




 本文详细解析了 Java 中 LinkedList 的工作原理及其多种应用场景,包括如何正确使用 LinkedList 提供的不同 API 实现栈和队列的功能,以及 toArray 方法的具体实现与使用技巧。
本文详细解析了 Java 中 LinkedList 的工作原理及其多种应用场景,包括如何正确使用 LinkedList 提供的不同 API 实现栈和队列的功能,以及 toArray 方法的具体实现与使用技巧。
目录
Java为不同的数据结构提供了不同的API,一定要根据需要使用正确的API!!
LinkedList把pop,push,peek这几个API都给了队列
因为链栈和链队只有插入的时候不同,pop和peek都是一样的,所以,可以用Queue的API来实现栈
如果是一般情况,需要用栈时,可以直接使用Java自带的Stack;需要用队列时,使用Java的LinkedList,其API都是一样的:
LinkedList.toArray()
*************************************************************************************************************************************************

编译阶段(build)即报错:

说是LinkedList.toArray()返回类型是Object[],和array的类型——Integer[]不匹配,那么使用强转试试(向下转型):

注意:
① 使用(Integer[])强转,而不是 (Integer)
② 强转之后,编译时期(build)不报错,但是运行时(run)报错了
还是类型不匹配:Exception in thread "main" java.lang.ClassCastException: [Ljava.lang.Object; cannot be cast to [Ljava.lang.Integer;
为什么呢,按说在toArray时候只是将LinkedList的一个个元素转化为了数组而已,考虑到LinkedList.toArray()的返回值是Object[]而不是Integer[]:

应该实现时候使用了向上转型,此时再向下转应该没问题啊,看下面的例子,自定义Father——Son:

还是得回源码看,因为通过实验也注意到:Father father这个引用的的确确是从New Son()来的,而LinkedList.toArray()的返回值类型虽然是Object[],但是不是从Integer[]转过来的还是存在疑问。
LinkedList.toArray()源码:

源码很简单,一目了然
使用了new Object[]去初始化的result,而不是
![]()
然后利用LinkedList真正存储结构Node,即自维护的指针first来遍历,一个一个装进Object[] 类型的result中,
但是注意!!!由于初始化时已经确定了result的类型:标准的new Object[],而不是上转型得到的,所以LinkedList一装进去,类型信息就丢失了。。。(到底存进去了什么是个问题。。。)
这就难怪之前使用强转会报错了
其实那里还有个细节:
在不使用强转时,build阶段直接报错;使用强转时,run阶段才报错,编译阶段通过了。
这是因为不使用强转时,编译器在编译编译阶段即可发现LinkedList.toArray()的类型(原始的Object[]类型)和array定义的类型(Integer[])不一致,且二者(Object[]和Integer[] )没有extends,implements关系)直接报错; 但是在使用强转以后,在编译阶段,编译器看不出什么毛病:array的确是按照规范(类型相同,或者子类)赋值的,通过!!
但是我们知道,在运行阶段会真正地去运行.toArray()代码,此时会发现当时写的(Integer[])这个casting根本是想当然,是转不了的,所以报错。
那么问题来了,现在就是有“将LinkedList转成array”的需求,该怎么办呢
看源码:

咦,怎么样,竟然还有一个toArray() 方法,去看实现:
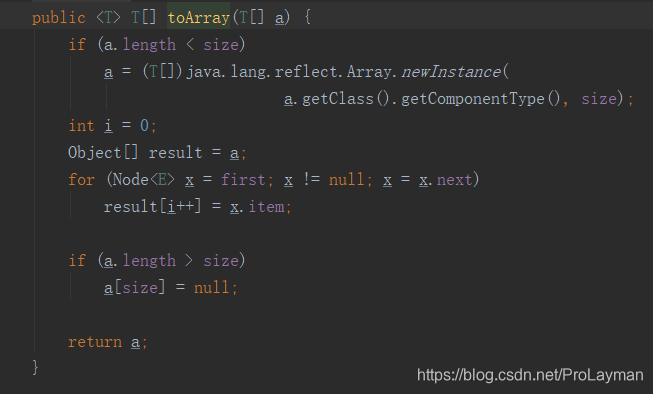
分析一下:

这个size是LinkedList的属性(跟first一样),保存着LinkedList的长度的。
newInstance方法:


