「LLM 中的嵌入层相当于一个向量索引表」。给定一个索引列表(token id),它会返回相应的嵌入,参考样例如下图所示:
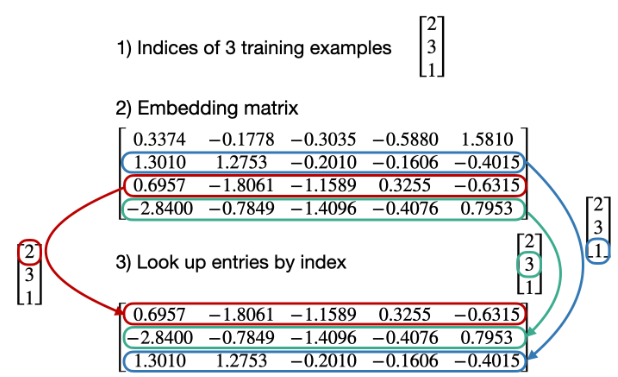
PyTorch 中大模型嵌入层的代码实现是使用 torch.nn.Embedding 完成的,它充当一个简单的查找表。它无需进行one-hot编码,而是直接使用索引作为输入,其实该层与简单的线性层相比没有什么特别之处。嵌入层只是一个使用索引的线性层。
上面介绍说无需one-hot编码,其主要原因时如果采用one-hot编码,其实原理时一样的,直接采用索引会更方便。下面是采用one-hot编码获取嵌入向量的示例:
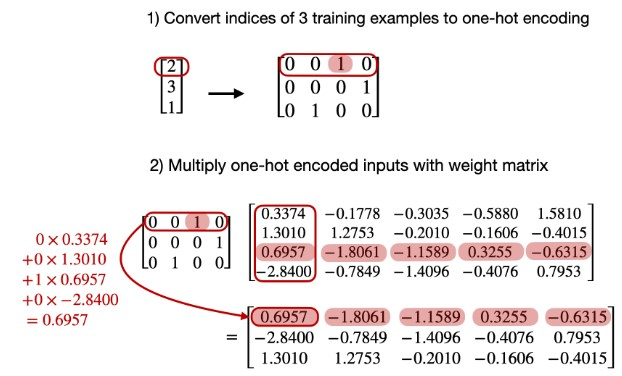
DS-Qwen1.5B的Embedding
实际大模型Embedding层是怎么样的呢?让我们剖析一下 Qwen 模型中 DeepSeek-R1 精简版的Embedding。首先,从 Hugging Face 加载 deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B 模型并保存嵌入。
import torch from transformers import AutoTokenizer, AutoModel tokenizer_name = "deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B" model_name = tokenizer_name # Load the tokenizer tokenizer = AutoTokenizer.from_pretrained(tokenizer_name) tokenizer.add_special_tokens({'pad_token': '[PAD]'}) # Load the pre-trained model model = AutoModel.from_pretrained(model_name) # Extract the embeddings layer embeddings = model.get_input_embeddings() # Print out the embeddings print(f"Extracted Embeddings Layer for {model_name}: {embeddings}") # Save the embeddings layer torch.save(embeddings.state_dict(), "embeddings_qwen.pth")
然后加载使用Qwen1.5B模型的嵌入层。将嵌入与模型的其它部分分离、保存和加载的目的是为了更快、更高效地获取输入的嵌入,而不是对模型进行完整的前向传递。
class EmbeddingModel(nn.Module): def __init__(self, vocab_size, embedding_dim): super(EmbeddingModel, self).__init__() self.embedding = nn.Embedding(num_embeddings=vocab_size, embedding_dim=embedding_dim) def forward(self, input_ids): return self.embedding(input_ids) vocab_size = 151936 dimensions = 1536 embeddings_filename = r"embeddings_qwen.pth" tokenizer_name = "deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B" tokenizer = AutoTokenizer.from_pretrained(tokenizer_name) # Initialize the custom embedding model model = EmbeddingModel(vocab_size, dimensions) # Load