




yolov8模型框架
模型框架
简述yolov8不同size模型简述
在最开始的yolov8提供的不同size的版本,包括n、s、m、l、x(模型规模依次增大,通过depth, width, max_channels控制大小),这些都是通过P3、P4和P5提取图片特征;
正常的yolov8对象检测模型输出层是P3、P4、P5三个输出层,为了提升对小目标的检测能力,新版本的yolov8 已经包含了P2层(P2层做的卷积次数少,特征图的尺寸(分辨率)较大,更加利于小目标识别),有四个输出层。Backbone部分的结果没有改变,但是Neck跟Head部分模型结构做了调整。这就是为什么v8模型yaml文件里面(GitHub地址)有p2这个模型;
新增加的这个P6,是为了引入更多的参数量,多卷积了一层,是给xlarge那个参数量准备的,属于专门适用于高分辨图片(图片尺寸很大,有大量可挖掘的信息)的版本。
- model=yolov8n.ymal 使用正常版本
- model=yolov8n-p2.ymal 小目标检测版本
- model=yolov8n-p6.ymal 高分辨率版本
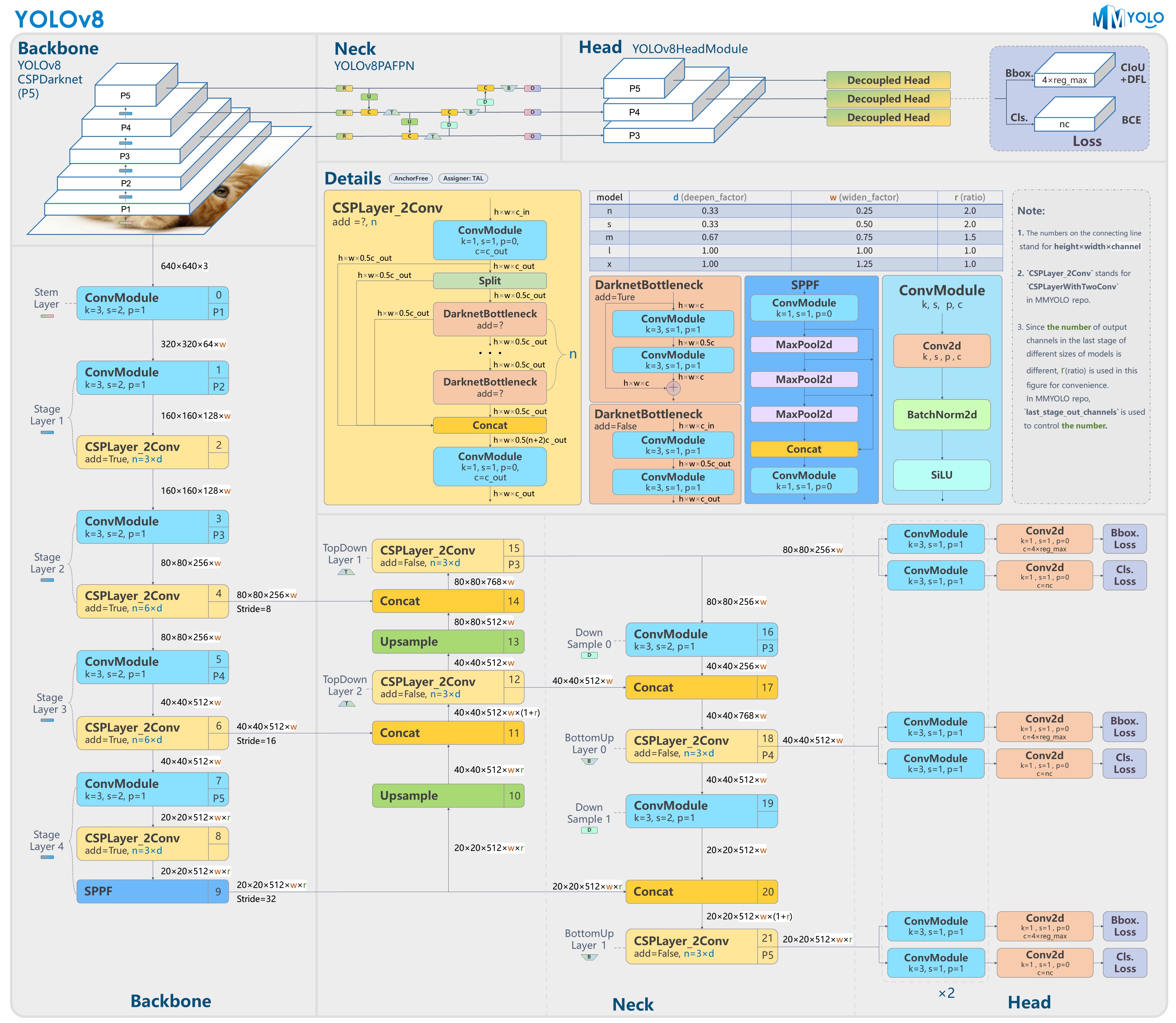
模型结构分析
现阶段yolo目标检测模型主要分为输入端、Backbone、Neck和Prediction四个部分,其各部分作用为:
- 输入端:缩放图片尺寸数据、适应模型训练;
- Backbone:模型主网络,通过卷积层数的增加,提取P1-P5不同感受野的feature map,依次感受野逐渐增加;
- Neck:呈现FPN和PAN结构,其中FPN (feature pyramid networks):特征金字塔网络,采用多尺度来对不同size的目标进行检测;PAN:自底向上的特征金字塔。这样结合操作,FPN层自顶向下传达强语义特征,而特征金字塔则自底向上传达强定位特征,两两联手,从不同的主干层对不同的检测层进行特征聚合。
- Prediction:为model框架中的Head头,用于最终的预测输出,P3 -> P4 -> P5过程中,感受野是增大的,所以依次预测目标为小 -> 中 -> 大。
输入端
常规做法
在常用的目标检测算法中,不同的图片长宽都不相同,因此常用的方式是将原始图片统一缩放到一个标准尺寸,再送入检测网络中。比如Yolo算法中常用416×416,608×608等尺寸,比如对下面800*600的图像进行变换。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 11万+
11万+






 到【灌水乐园】发言
到【灌水乐园】发言







