






 本文通过对比测试,展示了在Python中不同循环方法的执行效率。实验表明,传统的for循环在处理大规模数据时,相较于列表推导式,具有更快的运行速度。
本文通过对比测试,展示了在Python中不同循环方法的执行效率。实验表明,传统的for循环在处理大规模数据时,相较于列表推导式,具有更快的运行速度。
前言
上星期看到一篇推送,很标题党,“我不想用for循环”,里面提及了各种替代for循环的方法,然而,我能感觉到的,有些只是格式上的重新组织(这点也是作者自己说的,为了更好的可读性),于是,这里我想试试,是否用作者的方法,程序运行速度会快一点。
浏览微信推送的原文(传送门)
在Python里,for循环的执行速度远超while循环,这在之前已经测试过,请点这里回顾分析 (传送门)。
测试思路
- 选择足够大的循环规模(如 1千万数组的操作)
- 执行形同的逻辑,比较时间
测试代码
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Date : 2019-04-16 09:57:40
# @Author : Promise (promise@mail.ustc.edu.cn)
# @Link : ${link}
# @Version : $Id$
import time
def main():
result = []
maxLimit = 10000000
start = time.process_time()
result = [i*i for i in range(maxLimit)] # 方法1
end = time.process_time()
print('map时间是 t=', end - start)
result2 = [0]*maxLimit
start = time.process_time()
for i in range(maxLimit): # 方法2,正常for循环
result2[i] = i*i
end = time.process_time()
print('正常for循环的时间是 t=', end - start)
print(result == result2)
运行结果
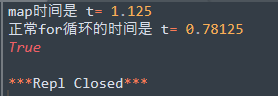
出乎意料,还是正常的for循环比较快…… 最后的True,是判断两个数组是不是相等。
代码分析
- 方法1一开始可以不用预设数组的大小,因为它的语法机制
result = [i*i for i in range(maxLimit)] # 方法1已经内置了数组大小的信息了 。我也尝试了预先建立好数组,再执行,时间没差。说明,对这种方法,可以省去数组初始化而不影响运行速度。 - 正常的for循环,看起来代码行数增加了,但运行速度是真的快。 虽然这里对于1千万的大数组,差距相差约为 0.3 s 0.3s 0.3s, 可是, 我们必须意识到,对于现代计算机,时间单位常用 n s , μ s ns,\mu s ns,μs, 所以 s s s是个很大的时间单位,于是,这里的差距,实际是很明显的
总结
正如推送里面作者声称的那样,其实采用方法1,更多的是考虑格式的简洁,包括减少缩进和代码行数。不过这次的测试说明了,采用方法1会牺牲执行速度。
结合之前 for 循环 和 while 循环执行速度的比较,在Python编程中,如果追求程序的执行速度,最好还是使用标准的 for 循环语句,特别是,我不觉得标准的格式有什么意义模糊的地方啊……


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