the saved embeddings from the file saved_embeddings = torch.load(embeddings_filename) # Ensure the 'weight' key exists in the saved embeddings dictionary if'weight'notin saved_embeddings: raise KeyError("The saved embeddings file does not contain 'weight' key.") embeddings_tensor = saved_embeddings['weight'] # Check if the dimensions match if embeddings_tensor.size() != (vocab_size, dimensions): raise ValueError(f"The dimensions of the loaded embeddings do not match the model's expected dimensions ({vocab_size}, {dimensions}).") # Assign the extracted embeddings tensor to the model's embedding layer model.embedding.weight.data = embeddings_tensor # put the model in eval mode model.eval()
接着,看一看如何将一个句子分词,然后进行向量化
def prompt_to_embeddings(prompt:str): # tokenize the input text tokens = tokenizer(prompt, return_tensors="pt") input_ids = tokens['input_ids'] # make a forward pass outputs = model(input_ids) # directly use the embeddings layer to get embeddings for the input_ids embeddings = outputs # print each token token_id_list = tokenizer.encode(prompt, add_special_tokens=True) token_str = [tokenizer.decode(t_id, skip_special_tokens=True) for t_id in token_id_list] return token_id_list, embeddings, token_str print_tokens_and_embeddings("HTML coders are not considered programmers")
在上面的代码中,我们对句子进行了分词,并打印了分词的嵌入。这些嵌入是 1536 维向量。这里有一个简单的示例,以“HTML coders are not considered programmers”这句话为例。
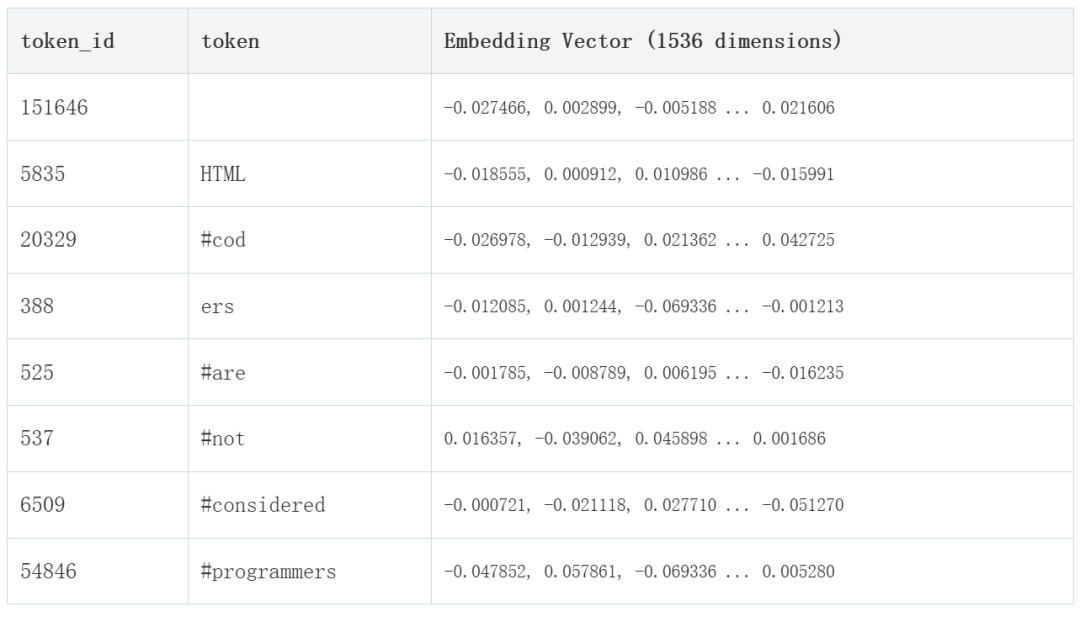
最后,让我们看看如何找到与特定单词最相似的嵌入。由于嵌入是向量,我们可以使用余弦相似度来找到与特定单词最相似的嵌入。然后,我们可以使用 torch.topk 函数来找到前 k 个最相似的嵌入。
