



公众号后台经常有人私信要抓取某某网页数据,该怎么办?巧妇难为无米之炊,确实现在数据采集已经是最最常见的业务需求了,所以很多人想学python来写爬虫,以为爬虫只是HTTP请求->HTML解析->结构化数据储存,但其实爬虫远比想象的难。
比如想研究跨境电商商品数据,看看国外的流行趋势,好不容易写个爬虫,结果网站全是验证码,甚至连网页都打不开。
因为现在的网站基本都会采用React、Vue或Angular等前端框架进行异步加载(AJAX),并大量使用无限滚动、阴影DOM(Shadow DOM)以及各种设备指纹识别技术来阻断自动化访问 。
这种高难度反爬机制下,单纯的HTTP请求已难以满足采集需求,你需要有完整浏览器渲染能力、智能代理调度和行为模拟功能,才能请求到网页数据。
对于一般的非技术童鞋,可以直接用现成的爬虫工具,不需要自己写代码,这些爬虫工具主要分三大类,无代码/低代码采集工具、网页API接口、半自动化爬虫框架。
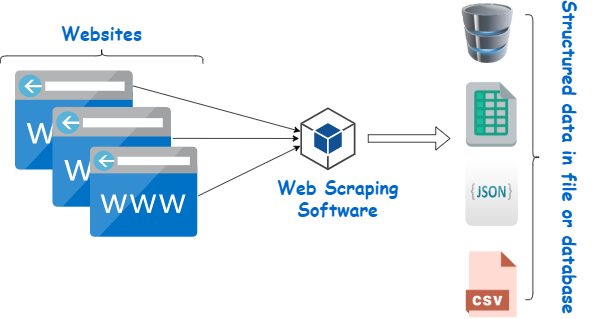
这里推荐6个适合大家用的爬虫工具,可以按照需求来选择合适的技术方案。
八爪鱼采集器 (Octoparse)
八爪鱼是无脑式的数据采集器,通过可视化的拖拉拽操作,实现对网页的数据采集,它的核心逻辑是模拟人的操作(点击、输入和滚动),你打开它的内置浏览器,鼠标点哪里,它就记录哪里。
八爪鱼引入了AI辅助的识别算法,用户只需输入目标网址,系统即可自动解析页面结构,识别出列表项、翻页按钮以及核心数据字段 。这种机制极大地减少了手动配置XPath的时间。
另外它的界面采用了逻辑清晰的流程图设计。每一个操作(如打开网页、循环、点击、提取数据)都被表现为一个可配置的节点 。这种设计不仅降低了门槛,也方便用户进行复杂的逻辑调试。

对于频繁跳出的验证码,八爪鱼可以通过集成第三方验证码识别接口以及设置合理的行为间隔,能够有效降低触发验证码的频率。在最新版本中,还增加了验证码弹窗自动提醒及手动干预设置 。
你可以自定义设置,让八爪鱼导出结构化的csv、excel数据类型,或者存储到云上,都非常的方便。
下载:https://affiliate.bazhuayu.com/gzhsyy
亮数据 (Bright Data)
亮数据则是专门用来采集复杂网页数据的集成化工具,它有专门的抓取API接口,可以处理各种反爬机制,能直接请求到结构化的数据。

做跨境电商或海外数据抓取的朋友都知道,最痛苦的不是抓取,而是被封 IP或者无限验证码,亮数据就是专门用来处理这类场景的,它有几个比较使用的功能。
1、Web Unlocker (网页解锁器):当你遇到那种怎么都过不去的验证码或IP封锁时,它的解锁器能自动模拟真实的浏览器指纹、自动轮换全球 IP,成功率极高。
2、Scraping Browser:这是一种运行在亮数据云端的“有头”浏览器。开发者无需在本地管理Puppeteer或Playwright镜像,只需一行代码即可连接到亮数据。该浏览器内置了所有顶级的解封技术,包括自动解决CAPTCHA、解析复杂的Canvas指纹以及模拟真实的鼠标轨迹。
3、Brightdata-mcp:这是亮数据专门用来对接大模型的MCP服务,可以通过prompt直接采集数据,不需要任何的配置和开发。
所以你可以用亮数据来实现跨境电商选品、全球机票酒店比价、金融数据分析等场景。
下载:https://get.brightdata.com/webscra