其实说的很清楚了:创建一个componentType类型,长度为length的的数组
好奇地话可以去追踪newArray()方法看看(顾名思义已经知道是干啥了):

好了,是个native方法,不用追究了,嘻嘻。
再回 public <T> T[] toArray(T[] a) 源码:
即:
① 如果传进来的这个a(T类型的数组)的长度小于size,则新建一个T类型,长度跟当前LinkedList一样大小的数组,并用a指向它
即 a 现在指向新数组了。
②
![]()
注意,这里真的类似于之前说到的,第一个无参toArray()没有实现的:
![]()
方式了。
即现在的result是T[]上转型而来的
③ 塞进去

④ 如果进来的a.length大于size,则直接返回null。

其实个人认为这一句可以写在最前面,虽然效果上基本没区别,毕竟如果的确a.length > size,第一个if也不会进,直接来这里执行。
但是这一段写最前面更利于代码阅读,也更符合处理问题由简单到复杂的思路。(为什么划掉后面谈)
⑤ 返回
OK,源码读完,也知道怎么用了:传一个同接收toArray()返回值的引用一样类型的参数进去,即告诉LinkedList我想要你返回一个什么样类型的数组给我,现在给我吧:

看这一行:
![]()
这种方法的好处是,传入的参数长度为0,这样不管LinkedList有没有元素,有多少元素,都不会进入
都不会得到一个null值
这里插一句嘴,new Integer[0]的效果其实就相当于这样:
Integer arr = {};
即不是null,但是是个数组对象,有属性length,值为0,没有任何元素。
另外还有一个常用的方法:

看这一行:

这样做有什么道理吗?
咋一看起来好想挺浪费空间的,toArray()只需要你告诉想要返回的类型啊,你这样new一个长度为list.size()的Integer数组给它,不是浪费么?
源码再探:
手工模拟,有没有发现当传入a.length = size的时候竟然并没有相应的判断条件,这其实也是之前阅读源码的疏忽————把相等的情况忘了,看源码发现,如果相等,则直接执行i = 0开始的部分
即
①
a.length < size -----> new T[size] ,元素全部塞进去
a.length >= size -----> 不再new空间,直接全部塞进去
②
接下来处理a[size]:
如果a.length > size,则将a[size]这一个元素置为null;相应地,如果a.length <= size,经过第一步的处理,现在都是a.length = size了,刚好塞满。
③
最后返回a!!! not result!!!
可以看到,其实是借着Object[] 类型,result完成对a的修改,最后返回的还是a本身(当然,如果length < size,那么已经是new出来的a了)
此时再看
是不是很有道理?
这样在toArray内部就不用new 新空间,直接在原空间上的修改。因为也没有 > size,所以不用置null的操作,而
![]()
在内部还要通过反射机制重新new空间,很麻烦。
前者把new空间的工作自己做了,nice。
故建议使用第二种方式:
另外,如果看了本文的“Java数组引用的参数传递”这小节,那么可以知道,如果方法中是直接使用下标如arr[i]进行操作,则可以直接传引用,方法中的所有操作都会影响到原数组本身;如果方法中是对数组名本身进行修改,那么只是修改了原数组名的拷贝而已,不会影响到原数组本身。
再回头看源码:
看到:
a.length < size -----> new T[size] ,a本身被改变了,指向了堆中的新位置 ———> 没有影响到实参本身
a.length >= size -----> 不再new空间,都是对a[i]进行操作,a本身没有改变 ———> 影响到实参本身
故当我们使用第一种方式:
![]()
一定要用toArray()的返回值对array重新进行赋值
而第二种方式:
由于此时toArray()方法中就是对array本身的改变,所以其实根本就不用再赋值,传参即可:
![]()
实验一下:

果然可以
也可以想见,对于第一种方式:
![]()
如果也这样使用:
![]()
或者

必然是不行的,因为此时进入的是toArray()的if(a.length < size)条件中,new 了新的数组覆盖a的值,但是外部的实参——array并不能接收到,还是原值,验证及结果如下:

果然,此时array还是定义时候的
为空。
果然啊,实验和理论是相辅相成的!! 要有扎实的基本功!!
所以本节的最后结论:
1) 推荐使用
或者

刷题时,LinkedList的使用
*************************************************************************************************************************************************
先看继承关系:

注:这是使用IDEA自带功能(Diagrams)生成的,I代表Interface,C代表class,开放的锁表示public。
蓝色(和代表class的C一个颜色)的实线代表类的继承关系,绿色(和代表interface的I一个颜色)的实线代表interface的继承关系,绿色的虚线代表interface多实现关系。
也可知,对于Java来说,① 蓝色只有实线没有虚线 ② 绿色虚线的出发点肯定是class而不会是interface ③绿色实线出发只会是interface
在介绍看LinkedList之前,来回顾一下LinkedList——链表这种数据结构:

就如图中表示的,链表头部可以做插入(头插法),也可以做删除,但是链尾只能做插入(尾插法),不能做删除(没有要删除节点的前驱的指针,删不掉(无法置null))。
那么,可以这么说,删除已经确定了在链头,插入有两个选择:头部 ,尾部
如果选择头部插入,则删除插入都在一头,很明显,这是个Stack,确切地说这是个链栈;
如果选择尾部插入,则删除插入不在一头,很明显,这是个Queue,确切地说这是个链队。
所以说,从链表结构本身的特点来看,它是同时符合Stack和Queue两个数据结构(逻辑结构)的特点的。
(可以延申一下看,数组呢,1)栈肯定直接支持的,虽然对于上限不确定的栈并不行;2)队列同样支持,考虑到多次push,pop操作以后造成空间浪费,可以使用数组构成循环队列,当然可以看到,数组实现不循环队列时,不仅要指定队列上限,还要限制push.pop操作次数,可以说,是不可能投入使用的实现;即使实现循环队列,也要确定队列上限。
所以总体说来,数组也提供了对Stack,Queue的支持,只是支持度并不如链表)
在知道链表同时提供对栈和队列的支持后,再看上面的继承关系图,发现很有趣的一点:LinkedList同时实现了List和Deque( Queue )接口,即还真像之前分析地那样:链表可以实现栈,也可以实现队列。
但是,有一点就迷糊了,虽然都支持,但是同时实现不是乱了套了:我现在push一个数,Java怎么知道我是当作栈来使用的——头插法,还是当作队列来使用的——尾插法?
答案是:
Java为不同的数据结构提供了不同的API,一定要根据需要使用正确的API!!
先看个例子:

看见了吧,用的是push()和pop(),从结果来看,LinkedList“此时”是个队列(FIFO)。
去看源码:

其实从linkLast() 顾名思义已经知道了,并且文档已经说明了:Appends the specified element to the end of this list
还是看一下源码:

====>利用LinkedList自己维护的尾指针——last,把节点E e添加到原链表的末尾
再看pop():

很清楚:In other words,removes and returns the first element of this list
removeFirst()源码:

unlinkFirst(f)源码:

所以,很清楚,LinkedList把pop() 和 push() 这两个API给了队列,再看Queue和Stack另外一个重要的API:

果不其然,peek跟pop一样,都是读/写 first,所以这么说:
LinkedList把pop,push,peek这几个API都给了队列
那么问题来了,如果我想用LinkedList实现栈的功能呢,有API吗?
答案是必然的,看源码:
push:

pop:
![]()
peek:

即,其实对于pop,push,peek操作(不是方法名)而言,LinkedList都提供了两套API,虽然看继承关系就知道这其实是Deque的产物
但是一旦知道了链栈和链队的原理(分别在哪里插入),那么直接就可以拿过来实现了,例如使用上面的API实现栈:

进一步地
因为链栈和链队只有插入的时候不同,pop和peek都是一样的,所以,可以用Queue的API来实现栈
上面的代码还可以这样改:

这在刷题时时很有用的,若非题目给定了返回类型,例如只能返回List类型,此时可以灵活使用API
如果是一般情况,需要用栈时,可以直接使用Java自带的Stack;需要用队列时,使用Java的LinkedList,其API都是一样的:
push(),pop()和peek()
这里再提一句,可以看到,addFirst(),peekFirst()和removeFirst()方法其实都是Deque的API,
实际上,这三个API都有两套:first和last,这同时也说明了:
Deque——双端队列是队列和栈的超集,合理使用就能实现队列和栈,并且比二者更自由——可以随意地从两端pop,push。

















 988
988

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