def find_similar_embeddings(target_embedding, n=10): """ Find the n most similar embeddings to the target embedding using cosine similarity Args: target_embedding: The embedding vector to compare against n: Number of similar embeddings to return (default 3) Returns: List of tuples containing (word, similarity_score) sorted by similarity """ # Convert target to tensor if not already ifnot isinstance(target_embedding, torch.Tensor): target_embedding = torch.tensor(target_embedding) # Get all embeddings from the model all_embeddings = model.embedding.weight # Compute cosine similarity between target and all embeddings similarities = torch.nn.functional.cosine_similarity( target_embedding.unsqueeze(0), all_embeddings ) # Get top n similar embeddings top_n_similarities, top_n_indices = torch.topk(similarities, n) # Convert to word-similarity pairs results = [] for idx, score in zip(top_n_indices, top_n_similarities): word = tokenizer.decode(idx) results.append((word, score.item())) return results token_id_list, prompt_embeddings, prompt_token_str = prompt_to_embeddings("USA and China are the most prominent countries in AI.") tokens_and_neighbors = {} for i in range(1, len(prompt_embeddings[0])): token_results = find_similar_embeddings(prompt_embeddings[0][i], n=6) similar_embs = [] for word, score in token_results: similar_embs.append(word.replace(" ", "#")) tokens_and_neighbors[prompt_token_str[i]] = similar_embs all_token_embeddings = {} # Process each token and its neighbors for token, neighbors in tokens_and_neighbors.items(): # Get embedding for the original token token_id, token_emb, _ = prompt_to_embeddings(token) all_token_embeddings[token] = token_emb[0][1] # Get embeddings for each neighbor token for neighbor in neighbors: # Replace # with space neighbor = neighbor.replace("#", " ") # Get embedding neighbor_id, neighbor_emb, _ = prompt_to_embeddings(neighbor) all_token_embeddings[neighbor] = neighbor_emb[0][1]
Embeddings as Graphs
我们如何看待嵌入?一种方法是将嵌入层视为一个网络,每个Token是一个节点;如果两个Token的向量距离较近,那么我们假设它们的节点可以通过边连接。
