




 本文记录了一次在HBase环境下使用MapReduce进行行数计算时遇到的问题及解决方案,详细分析了错误原因,包括jar包冲突和版本问题,并提供了正确的执行命令和环境配置建议。
本文记录了一次在HBase环境下使用MapReduce进行行数计算时遇到的问题及解决方案,详细分析了错误原因,包括jar包冲突和版本问题,并提供了正确的执行命令和环境配置建议。
问题
公司同事在学习Hbase 视频中有一段是Hbase 使用MapReduce 的官方实例使用 RowCounter 计算表的行数。
执行命令:
/usr/bdapp/hadoop-2.7.7/bin/yarn jar /usr/bdapp/hbase-2.1.7/lib/hbase-server-2.1.7.jar RowCounter test:user
抛出错误如下:
Exception in thread "main" java.lang.ClassNotFoundException: RowCounter
at java.net.URLClassLoader.findClass(URLClassLoader.java:382)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
at java.lang.Class.forName0(Native Method)
at java.lang.Class.forName(Class.java:348)
at org.apache.hadoop.util.RunJar.run(RunJar.java:219)
at org.apache.hadoop.util.RunJar.main(RunJar.java:141)
这是一个很明显的错误:类找不到
分析一下原因:
1、jar包冲突:
排查方式:打印执行的环境。发现对应的jar包存在且无冲突。
2、版本问题,其中取消了该类。下载源码包,关键字查询确实不存在该类。
找到当前环境对应的官方文档:
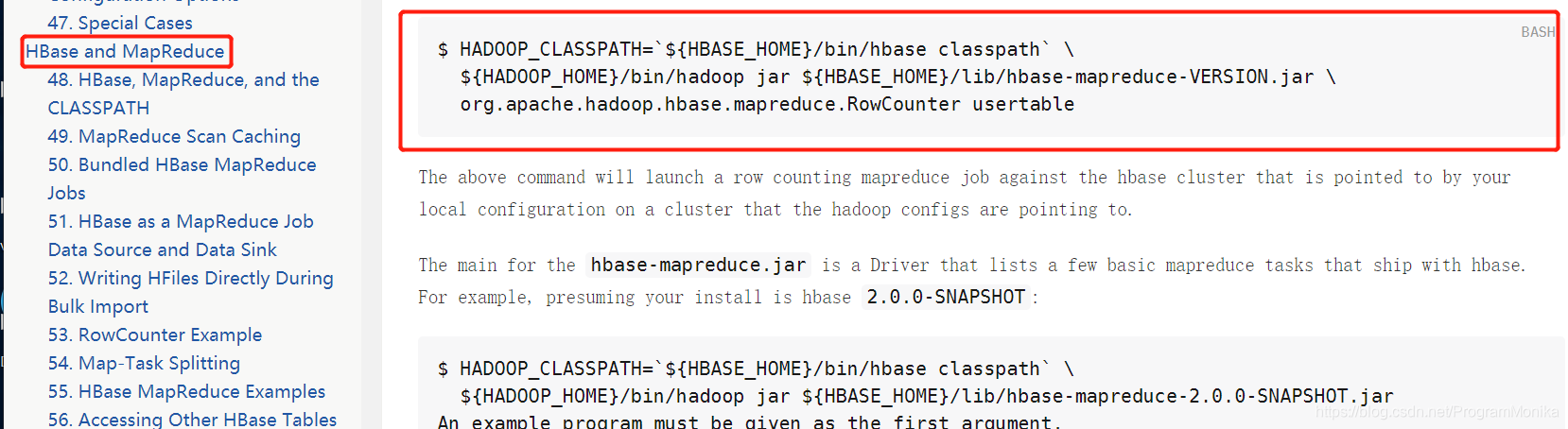
执行该命令报错:
Unknown program 'org.apache.hadoop.hbase.mapreduce.RowCounter' chosen.
Valid program names are:
CellCounter: Count cells in HBase table.
WALPlayer: Replay WAL files.
completebulkload: Complete a bulk data load.
copytable: Export a table from local cluster to peer cluster.
export: Write table data to HDFS.
exportsnapshot: Export the specific snapshot to a given FileSystem.
import: Import data written by Export.
importtsv: Import data in TSV format.
rowcounter: Count rows in HBase table.
verifyrep: Compare data from tables in two different clusters. It doesn't work for incrementColumnValues'd cells since timestamp is changed after appending to WAL.
上边这段话意思是:
org.apache.hadoop.hbase.mapreduce.RowCounter
没有这个programe
有效的是下边这些:
export
rowcounter
这些命令
最终结果:
/usr/bdapp/hadoop-2.7.7/bin/hadoop jar /usr/bdapp/hbase-2.1.7/lib/hbase-mapreduce-2.1.7.jar rowcounter test:user
而后忽然发现文档有提醒:
$ HADOOP_CLASSPATH=`${HBASE_HOME}/bin/hbase classpath` \
${HADOOP_HOME}/bin/hadoop jar ${HBASE_HOME}/lib/hbase-mapreduce-2.0.0-SNAPSHOT.jar \
rowcounter usertable
所以建议大家学习时和你的教学视频使用一致的环境。
或者首先思考问题成因,一步一步解决问题。
实在不行就及时想朋友或其他人求助。

















 4282
4282

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









