




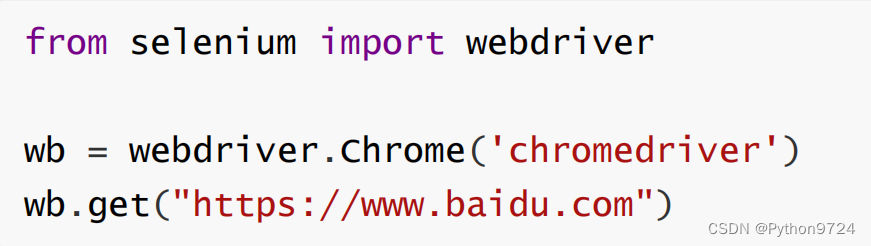
pip install selenium==4.0.0
浏览器驱动安装
chrome驱动下载地址:
https://chromedriver.storage.googleapis.com/index.html
启动
元素选取


By对象导入:
from selenium.webdriver.common.by import By
ID = "id"
• XPATH = "xpath"
• LINK_TEXT = "link text"
• PARTIAL_LINK_TEXT = "partial link text"
• NAME = "name"
• TAG_NAME = "tag name"
• CLASS_NAME = "class name"
• CSS_SELECTOR = "css selector"文本输入
创建好的对象,去定位在用send_keys写入
chrome.find_element_by_id("password").send_keys("password")
点击
chrome.find_element_by_css_selector("submitbutton").click()动作切换
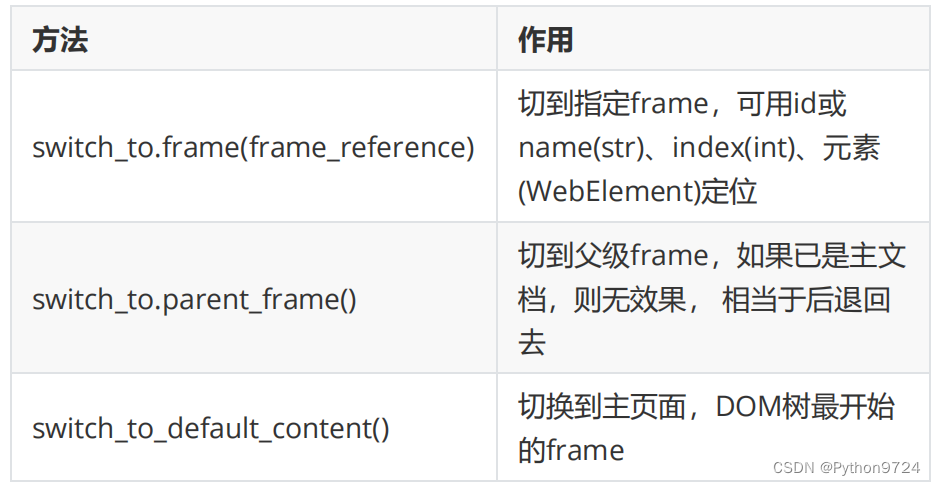
窗口切换
用
selenium
操作浏览器如果需要在打开新的页面,这个时候会有问题,因
为我们用
selenium
操作的是第一个打开的窗口,所以新打开的页面我们是
无法去操作的,所以我们要用到切换窗口:即
handle
切换的方法

Window_handles
的顺序并不是浏览器上标签的顺序,尽量避免多标签操 作
from selenium import webdriver
from selenium.webdriver.common.by import By
wb = webdriver.Chrome()
wb.get("https://movie.douban.com/top250")
js = 'window.open("https://www.baidu.com")'
wb.execute_script(js)
print(wb.title) # 第一个title
print(wb.current_window_handle) # 当前的句柄
print(wb.window_handles) # 所有的句柄
wb.switch_to.window(wb.window_handles[1]) # 定位页面转到指定
的window_name页面
print(wb.title)页面切换(frame iframe )
在实际的爬虫中,明明定位的路径没问题,这个时候我们可以考虑一下是
否是该页面存在
frame
的问题导有时候我们会遇到找不到元素的问题致的
定位不到元素。
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
wb = webdriver.Chrome()
wb.maximize_window() # 全屏的意思
wb.get("https://study.163.com/") # 进入这个网站
wb.find_element(by=By.XPATH, value='//span[@class="ux-btnth-bk-main ux-btn- ux-btn- ux-modal-btn um-modal-btn_okth-bk-main"]').click()
wb.find_element_by_xpath('//a[@class="uxmodal_close"]').click()
wb.find_element_by_id('j-nav-login').click()
time.sleep(5)
# 重新创建一个iframe对像
fr = wb.find_element(by=By.XPATH,value='//iframe[@frameborder="0"]')
#进入这个iframe对象
wb.switch_to.frame(fr)
#wb被赋予了对象后继续操作
phone = wb.find_element(by=By.ID, value="phoneipt")
phone.send_keys('18887654321')页面弹窗
有的时候还会遇到弹窗的问题, 主要有两种一种是浏览器弹窗
(
alert/prompt
),一种是自定义弹窗 自定义弹窗,就是一个自定义的div
层,是隐藏页面中的,当触发了这个弹 窗后,他就显示出来,这种方式我们通过正常的定位方式是可以定位到
的。
alert
弹窗,就要用下面的方法处理
#
老的版本使用的是
switch_to_alert
#
现在使用的是
switch_to

