



LinkedHashMap 这玩意儿,到底比 HashMap 多了个啥名堂?

★
说白了,LinkedHashMap 就是 HashMap 的一个“亲儿子”,但它不安分,非要在老爹的基础上,自己搞了条“双向锁链”,说是什么要记住兄弟们(键值对)是按先来后到排队的,还是谁最近被“翻牌子”了。
跟那个随心所欲、不记顺序的 HashMap 比起来,LinkedHashMap 这小子,嘿,它还真就能把元素塞进去的顺序,或者你最近摸过哪个元素的顺序给捋得清清楚楚。
不信?源码摆在这儿,自己瞅瞅:
public class LinkedHashMap<K,V> extends HashMap<K,V> implements Map<K,V>
瞧见没?extends HashMap,明明白白。
吹上天的'有序性'和那点'性能代价',咱们掰扯掰扯
- “有序”的真相:LinkedHashMap 天天吹嘘自己讲秩序,靠的就是那条双向链表。但你得明白,它骨子里存东西还是乱糟糟的一堆(跟 HashMap 一样),只不过是靠着链表这根线,让你找起来的时候,能按顺序给你拎出来。别被表象骗了!
- 速度上的“小牺牲”:天下没有免费的午餐。LinkedHashMap 要多伺候一条链表,那增删改查这些活儿,比起 HashMap 那光杆司令,自然是要慢那么一丢丢。这笔账,你得算清楚。
- 底子里的“全家桶”:这家伙的家底,那是相当丰富:数组当大本营,链表解决日常冲突,红黑树是冲突激烈时的“定海神针”,再加上那条核心的双向链表。料是挺足,但也复杂不是?
扒开源码:JDK17 里,这货的'小辫子'是怎么藏的?
节点那点“微创新”
在 HashMap 的那个 Node 基础上,动了点手脚,硬生生给塞进去了 before 和 after 两个指针。干啥用的?不就是为了把键值对按顺序串起来嘛。
static class Entry<K,V> extends HashMap.Node<K,V> { Entry<K,V> before, after; // 瞅瞅,就是这俩货 Entry(int hash, K key, V value, Node<K,V> next) { super(hash, key, value, next); } }
新来的元素?直接挂到链条的尾巴上,没商量。
要是你翻了某个旧元素的牌子,而且你还特意嘱咐了要按“访问顺序”来(accessOrder 设置为 true),那好,这元素立马被拎到链条尾巴,成为最新的“红人”。
put 操作背后那条链,怎么维护的?
void afterNodeInsertion(boolean evict) { // HashMap 干完活,就轮到它出场了 LinkedHashMap.Entry<K,V> first; // 如果evict为真(表示可能需要移除旧元素),并且链表头不为空, // 并且 removeEldestEntry说“可以移除了”(比如LRU满了) if (evict && (first = head) != null && removeEldestEntry(first)) { K key = first.key; // 那就把最老的那个(链表头的)给干掉 removeNode(hash(key), key, null, false, true); } }
前面咱不都说了嘛,LinkedHashMap 是站在 HashMap 肩膀上的。所以啊,想彻底搞懂这小子,HashMap 那点家底你得先摸透了,不然就是雾里看花。
访问顺序?就是这么被“调教”的
public V get(Object key) { Node<K,V> e; if ((e = getNode(key)) == null) // 找不到?滚蛋! return null; if (accessOrder) // 如果开启了访问顺序模式... afterNodeAccess(e); // ...就得调整一下它在链表里的位置 return e.value; }
void afterNodeAccess(Node<K,V> e) { // 专治各种不服,访问过的就给我到后面去! LinkedHashMap.Entry<K,V> last; // 如果 accessOrder 为 true,并且当前尾节点不是刚访问的这个节点 e // (也就是说,e 不是最新的,需要移动) if (accessOrder && (last = tail) != e) { LinkedHashMap.Entry<K,V> p = (LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after; p.after = null; // 先把自己从链中断开(尾指针清空) if (b == null) // 如果 p 原本是头节点 head = a; // 那么 p 的后一个节点 a 成为新的头 else b.after = a; // 否则,p 的前一个节点 b 指向 p 的后一个节点 a if (a != null) // 如果 p 原本有后继节点 a.before = b; // 那么 p 的后一个节点 a 的前驱指向 b else last = b; // 否则,说明 p 原本是尾节点(但在 if 条件里已经排除了这种情况,这里更像是 p 之前是 last,现在 last 可能是 b) // 其实这里是说,如果 a 是 null,意味着 p 是原来的尾,但因为 (last = tail) != e,所以 p 不是当前的尾, // 这意味着在 p 之后没有节点了,所以 b 成了新的尾(如果p之前有节点的话)。 // 更准确地说,如果p后面没节点了,且p不是全局尾,那么操作后,p的前一个节点b就成了事实上的尾部(在p被摘除后)。 if (last == null) // 如果到头来,链表空了(理论上不会,因为 p 至少在)或者说原来的尾部 last 现在是 null(意味着原链表只有一个元素 e,且 e 不是 tail,这逻辑有点绕) // 实际上是:如果原来的尾节点 last 是 null(即链表为空,或者说在调整前 tail 指向的是一个空位置,这不太可能) // 或者是经过前面的调整,导致 last 指向了 null (比如原链表只有一个元素 p,b为null,a为null,则last为null) head = p; // 那么 p 自己成为头(也成为尾) else { p.before = last; // p 的前驱指向原来的尾节点 last last.after = p; // 原来的尾节点 last 的后继指向 p } tail = p; // 最后,p 成为新的尾节点 ++modCount; // 操作次数加一,fail-fast 机制要用 } }
