



在企业数字化转型的浪潮中,IT架构的“灵活性”与“稳定性”如同驱动业务的双轮。不少企业尝试通过超融合架构突破传统IT的瓶颈,却在选型时被“分布式存储”“软件定义”等术语劝退,或是在部署后遭遇“扩容卡顿”“数据安全漏洞”等问题。其实超融合并非高不可攀的技术,从基础逻辑到落地实践,把核心问题想透就能避开绝大多数坑。今天我们就用通俗的语言拆解超融合,再结合实战经验给出避坑方案。
一、先搞懂:超融合到底解决了什么问题?
在了解超融合之前,我们得先明白传统IT架构的“病灶”。过去企业搭建IT系统,往往采用“烟囱式”部署——计算靠独立物理服务器,存储依赖专用的SAN/NAS设备,网络则需要单独配置交换机和路由策略。这种架构就像三个互不连通的仓库,一个仓库堆满了货物(存储满了),另一个却空着大半(服务器CPU利用率不到20%),资源浪费严重。更麻烦的是扩容,比如业务增长需要加存储,就得采购整套SAN设备,从申请预算到安装调试至少要2个月,完全跟不上业务节奏。
超融合基础设施(Hyper-Converged Infrastructure,简称HCI)的出现,就是用“软件定义”思维打破这种硬件壁垒。它的核心逻辑很简单:把计算、存储、网络这三大核心能力,通过软件整合到标准化的x86服务器中,让每一台服务器都既是“计算节点”也是“存储节点”,最终形成一个统一的资源池。打个比方,传统架构是“专款专用的三个独立账户”,超融合则是“一个综合账户”,钱(资源)可以根据需要自由调配,效率自然大幅提升。
超融合的核心技术:三个“引擎”缺一不可
要真正理解超融合,就必须搞清楚它的三大核心组件——这也是企业选型时最容易混淆的技术点,我们逐一拆解:
● 虚拟化引擎:计算资源的“分身术大师” 这是超融合的“计算心脏”,作用是把物理服务器的CPU、内存等资源“切片”,虚拟成多个独立的虚拟机(VM)。比如一台16核CPU、128G内存的服务器,通过虚拟化可以拆分成8台2核16G的虚拟机,分别跑财务系统、OA系统等不同业务。关键是这些虚拟机还能“热迁移”——比如某台物理服务器要维护,虚拟机可以在不中断业务的情况下,自动转移到其他节点,就像手机通话时无缝切换到另一基站,用户完全无感知。
● 分布式存储引擎:存储资源的“拼图高手” 这是超融合与传统架构的核心差异。传统存储是“集中式”的,所有数据都存在一台专用存储设备里,一旦设备故障就会“全军覆没”。而分布式存储会把数据拆分成多个碎片,像拼图一样分散存到集群的不同节点中,同时还会生成2-3个副本。就算某台服务器硬盘坏了,也能通过其他节点的副本快速恢复数据,安全性大幅提升。而且它支持“分层存储”,常用的热数据存在SSD里(读写快),不常用的冷数据存在HDD里(成本低),兼顾性能和经济性。
● 软件定义网络(SDN)引擎:网络资源的“智能交通指挥官” 传统网络需要手动配置交换机、路由器,改一个策略可能要跑遍机房。而SDN引擎用软件替代了硬件的控制功能,比如要给新上线的业务划分独立网络,不用动物理设备,在管理平台上点几下鼠标就能完成,还能实时监控网络流量,避免某类业务“抢带宽”导致其他业务卡顿。、
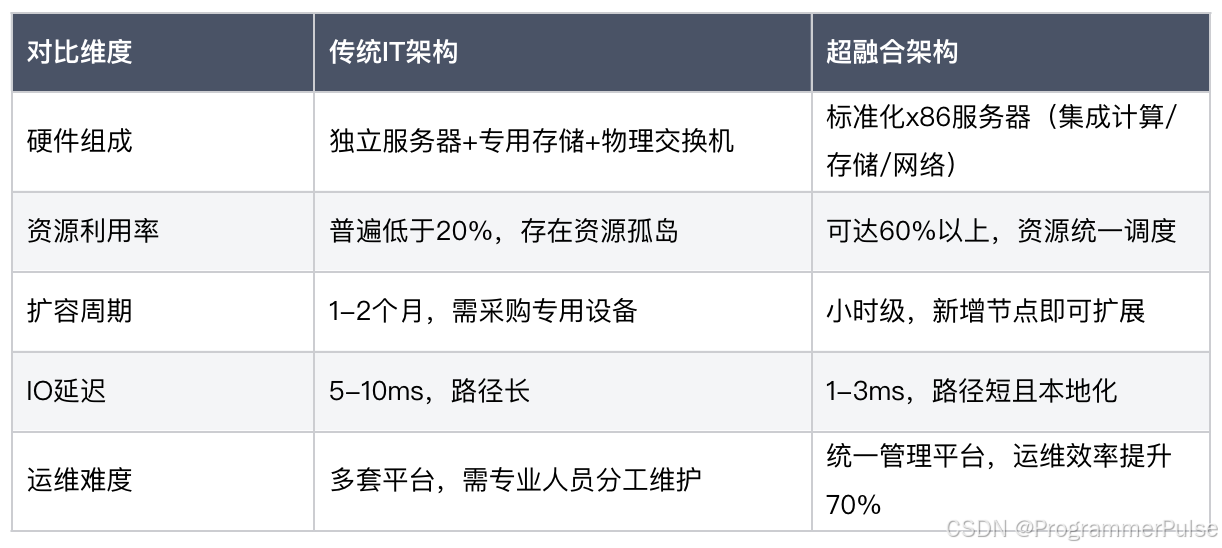
为了更直观地对比,我们整理了传统架构与超融合架构的核心差异:
搞懂了基础概念,接下来就是落地环节。不少企业觉得“买了超融合服务器就万事大吉”,结果在选型、部署、运维中踩了坑。结合上千个实战案例,我们总结出最容易出问题的5个环节:
坑1:资源规划“短视”,只看当下不看未来
很多企业选型时只算“当前账”——比如现在业务只需要10台虚拟机,就买刚好能满足的配置。但忽略了业务增长带来的资源需求变化,比如未来上线AI分析业务,会需要大量GPU资源;电商业务大促时,存储IOPS(每秒读写操作数)会暴涨。这种短视会导致“木桶效应”:CPU还够用,存储却先扛不住了,最后只能花大价钱重新升级,反而更浪费。
坑2:迷信“刚性扩展”,扩容成本陡增
超融合的核心价值是弹性扩展,但有些产品的“扩展”是伪命题——要么必须成倍增加节点(比如一次最少加3台),小业务用不上造成浪费;要么扩展时会引发数据迁移风暴,业务卡顿半小时以上。某制造企业就吃过这个亏,生产线系统扩容时,数据迁移导致MES系统中断,直接影响了订单交付。