例如,我们将“*AI agents will be the most hot topic of artificial intelligence in 2025.*”这句话,进行Token化,将Token转换为Embedding向量,然后找到与已有的每个嵌入最相似的20个嵌入,则嵌入图如下:
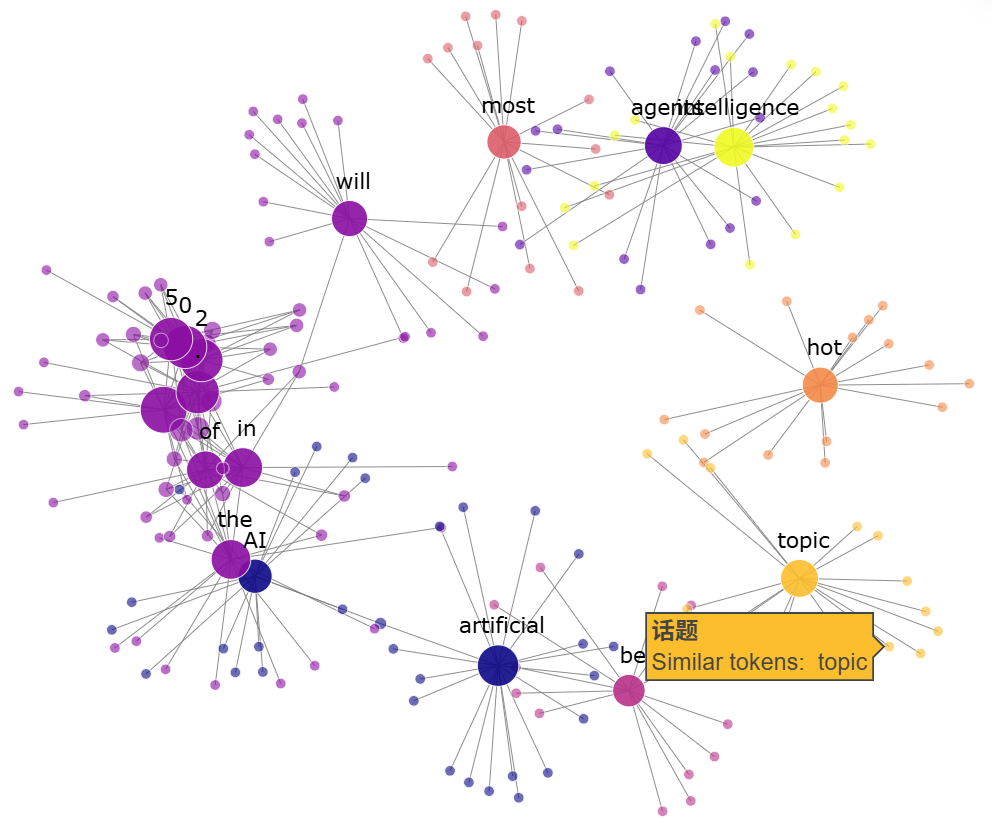 实际上,您可以在文章开头看到一个更全面的示例,其中映射了50个标记及其最接近的标记。
实际上,您可以在文章开头看到一个更全面的示例,其中映射了50个标记及其最接近的标记。
在上述图示例中,我们忽略了“Token变体”。一个标记或单词可能有许多不同的变体,每个变体都有各自的嵌入向量。例如,标记“list”可能有许多不同的变体,每个变体都有各自的嵌入,例如“_list”、“List”等等。这些变体通常具有与原始标记非常相似的嵌入。下图是标记“列表”及其近邻(包括其变体)的图表。
结论
Embedding仍然是自然语言处理和现代大语言模型的基础部分之一。虽然在LLM 领域的研究每天都在探索新的方法和技术,但Embedding在大型语言模型中却没有太大变化。尽管如此,它们都是至关重要的,「因为它是将文本、图像、语音等内容转换至大模型可理解维度的必经之路」。
总之,本文主要介绍了关于Embedding的基础知识,以及它们从传统统计方法演变为当今大语言模型 (LLM) 用例的过程。通过本文希望能够帮助你对Embedding有一个全面的了解。
2024最新版优快云大礼包:《AGI大模型学习资源包》免费分享**
一、2025最新大模型学习路线
一个明确的学习路线可以帮助新人了解从哪里开始,按照什么顺序学习,以及需要掌握哪些知识点。大模型领域涉及的知识点非常广泛,没有明确的学习路线可能会导致新人感到迷茫,不知道应该专注于哪些内容。
我们把学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战。

L1级别:AI大模型时代的华丽登场
L1阶段:我们会去了解大模型的基础知识,以及大模型在各个行业的应用和分析;学习理解大模型的核心原理,关键技术,以及大模型应用场景;通过理论原理结合多个项目实战,从提示工程基础到提示工程进阶,掌握Prompt提示工程。

L2级别:AI大模型RAG应用开发工程
L2阶段是我们的AI大模型RAG应用开发工程,我们会去学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3级别:大模型Agent应用架构进阶实践
L3阶段:大模型Agent应用架构进阶实现,我们会去学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造我们自己的Agent智能体;同时还可以学习到包括Coze、Dify在内的可视化工具的使用。

L4级别:大模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,我们会更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调;并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

整个大模型学习路线L1主要是对大模型的理论基础、生态以及提示词他的一个学习掌握;而L3 L4更多的是通过项目实战来掌握大模型的应用开发,针对以上大模型的学习路线我们也整理了对应的学习视频教程,和配套的学习资料。
二、大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

三、大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

四、大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

五、大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取


















 1725
1725

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









