




音频流格式启用数据流
在单个样本帧级别处理音频数据时,就像使用音频单元一样,仅仅指定正确的数据类型来表示音频是不够的。单个音频样本值中的位布局是有意义的,因此像 Float32 或 UInt16 这样的数据类型不够有表现力。本节将介绍 Core Audio 解决这个问题的方法。
使用 AudioStreamBasicDescription 结构
在应用程序中以及应用程序和音频硬件之间移动音频值的媒介是 AudioStreamBasicDescription 结构:
struct AudioStreamBasicDescription {
Float64 mSampleRate;
UInt32 mFormatID;
UInt32 mFormatFlags;
UInt32 mBytesPerPacket;
UInt32 mFramesPerPacket;
UInt32 mBytesPerFrame;
UInt32 mChannelsPerFrame;
UInt32 mBitsPerChannel;
UInt32 mReserved;
};
typedef struct AudioStreamBasicDescription AudioStreamBasicDescription;
由于 AudioStreamBasicDescription 这个名字很长,以下缩写为 ASBD。要定义 ASBD 字段的值,请编写类似于下面的代码:
size_t bytesPerSample = sizeof (AudioUnitSampleType);
AudioStreamBasicDescription stereoStreamFormat = {0};
stereoStreamFormat.mFormatID = kAudioFormatLinearPCM;
stereoStreamFormat.mFormatFlags = kAudioFormatFlagsAudioUnitCanonical;
stereoStreamFormat.mBytesPerPacket = bytesPerSample;
stereoStreamFormat.mBytesPerFrame = bytesPerSample;
stereoStreamFormat.mFramesPerPacket = 1;
stereoStreamFormat.mBitsPerChannel = 8 * bytesPerSample;
stereoStreamFormat.mChannelsPerFrame = 2; // 2 indicates stereo
stereoStreamFormat.mSampleRate = graphSampleRate;
首先,应该确定采样值的数据类型。此示例使用 AudioUnitSampleType 定义类型,这是大多数音频单元的推荐数据类型。在 iOS 中,AudioUnitSampleType 被定义为 8.24 固定点整数。接下来定义 ASBD 类型变量,初始化为 0 代表不包含任何数据(注意不能跳过该步,否则可能产生一些想不到的问题)。然后就是对变量赋值:
- mFormatID:格式标识符。例如 kAudioFormatLinearPCM 表示音频单元使用未压缩的音频数据。
- mFormatFlags:某些 audio unit 使用不规则的音频数据格式即不同的音频数据类型,则该字段需要不同的标志集。例如 3D Mixer unit 需要 UInt16 类型数据作为采样值且 mFormatFlags 需要设置为 kAudioFormatFlagsCanonical。
- mBytesPerPacket:每个音频包中有多少字节数。
- mBytesPerFrame:每一帧中有多少字节。
- mFramesPerPacket:每个包中有多少帧。
- mFramesPerPacket:每个包中有多少帧。
- mBitsPerChannel:每个声道有多少位。
- mChannelsPerFrame:每一帧中有多少声道。
- mSampleRate:采样率。
在哪里以及如何设置流格式
必须为 audio processing graph 中的关键点设置音频数据流格式。在其他点,系统会设置格式。在其他点上,音频单元连接将流格式从一个音频单元传播到另一个音频单元。
iOS 设备上的音频输入和输出硬件具有系统确定的音频流格式。这些格式总是未压缩的、交错的线性 PCM 格式。该系统在 audio processing graph 中将这些格式强加到 I/O 单元的外向两侧,如图 1-8 所示。
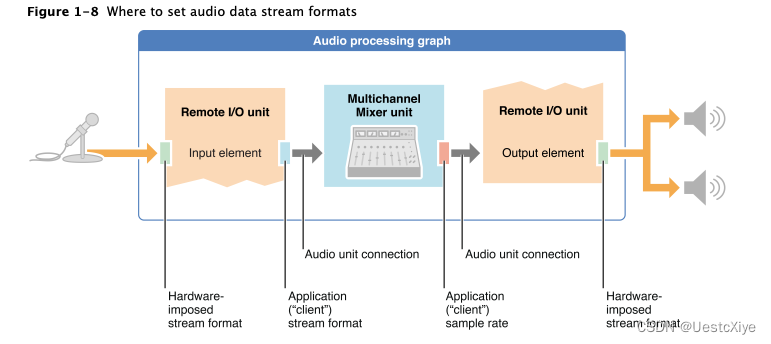
在图中,麦克风代表输入音频硬件。系统确定输入硬件的音频流格式,并将其强加到远程 I/O 单元输入元素的输入范围内。同样,图中的扬声器代表输出音频硬件。系统确定输出硬件的流格式,并将其强加到远程 I/O 单元输出元素的输出范围上。
应用程序负责在 I/O 单元元素的内侧建立音频流格式。I/O 单元在您的应用程序格式和硬件格式之间执行任何必要的转换。应用程序还负责在 graph 中需要的任何地方设置流格式。在某些情况下,例如在上图的多通道混合器单元的输出中,只需设置部分格式,特别是采样率。
如图 1-8 所示,音频单元连接的一个关键特征是,连接将音频数据流格式从源音频单元的输出传播到目标音频单元的输入。这是一个关键点,因此需要强调:流格式传播通过音频单元连接进行,并且只在一个方向上——从源音频单元的输出到目标音频单元的输入。
流格式传播发生在音频处理图形生命周期的一个特定点,即初始化时。利用格式传播的优势可以显著减少需要编写的代码量。例如,当将多通道混音器单元的输出连接到远程 I/O 单元进行播放时,无需为 I/O 单元设置流格式。
虽然我们可以通过 ASBD 灵活的设置音频数据流的属性,但是建议还是使用当前设备硬件默认使用值。当这样做时,I/O 单元不需要执行采样率转换,这将最大限度地减少功耗,并最大限度地提高了音频质量。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











