




 age<5
age<5
先看例子:
建立了name_age_address组合索引:

最普通的全匹配索引查询:

最左匹配不用多说;
name_age_address相当于建立了三个索引:
name索引,name_age索引,name_age_address索引。
可以分别看一下长度:
name —— 377:

name_age —— 381:

name_age_address —— 533:

where的限制条件只能只用这“三个”(其实还是一个)索引中的一个,要么就完全没有使用(没有符合最左匹配原则),如:
没有name,只有age_address,索引失效:

漏掉age,只有name_address:
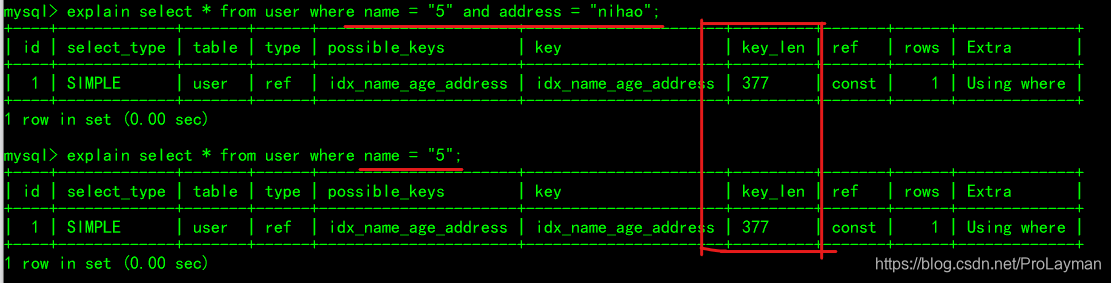
可以看到,由于age缺失,索引到age列即失效,即使用where name = "5"和where name = "5" and address = “nihao”是一样的。这也是了解了机制之后,我们才能更好地利用MySQL的例证之一。
那么除了缺失,其他什么情况会使索引匹配终结呢?
一个重要的一项是:范围查询

可以看到,name_age_address索引的age使用范围限制条件时,利用的索引长度只有381而不是533,即使用的是name_age索引,到age就失效了。原因很好理解,考虑B+树的结构,数据的相对大小是像“字典序”一样,从左往右定义的,举个例子,B+树的最后一层(叶子层),(name , age, address)的三元组,("a", 11, "上海")必然是在 ("b", 1, "北京")左侧的。但是(XXX, 11, "上海")和(YYY, 1, "北京")(注意name是未知)的相对顺序是不定的。
不过应该注意到,MySQL的查询是寻找代价最小的执行计划,不是说理论上可以利用的索引就一定利用了,用上面的理论,看下面的例子:

按说age > 1 and age < 5 和 age > 1没有本质区别,这里可以看到根本就没有使用任何索引,退一步讲,就算使用不了name_age索引,至少也可以使用name索引,在name_age_address B+树的叶子层拿到一个范围的数据后,带着该id去主表中拿数据,再使用age > 1 and age < 5 and address = "天津"进行普通的where筛选。现实是,一个索引都没有用,直接走全表扫描。目前不知道是MySQL在编译阶段就确定了不走任何索引(看见闭区间直接不走blablabla),还是查询优化器计算得出走索引带来的优化太小(name的筛选条件过滤得太少),这样得到的成本还不如直接走全表扫描(省去了查找name_age_address 索引树的过程)。
当然,这里都不是本文要讲的重点 —— like不像范围查询,竟然可以继续进行索引匹配。
看演示:

按说like就像查字典一样,name like "a%"只会匹配到所有name以a开头的记录,接下来索引匹配就终结了,就像上面 age > 1就不能继续匹配address字段一样,在叶子层取了n个小区间,每个小区间内都满足name = "5" and age > 1,但是内部的address没有进行判断了,直接拿着这n个小区间内的id去主表中取记录,再对这些记录进行过滤(address = "天津")。更不要说age > 1 and age < 5时,直接完全不走扫描。
但这里的name like "a%"竟然一直匹配到索引结束,即 name like "a%"会直接找到当前节点的name首字母为a的节点,以该节点为根的B+树必然全部满足条件,此时对该B+树使用age_address索引即可。
那么按这个理论,name = "5" and age > 1可以完全匹配索引吗?
不能,注意,name like "a%",这里的like "a%"其实表现在B+树上并不是一个范围值,而是一个确定值,建立B+树时,一定以单个字符为单位建分支节点,如ab和ac一定是同层不同节点。
按说age也可以啊。。。不然age > 5是怎么实现利用的。。。。
另外注意,name like “%5”,“%5%”都是不能利用索引的,而name like 5可以。

















 957
957

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