坑3:安全只靠“防火墙”,数据成“裸奔”状态
把所有业务都放在超融合平台后,安全风险也会集中。不少企业只在网络边界装了防火墙,却忽略了平台内部的“东西向流量”(虚拟机之间的通信)安全。一旦某台虚拟机被攻击,病毒会像洪水一样横向蔓延。更危险的是,有些平台的存储数据没有加密,硬盘丢了数据就会泄露;访问控制也松散,运维人员能随意查看核心业务数据。
坑4:混合云“断连”,运维人员成“两头跑”
现在大多企业是“本地+公有云”的混合架构,但有些超融合平台是“信息孤岛”,和公有云无法无缝对接。管理员要在本地平台和公有云控制台之间来回切换,数据备份、资源调度都要手动操作。某连锁企业的财务系统就遇到这个问题,每月结账时要把本地数据手动上传到公有云做分析,光这个环节就要花2天时间。
坑5:忽略AI需求,新业务“卡脖子”
生成式AI越来越普及,不少企业想基于大模型做客户服务、数据分析,但传统超融合平台不支持GPU异构算力,也没有内置AI工具。临时拼凑GPU资源不仅部署复杂,还要组建专业的AI团队,中小企业根本扛不住。某教育机构想做智能题库系统,就因为超融合平台不支持AI推理,项目推迟了3个月才上线。
三、破局之道:青云云易捷的全场景解决方案
超融合部署的核心诉求,是“把复杂的技术留给厂商,把简单的使用留给企业”。青云云易捷超融合系统,正是从企业的实际痛点出发,把前面提到的“坑”都变成了“优势”,让超融合从“技术难题”变成“业务助推器”。
对于选型时的“组件集成麻烦”,云易捷早已提前完成了“预集成”工作——虚拟化、分布式存储、软件定义网络三大核心组件在出厂前就已经完成了上千次兼容性测试,还优化了组件间的协同效率。企业拿到设备后,接通电源、通过可视化界面完成基本配置,1小时内就能启动业务,完全不用协调多个厂商的技术人员,真正实现“开箱即用”。某医院的HIS系统部署时,就靠着这个优势,比原计划提前一周上线,保障了门诊业务的顺利开展。
在扩展方面,云易捷采用3节点起步的轻量化架构,既降低了中小企业的入门门槛,又支持“按需横向扩展”——业务增长时,新增1台节点就能同步扩展计算、存储、网络资源,扩展过程中数据零迁移,业务完全无感知。青海农担就用这个特性,从3节点集群逐步扩展到8节点,支撑了全省分公司的协同办公,资源利用率始终保持在70%以上。
安全方面,云易捷构建了“全链路防护体系”:网络层有细粒度的安全组策略,能精准控制虚拟机间的通信;存储层采用国密算法对数据进行静态和传输加密,就算硬盘损坏也不怕数据泄露;访问控制则基于零信任理念,“从不信任,始终验证”,每个操作都有日志追溯,完全符合等保2.0要求。西昌市人民医院用它承载EMR电子病历系统,就靠着这套安全体系通过了医疗数据安全等级保护测评。
针对混合云“断连”问题,云易捷通过内置的混合云网关,能和青云QingCloud公有云及AWS、Azure等主流公有云无缝对接。管理员在一个管理平台上,就能完成本地与公有云的资源调度、数据备份、灾备演练。慈铭体检就通过这个功能,把本地的影像数据自动同步到公有云,专家在外地也能随时阅片,诊断效率提升了50%。
面对AI需求,云易捷集成了轻量化AI推理平台,不用额外采购GPU设备,也不用组建专业团队。通过可视化界面,点击几下就能完成大模型部署,支持客户服务机器人、智能数据分析等常见场景。某企业的客服系统就基于云易捷的AI能力,上线了智能应答机器人,把人工客服的工作量减少了60%,客户响应时间也从5分钟缩短到10秒。
超融合的本质,是让IT架构从“支撑业务”变成“驱动业务”。青云云易捷用预集成的便捷、弹性扩展的灵活、全链路的安全、混合云的协同、AI的赋能,把超融合部署的“门槛”降到了最低。无论是中小微企业的数字化起步,还是大型企业的核心业务承载,都能找到适配的解决方案。
数字化转型不是“技术炫技”,而是“效率革命”。当超融合架构不再让你为选型纠结、为部署头疼、为安全担忧时,企业才能把更多精力放在核心业务上——这正是青云云易捷始终坚持的初心:让每一次技术落地,都能成为业务增长的“加速键”。

















 897
897

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