这块代码,说白了,就是玩“移花接木”。你要是动了某个元素,只要 accessOrder 开着,它就把这元素从原来的位置抠出来,再塞到链表屁股后头去。谁最新被“宠幸”,谁就排最后,简单粗暴!
版本迭代那点事儿:从'简陋'到'打补丁',它也算历尽沧桑
JDK1.4-1.7:草台班子初建成
那时候,就是个基础款:数组打底,链表串联,再加上一条双向链表管顺序。
至于哈希冲突?简单,纯链表硬抗!毕竟,那会儿红黑树还没进场呢。
JDK8:傍上HashMap的大腿,也得跟着进化
风水轮流转,JDK8 里 HashMap 引入了红黑树来收拾那些过长的链表烂摊子。
LinkedHashMap 作为“小弟”,自然也得跟着大哥的步伐,重写点方法,确保自己的那条小链表别掉链子。
JDK9+:迭代器的小修小补
主要是针对迭代器的 fail-fast 机制做了点增强,让它在并发捣乱的时候,能更早、更安全地“撂挑子”。
实战演练场:LRU 和轨迹追踪,是炫技还是真香?
LRU 缓存?小菜一碟!
`public class LRUCache extends LinkedHashMap {
private final int maxCapacity; // 坑位就这么多
public LRUCache(int maxCapacity) {
// 注意这最后一个参数 'true',开启访问顺序模式,LRU 的命根子!
super(maxCapacity, 0.75f, true);
this.maxCapacity = maxCapacity;
}
@Override
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
// 只要元素数量超过了坑位数,就把最老的那个(链表头的)踹出去
return size() > maxCapacity;
}
}用 LinkedHashMap 搞个 LRU 缓存,简直是杀鸡用牛刀——不对,是太顺手了!关键就在于构造函数里那个true,把accessOrder一开,再重写个removeEldestEntry` 方法,齐活!谁最久没被翻牌子,谁就滚蛋。
用户足迹追踪?也凑合!
LinkedHashMap<String, Long> accessLog = new LinkedHashMap<>(100, 0.75f, true) { // 容量100,访问顺序 @Override protected boolean removeEldestEntry(Map.Entry<String, Long> eldest) { return size() > 50; // 老子只关心最近的50条访问记录,再早的?删! } };
想记录用户最近访问了哪些页面?搞个固定大小的 LinkedHashMap,同样开启访问顺序,满了就自动把最早的记录给挤出去。是不是有点意思?
性能那点猫腻:不想被它坑,这些'潜规则'你得懂
- 初始化容量,别瞎搞:事先掂量掂量你大概要塞多少东西,给个差不多的初始容量。不然,它老是折腾着扩容(rehash),能快得起来吗?
- 负载因子,悠着点:要是你查得多、改得少,那负载因子设小点,比如 0.5 到 0.75 之间,能让冲突少点,查起来也利索。当然,内存也多占点,自己权衡。
- 并发?老实上锁!:这玩意儿本身不是线程安全的。真要在多线程环境里用,老老实实套个
Collections.synchronizedMap,或者干脆用ConcurrentHashMap再加自己维护顺序(那就复杂了)。别想当然! - 遍历的“捷径”:想遍历?用
entrySet().iterator()通常比你先搞个keySet()再一个个去get要快那么一点点。细节决定成败,有时候是这样的。
擂台 PK:LinkedHashMap、HashMap、TreeMap,谁才是你碗里的菜?
| 特性 | LinkedHashMap | HashMap | TreeMap |
|---|---|---|---|
| 迭代顺序 | 按你插的顺序,或者按你摸的顺序 | 鬼知道什么顺序 | 按键的“天生”大小顺序 (自然排序或自定义排序) |
| 时间复杂度 | 大部分操作 O(1),理想状态下 | 大部分操作 O(1),理想状态下 | O(log n),稳定输出 |
| 内存消耗 | 略高,毕竟多了条链子 | 较低 | 中等,节点也得存点额外信息 |
| 线程安全 | 别想了,没有 | 同样没有 | 还是没有 |
| 使用场景 | 需要顺序的缓存(LRU)、记录访问轨迹 | 万金油,随便用 | 需要按键排序、范围查找的场景 |
解读一下这张破表:
都说 LinkedHashMap 和 HashMap 是 O(1),听听就好。那是在哈希冲突不严重,大家相安无事的前提下。LinkedHashMap 因为多了条双向链表,节点对象本身就大了点,维护链表指针也得花点CPU时间,所以严格来说,它比 HashMap 在增删改查上,总要慢那么一丁点儿。至于 TreeMap 那 O(log n),看起来慢,但人家稳定啊,而且能玩排序和范围查找,这是前两者望尘莫及的。所以,选哪个?看你到底图个啥!别光听信广告,得看疗效!