import time
from selenium import webdriver
from selenium.webdriver.common.by import By
wb = webdriver.Chrome()
wb.get(r'E:\11_class_spider\18.自动化\弹框.html')
# 第一种
# wb.find_element(by=By.ID, value='alert').click()
# print(wb.switch_to.alert.text)
# 第二种
# wb.find_element(by=By.ID, value='confirm').click()
# print(wb.switch_to.alert.text)
# 第三种
# wb.find_element(by=By.ID, value='prompt').click()
# prompt_tag = wb.switch_to.alert
# time.sleep(2)
# prompt_tag.send_keys("潼瑶")
# time.sleep(2)
# prompt_tag.accept()等待
简介
在
selenium
操作浏览器的过程中,每一次请求
url
,
selenium
都会等待
页面加载完成以后,才会将操作权限在交给我们的程序。
但是,由于
ajax
和各种
JS
代码的异步加载问题,当一个页面被加载到浏
览器时,该页面内的元素可以在不同的时间点被加载,这就使得元素的定
位变得十分困难,当元素不再页面中时,使用
selenium
去查找的时候会抛
出
ElementNotVisibleException
异常。
为了解决这个问题,
selenium
提供了两种等待页面加载的方式,显示等
待和隐式等待,让我们可以等待元素加载完成后在进行操作。
显式等待
显式等待: 显式等待指定某个条件,然后设置最长等待时间,程序每隔
XX
时间看一眼,如果条件成立,则执行下一步,否则继续等待,直到超过设
置的最长时间,然后抛出超时异常(
TimeoutException
)。
显示等待主要使用了
WebDriverWait
类与
expected_conditions
模块。
一般写法:
WebDriverWait(driver, timeout, poll_frequency,
igonred_exceptions).until(method, message)
Driver
:传入
WebDriver
实例。
timeout:
超时时间,等待的最长时间(同时要考虑隐性等待时间)
poll_frequency:
调用
until
中的方法的间隔时间,默认是
0.5
秒
ignored_exceptions:
忽略的异常,如果在调用
until
的过程中抛出这个元组
中的异常,则不中断代码,继续等待
.
Method
:可执行方法
Message
: 超时时返回的信息
expected_conditions
条件
expected_conditions
是
selenium
的一个子模块,其中包含一系列可用于
判断的条件,配合该类的方法,就能够根据条件而进行灵活地等待了

