




 Transformer模型从自然语言处理领域扩展到计算机视觉,应用于图像和视频任务,如视觉和语言预训练、图像超分辨、视频修复和目标跟踪。研究人员通过端到端的预训练模型SOHO优化视觉特征,实现跨模态任务的高性能。此外,基于Transformer的图像超分辨方法TTSR和视频修复模型STTN展示了在纹理恢复和时空信息处理方面的优势。
Transformer模型从自然语言处理领域扩展到计算机视觉,应用于图像和视频任务,如视觉和语言预训练、图像超分辨、视频修复和目标跟踪。研究人员通过端到端的预训练模型SOHO优化视觉特征,实现跨模态任务的高性能。此外,基于Transformer的图像超分辨方法TTSR和视频修复模型STTN展示了在纹理恢复和时空信息处理方面的优势。
编者按:Transformer 模型在自然语言处理(NLP)领域已然成为一个新范式,如今越来越多的研究在尝试将 Transformer 模型强大的建模能力应用到计算机视觉(CV)领域。那么未来,Transformer 会不会如同在 NLP 领域的应用一样革新 CV 领域?今后的研究思路又有哪些?微软亚洲研究院多媒体搜索与挖掘组的研究员们基于 Vision Transformer 模型在图像和视频理解领域的最新工作,可能会带给你一些新的理解。
作为一个由自注意力机制组成的网络结构,Transformer一“出场”就以强大的缩放性、学习长距离的依赖等优势,替代卷积神经网络(CNN)、循环神经网络(RNN)等网络结构,“席卷”了自然语言处理(NLP)领域的理解、生成任务。
然而,Transformer 并未止步于此,2020年,Transformer 模型首次被应用到了图像分类任务中并得到了比 CNN 模型更好的结果。此后,不少研究都开始尝试将 Transformer 模型强大的建模能力应用到计算机视觉领域。目前,Transformer 已经在三大图像问题上——分类、检测和分割,都取得了不错的效果。视觉与语言预训练、图像超分、视频修复和视频目标追踪等任务也正在成为 Transformer “跨界”的热门方向,在 Transformer 结构基础上进行应用和设计,也都取得了不错的成绩。
Transformer“跨界”图像任务
最近几年,随着基于 Transformer 的预训练模型在 NLP 领域不断展现出惊人的能力,越来越多的工作将 Transformer 引入到了图像以及相关的跨模态领域,Transformer 的自注意力机制以其领域无关性和高效的计算,极大地推动了图像相关任务的发展。
端到端的视觉和语言跨模态预训练模型
视觉-语言预训练任务属于图像领域,其目标是利用大规模图片和语言对应的数据集,通过设计预训练任务学习更加鲁棒且具有代表性的跨模态特征,从而提高下游视觉-语言任务的性能。
现有的视觉-语言预训练工作大都沿用传统视觉-语言任务的视觉特征表示,即基于目标检测网络离线抽取的区域视觉特征,将研究重点放到了视觉-语言(vision-language,VL)的特征融合以及预训练上,却忽略了视觉特征的优化对于跨模态模型的重要性。这种传统的视觉特征对于 VL 任务的学习主要有两点问题:
1)视觉特征受限于原本视觉检测任务的目标类别
2)忽略了非目标区域中对于上下文理解的重要信息
为了在VL模型中优化视觉特征,微软亚洲研究院多媒体搜索与挖掘组的研究员们提出了一种端到端的 VL 预训练网络 SOHO,为 VL 训练模型提供了一条全新的探索路径。 该工作的相关论文“Seeing Out of tHe bOx: End-to-End Pre-training for Vision-Language Representation Learning”已收录于CVPR 2021 Oral。
GitHub地址:github.com/researchmm/…

SOHO 模型的主要思路是:将视觉编码器整合到 VL 的训练网络中,依靠 VL 预训练任务优化整个网络,从而简化训练流程,缓解依赖人工标注数据的问题,同时使得视觉编码器能够在 VL 预训练任务的指导下在线更新,提供更好的视觉表征。
经验证,SOHO 模型不仅降低了对人工标注数据的需求,而且在下游多个视觉-语言任务(包括视觉问答、图片语言检索、自然语言图像推理等)的公平比较下,都取得了 SOTA 的成绩。
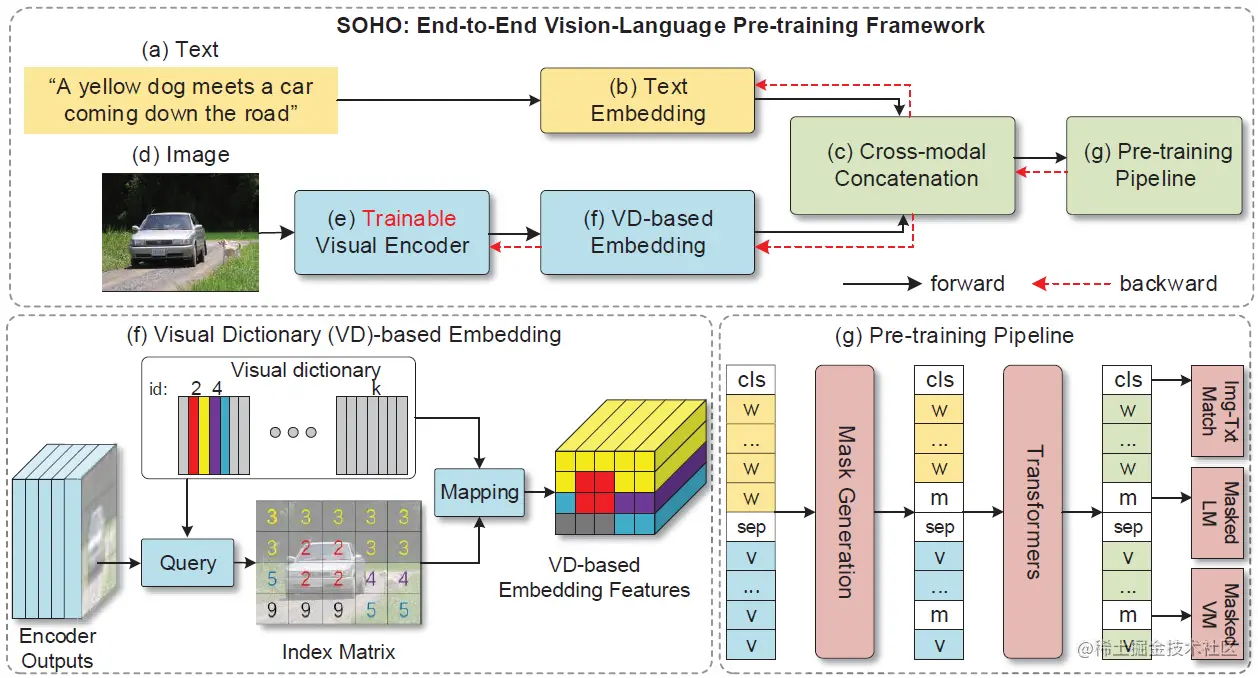
图1:端到端的视觉语言预训练网络 SOHO
如图1所示,SOHO 由三部分组成:1)基于卷积网络的视觉编码器(可在线更新);2)基于视觉字典(Visual Dictionary)的视觉嵌入层;3)由多层 Transformer 组成的 VL 融合网络。三个部分“各司其职”,卷积网络负责将一张图像表征为一组向量,然后利用视觉字典对图像中相近的特征向量进行表征,最后利用 Transformer 组成的网络将基于字典嵌入的视觉特征与文本特征融合到一起。
对于视觉编码器,研究员
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 177
177

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