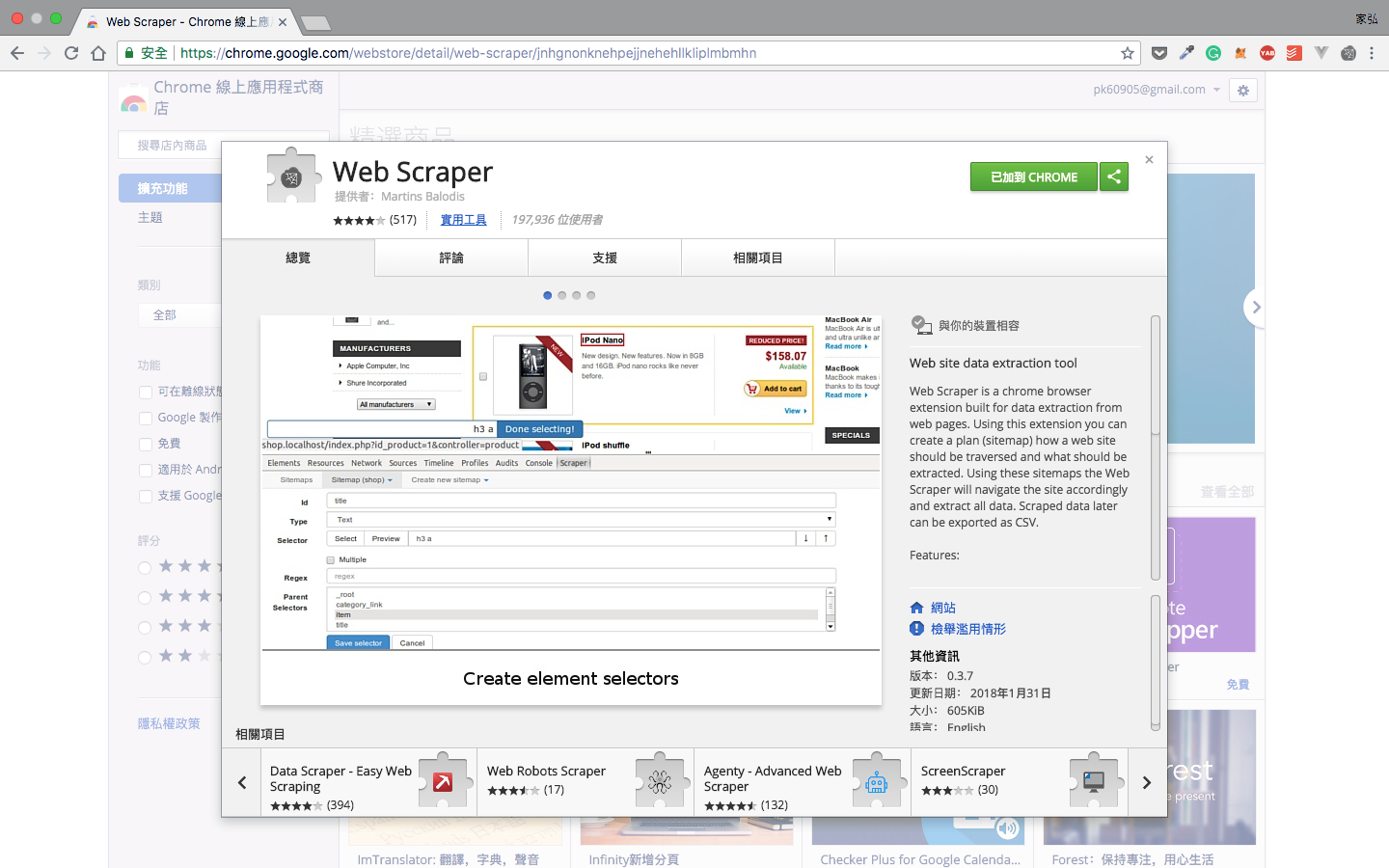
Web Scraper (Chrome 插件)
Web Scraper是一款免费、轻量的爬虫浏览器插件,它基于“Sitemap”概念,用户通过定义选择器路径,让浏览器本身按照预设逻辑执行抓取。
当然,Web Scraper适合临时性的、非高频率的轻量级数据获取。虽然没有云端调度,但其零成本、易上手的特点使其在个人开发者中极具人气 。
后羿采集器
既然提到了八爪鱼,就不得不提后羿,两者逻辑很像,都是可视化操作的爬虫工具,它在跨平台(支持 Mac/Windows/Linux)支持上做得不错,且免费功能的开放度在某些版本上比较良心。
Scrapy (Python 框架)
Scrapy是最受欢迎的Python开源爬虫框架,它基于Twisted异步I/O库,能够以极高的效率并行处理成千上万个请求。
它的优势是极强的模块化设计(Spiders, Middlewares, Pipelines),可以精准控制数据从下载、解析到存储的每一个微秒 。
而且现在的Scrapy生态已与Playwright高度集成,能够完美处理单页面应用(SPA)的渲染问题 。