黑客/网络安全学习包


资料目录
-
成长路线图&学习规划
-
配套视频教程
-
SRC&黑客文籍
-
护网行动资料
-
黑客必读书单
-
面试题合集
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
*************************************优快云大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享*************************************
1.成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过网络安全的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。

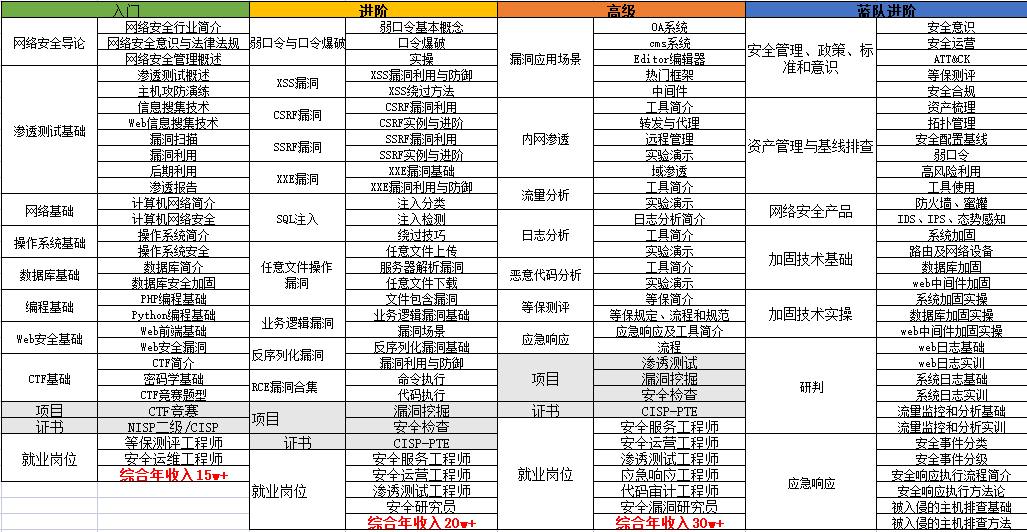
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
*************************************优快云大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享*************************************
2.视频教程
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,其中一共有21个章节,每个章节都是当前板块的精华浓缩。
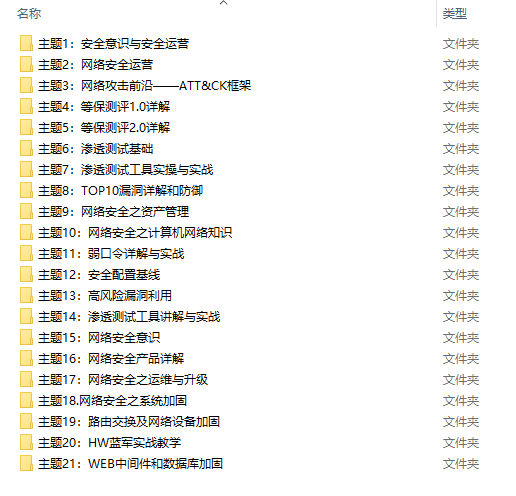
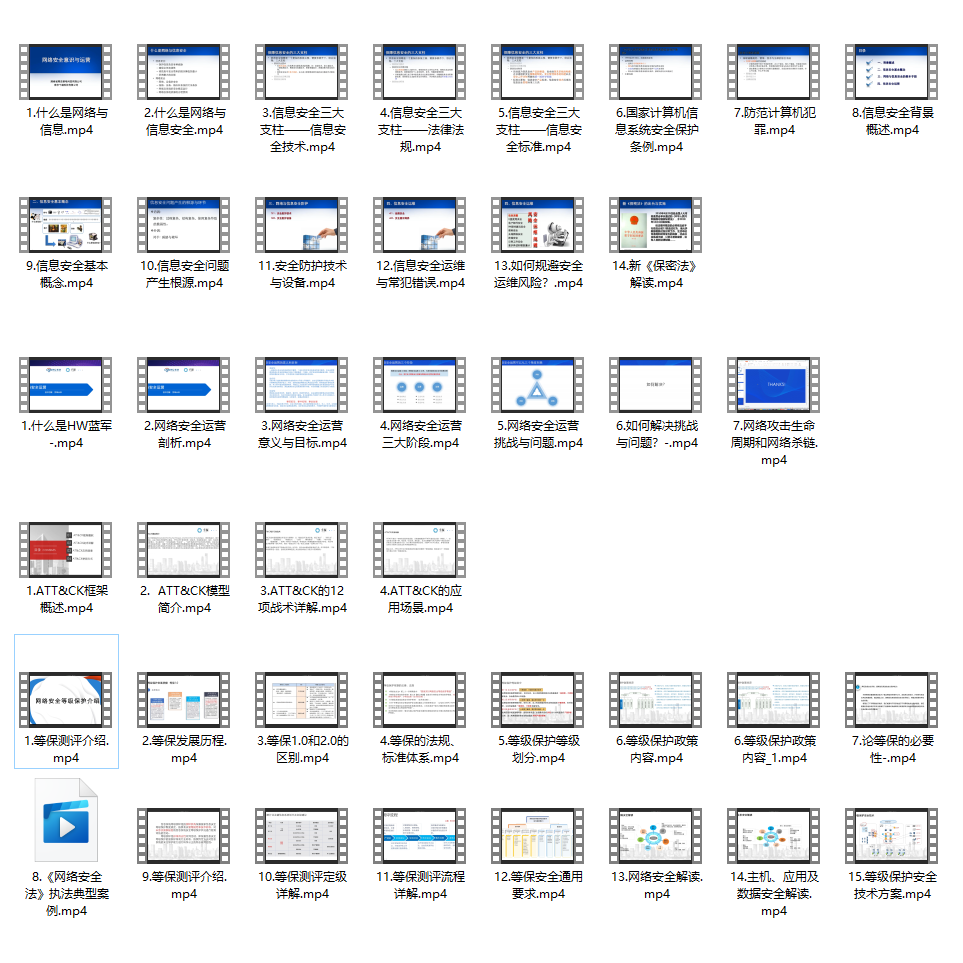
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
*************************************优快云大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享*************************************
3.SRC&黑客文籍
大家最喜欢也是最关心的SRC技术文籍&黑客技术也有收录
SRC技术文籍:

