



SQLite:是一款轻型的数据库,是遵守ACID的关系型数据库管理系统,它包含在一个相对小的C库中。它的设计目标是嵌入式的,而且已经在很多嵌入式产品中使用了它,它占用资源非常的低,在嵌入式设备中,可能只需要几百K的内存就够了。它能够支持Windows/Linux/Unix等等主流的操作系统.
数据库wal机制:修改并不直接写入到数据库文件中,而是写入到另外一个称为WAL的文件中;如果事务失败,WAL中的记录会被忽略,撤销修改;如果事务成功,它将在随后的某个时间被写回到数据库文件中,提交修改。同步WAL文件和数据库文件的行为被称为checkpoint(检查点),它由SQLite自动执行,默认是在WAL文件积累到1000页修改的时候;当然,在适当的时候,也可以手动执行checkpoint,SQLite提供了相关的接口。执行checkpoint之后,WAL文件会被清空
WAL模式的优点:
在大多数场景明显更快;
读写操作可并发;
顺序访问磁盘;
使用fsync()操作更少,因此在调用fsync()中断的系统上更不容易发生问题;
| int Db_SetDb_PRAGMA(void) |
1. 创建数据库表,涉及命名表、定义列及每一列的数据类型。PRIMARY KEY用于表示主键
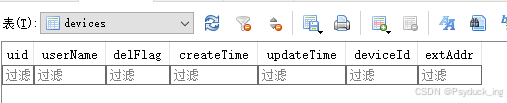
| CREATE TABLE IF NOT EXISTS devices (uid text,userName text,delFlag integer,createTime long,updateTime long,deviceId text PRIMARY KEY,extAddr text); |
创建了表名为devices数据库表,包含如下列
2. 删除数据库表,删除表定义及其所有相关数据、索引、触发器、约束和该表的权限规范
| #devices为具体的表名 |
3.删除数据库表记录,用于删除表中已有的记录。可以使用带有 WHERE 子句的 DELETE 查询来删除选定行,否则所有的记录都会被删除
| #删除device表中deviceId='e950d433a44a5e859268c135addcea'这条记录 |
4.查询表数据, SELECT 语句用于从 SQLite 数据库表中获取数据,以结果表的形式返回数据。这些结果表也被称为结果集
| #查询获取device表中的deviceId和delFlag两列字段所有信息,不带条件 |
5.查询更新表数据,UPDATE 查询用于修改表中已有的记录。可以使用带有 WHERE 子句的 UPDATE 查询来更新选定行,否则所有的行都会被更新
| #将device表中deviceId为z1833b0e70304701983955fae5934b21的delFlag字段置为0,带条件 |
6.执行整个库的完全性检查,会查看错序的记录、丢失的页,毁坏的索引等
| PRAGMA integrity_check; |
7.修改表名称,重命名表。ALTER TABLE 命令不通过执行一个完整的转储和数据的重载来修改已有的表
| ALTER TABLE [旧表名] RENAME TO [新表名]; |
8.数据库表增加字段,在已有的表中添加额外的列
| ALTER TABLE [表名]ADD COLUMN [列名] [数据类型] [值]; |
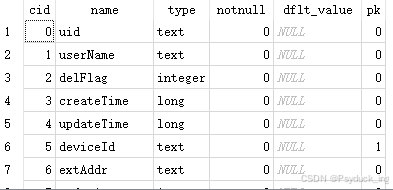
9.查看表结构
| PRAGMA table_info ([表名称]); |
10.Group by详解:根据by对数据按照哪个字段进行分组,或者是哪几个字段进行分组
| select 字段 from 表名 where 条件 group by 字段 |
例:
查出Device表中所有deviceName:
sql: SELECT deviceName FROM Device;

查出Device表中所有deviceName,根据deviceName进行分组,去除重复的
sql: SELECT deviceName FROM Device GROUP BY deviceName;

查询表中某个字段是否重复
sql:SELECT [字段名] FROM [表名] group by [字段名] having count(*) > 1;
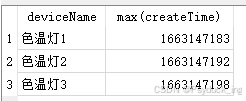
查出Device表中所有deviceName,根据deviceName进行分组,名称匹配为色温灯
sql:SELECT deviceName,max(createTime) FROM Device WHERE deviceName like "色温灯%%" GROUP BY deviceName;
配合聚合函数使用:count() , sum() , avg() , max() , min() 其中avg表示平均数
按deviceName分组,并统计数量
sql:SELECT deviceName,count(*) FROM Device GROUP BY deviceName;

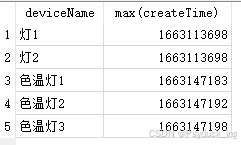
按deviceName分组,寻找最大createTime 创建时间
SELECT deviceName,max(createTime) FROM Device GROUP BY deviceName;
11. Order by详解:用来基于一个或多个列按升序或降序顺序排列数据
| #ASC 默认值,按从小到大,升序排列 |
例:
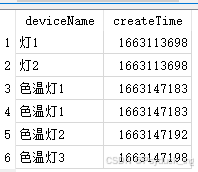
从Device表查找deviceName,createTime,并按createTime升序排列
Sql: SELECT deviceName,createTime FROM Device ORDER BY createTime ASC;
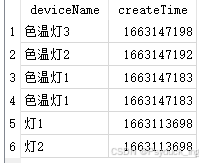
从Device表查找deviceName,createTime,并按createTime降序排列
Sql: SELECT deviceName,createTime FROM Device ORDER BY createTime DESC;
12.INSERT INTO 详解:用于向表中插入新记录
| #无需指定要插入数据的列名,只需提供被插入的值即可 |
13.REPLACE INTO详解
replace是insert的增强版, replace into 首先尝试插入数据到表中, 1. 如果发现表中已经有此行数据(根据主键或者唯一索引判断)则先删除此行数据,然后插入新的数据。 2. 否则,直接插入新数据
语法:
| SQL |
14.SELECT DISTINCT详解:用于返回唯一不同的值
语法:
| SELECT DISTINCT 字段名 FROM 表名 |
例子:
SELECT DISTINCT uid,deviceId FROM new_device;

SELECT DISTINCT uid FROM new_device;
![]()
15.limit:用于限制由 SELECT 语句返回的数据数量
语法:
| SELECT 字段名 FROM 表名 LIMIT [数量] |
例:
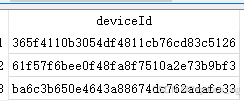
select deviceId from new_device LIMIT 3;
16.Left join详解:从左表(table1)返回所有的行,即使右表(table2)中没有匹配。如果右表中没有匹配,则结果为 NULL
语法:
| SELECT column_name(s) FROM table1 LEFT JOIN table2 ON table1.column_name=table2.column_name; |
17.Right join详解:从右表(table2)返回所有的行,即使左表(table1)中没有匹配。如果左表中没有匹配,则结果为 NULL
语法:
| SELECT column_name(s) FROM table1 RIGHT JOIN table2 ON table1.column_name=table2.column_name; |
https://download.youkuaiyun.com/download/Psyduck_ing/89261263?spm=1001.2014.3001.5503


















 3464
3464

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