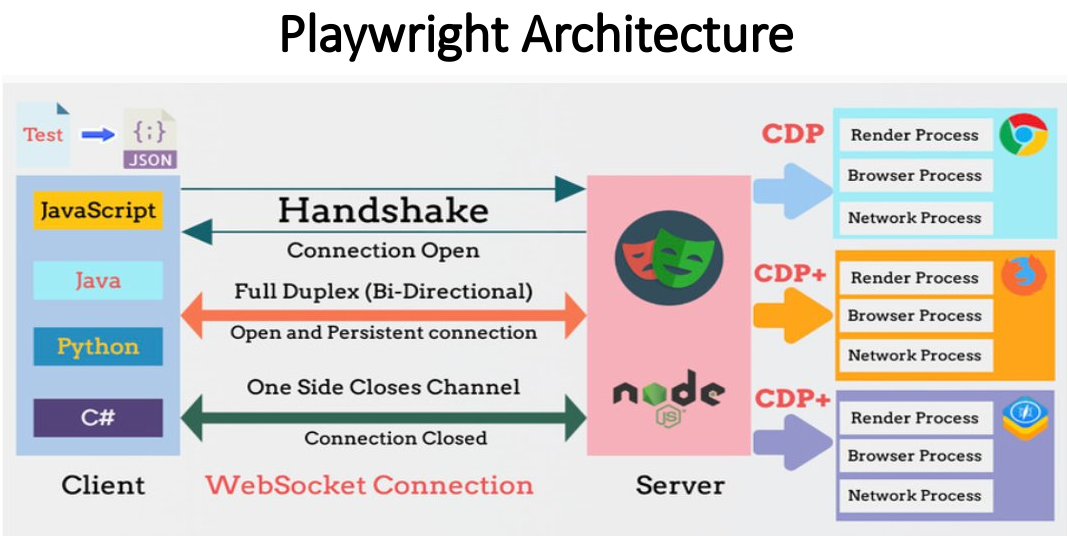
Selenium / Playwright(自动化工具)
Selenium / Playwright其实是自动化测试工具,但经常被用来做爬虫,它们能控制浏览器进行点击、滚动、输入。对于那些全是动态加载(AJAX)的网页,比如翻页、滑动等,Scrapy 搞不定时,它们就能派上用场。
其实工具没有绝对的好坏,只有适不适合,如果你只是想偶尔抓个数据做个表,八爪鱼或 Web Scraper就足够了。如果你是做出海业务,想稳定的采集电商数据,则适合用亮数据。如果你想深入技术开发, 自己掌握爬虫框架,则适合Scrapy / Selenium / Playwright
虽然网页爬虫技术本身是中性的,但需要注意遵守 Robots.txt 协议,只采集公开数据,控制访问频率,保持合规性,


















 2759
2759

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