黑客资料由于是敏感资源,这里不能直接展示哦!
4.护网行动资料
其中关于HW护网行动,也准备了对应的资料,这些内容可相当于比赛的金手指!
5.黑客必读书单
**

**
6.面试题合集
当你自学到这里,你就要开始思考找工作的事情了,而工作绕不开的就是真题和面试题。
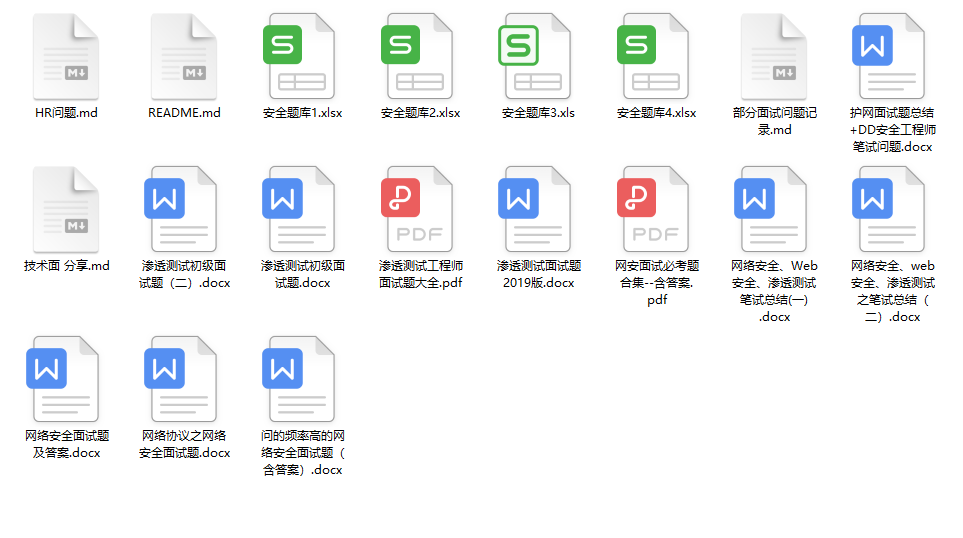
更多内容为防止和谐,可以扫描获取~

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
*************************************优快云大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享*********************************

















 1169
1169

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