import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait #显示等待的类
from selenium.webdriver.support import expected_conditionsas EC
#创建对象
wb = webdriver.Chrome()
wb.maximize_window() # 全屏的意思
wb.get("https://study.163.com/") # 进入网站
#点击这个位置
wb.find_element(by=By.XPATH, value='//span[@class="ux-btnth-bk-main ux-btn- ux-btn- ux-modal-btn um-modal-btn_okth-bk-main"]').click()
wb.find_element_by_xpath('//a[@class="uxmodal_close"]').click()
wb.find_element_by_id('j-nav-login').click()
# time.sleep(5)
# 显示等待
locator = (By.XPATH, '//iframe[@frameborder="0"]')
#调用这个类 传入对象wb 等待时间5秒 每次0.3秒去调用一下 后面为报错信息
WebDriverWait(driver=wb,timeout=5,poll_frequency=0.3).until(EC.presence_of_element_locatd(locator), message="Element Not Found")
# 进入frame
fr = wb.find_element(by=By.XPATH,
value='//iframe[@frameborder="0"]')
wb.switch_to.frame(fr)
phone = wb.find_element(by=By.ID, value="phoneipt")
phone.send_keys('18887654321')隐性等待
隐性等待
implicitly_wait(xx)
:设置了一个最长等待时间,如果在规定时间
内网页加载完成,则执行下一步,否则一直等到时间截止,然后执行下一
步。
弊端就是程序会一直等待整个页面加载完成,就算你需要的元素加载出来
了还是需要等待。,也就是一般情况下你看到浏览器标签栏那个小圈不再
转,才会执行下一步,
隐性等待对整个
driver
的周期都起作用,所以只要设置一次即可
隐性等待和显性等待可以同时用,但要注意:等待的最长时间取两者之中
的大者
默认等待时间为
0
,可以通过下面的方式设置:
from selenium import webdriver
driver = webdriver.Chrome()
driver.implicitly_wait(10) #隐式等待,最长10s
driver.get('https://www.baidu.com')强制等待
强制等待就是不论如何,在此处都需要阻塞等待一段时间,及time.sleep()
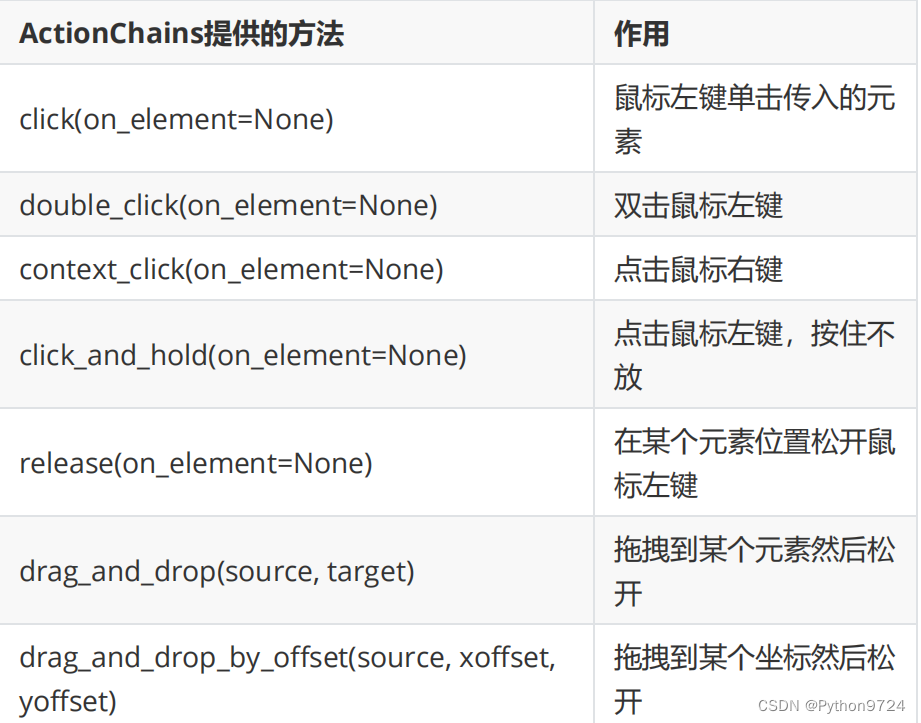
动作链
在
selenium
当中除了简单的点击动作外,还有一些稍微复杂的动作,就需
要用到
ActionChains
(动作链)这个子模块来满足我们的需求。
ActionChains
可以完成复杂一点的页面交互行为,例如元素的拖拽,鼠标
移动,悬停行为,内容菜单交互。
它的执行原理就是当调用
ActionChains
方法的时候不会立即执行,而是
将所有的操作暂时储存在一个队列中,当调用
perform()
方法的时候,会按
照队列中放入的先后顺序执行前面的操作。
ActionChains包:
from selenium.webdriver.common.action_chains import ActionChains

import time
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains
wb = webdriver.Chrome()
url = "http://treejs.cn/v3/demo/cn/exedit/drag.html"
wb.get(url)
time.sleep(5)
element = wb.find_element_by_id('treeDemo_2_span')
target = wb.find_element_by_id('treeDemo_11_span')
# 动作链 把前一个对象拖到后一个对像中 perform()执行动作
ActionChains(wb).drag_and_drop(element, target).perform()
time.sleep(10)
wb.quit()其他
常用方法

get_screenshot_as_file("文件路径") #截图保存文件
save_screenshot(‘filename’) #截图保存文件
get_screenshot_as_png() #二进制的图片数据保存无界面设置
#设置chrome 无界面
from selenium.webdriver.chrome.options import Options
from selenium import webdriver
chrome_options=Options()
chrome_options.add_argument("--headless")
wd_headless=webdriver.Chrome(options=chrome_options)
wd_headless.get('http://www.treejs.cn/v3/demo/cn/exedit/drag.html')
print("无界面操纵",wd_headless.page_source)
















 1239
1239

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









