







 本文详细介绍如何设置Chrome浏览器以辅助爬虫工作,包括修改默认搜索引擎、检查网页源码及加载数据,利用Network功能分析请求详情,是爬虫初学者的必备指南。
本文详细介绍如何设置Chrome浏览器以辅助爬虫工作,包括修改默认搜索引擎、检查网页源码及加载数据,利用Network功能分析请求详情,是爬虫初学者的必备指南。
爬虫的浏览器一般讲究效率,使自己选择的。
选取一个浏览器,小白,网上得出结论谷歌浏览器OK!不是不让用了吗?怎么还用谷歌??
为什么爬虫要用Chrome?
为什么大家似乎都值得header应该怎么写?
为什么大家都知道怎么爬取网页的路线?
为什么....
如果你也跟我一样,有过上面类似的疑问,那么我觉得,这篇文章你可能值得看一下。
1. 设置谷歌
打开设置--->有一个设置--->打开设置
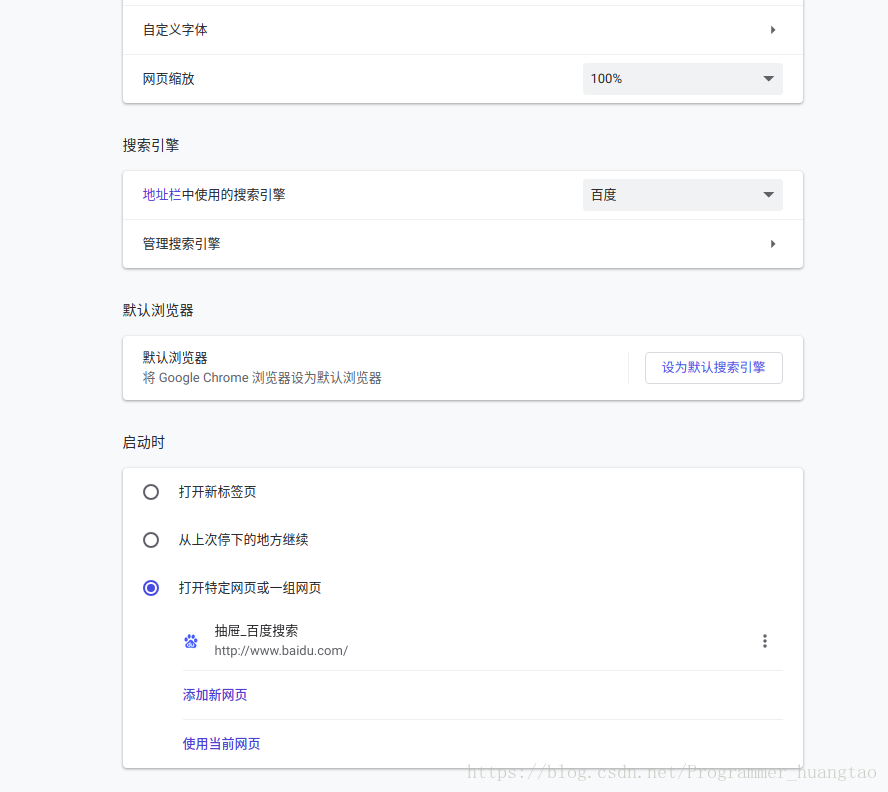
设置下滑到搜索引擎选择不是谷歌的,建议百度,把它设置成其他的引擎就行了,爬虫用的是这个谷歌浏览器程序的功能,又不是谷歌浏览器界面对吧.
2.使用谷歌
























 1509
1509

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









