




 本文介绍了一种利用3D点云的2D视图进行形状识别和检索的方法。通过CNN从多个视角提取特征,进行分类,并利用低秩马氏距离度量提升检索性能。
本文介绍了一种利用3D点云的2D视图进行形状识别和检索的方法。通过CNN从多个视角提取特征,进行分类,并利用低秩马氏距离度量提升检索性能。
Main Idea
利用3D点云的一圈投影的2D view进行CNN提取特征,再整合多个view的特征,进行classification,最后为了提高retrieval的准确率,利用一个映射WWW把神经网络输出的特征ϕ\phiϕ映射到一个低维空间上,得到一个更加紧凑的特征WϕW\phiWϕ,使得同类的shape的特征在定义的distance上个更接近,不同类的更远。
Implement
- Matlab CNN库
- Caffe
Input
有两种相机安装方式来得到views
- 假设shape都一致朝着z轴方向,所以在赤道方向每30∘{30^ \circ }30∘投影一张图,一共12张图。
- shape没有一致的朝向,假想一个正十二面体包围shape,每一个顶点放一个相机,正十二面体有20个顶点,所以有二十张view,然后每个相机沿着穿过相机和shape centroid的轴旋转0∘{0^ \circ }0∘,90∘{90^ \circ }90∘,180∘{180^ \circ }180∘,270∘{270^ \circ }270∘产生4个views,一共80个views。这部分代码实现是先定义好旋转矩阵,然后用matlab的mesh函数把mesh画出来然后截图(save figure)。因为不需要深度所以可以不用渲染引擎。
1.(形心好像是由每个面的形心一面积加权得来的?输入是一个CAD模型,shape由许多个mesh表示,这样算形心是可以的,但是点云不行,因为点云都没有面的概念,由点云算形心也是VoteNet要解决的问题)
Recognition
image descriptors
使用VGG-M模型,主要结构为 conv[1…5]+fully layer[6…8]+softmax classification layer。fc7输出作为image descriptors。这部分网络用ImageNet的image预训练,然后用3Dshape的2Dviews进行fine-tune
classification
用one-vs-rest的SVM进行分类,推理的时候直接把12(或者80)个views的值加起来,选择值最高的哪个类作为该shape的分类
(不是前面有一个softmax为什么还要用SVM???之后结合代码看看)
retrieval measure
先定义distance or similarity measure如下,其中nx{n_x}nx为shape xxx的descriptor的数量,ny{n_y}ny为shape y的descriptor的数量。xi{x_i}xi为shape xxx的第iii个2D view的descriptor。
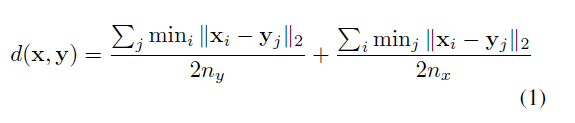
Aggregate
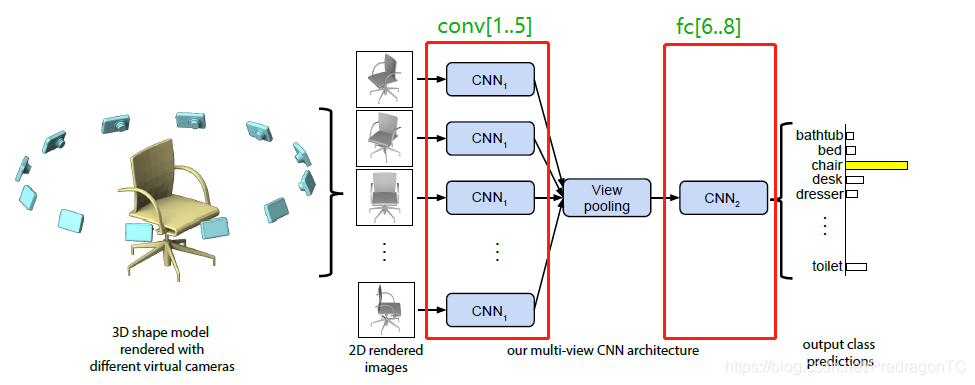
但是很明显,这个distance的定义是O(nx×ny)O({n_x} \times {n_y})O(nx×ny)的所以这种直接用2D views去实现retrieval的效率比较低,所以用了如图所示的结构,在上面所说的image-based CNNs中间加了一个view layer。所有的2D views都如前面所说先通过共享参数的CNN1(前面说的8层网络的的前半部分)然后在view pooling layer进行整合,最后送入CNN2(前面说的8层网络的的后半部分)。view pooling layer就是element-wise maximum operation across the views。经实验证明view layer加在conv5后面是最好的,就是最后一层convolution layer。
(这部分不是很确定还需要代码证实,但是应该是这样)
Low-rank Mahalanobis metric
前面的fine-tune提升了classification的性能但是retrieval的性能并没有直接的提升。为了提升retireval的性能,利用一个Mahalanobis metric W{\bf{W}}W把前面CNN2出来的ddd维descriptor ϕ\phiϕ转换为ppp维descriptor Wϕ{\bf{W}\phi}Wϕ。使得属于same category的shape 的distance尽量小,different category的shape 的distance尽量大。W{\bf{W}}W是一个在数据中心学出来的参数,下面说学习策略。定义 a=1a=1a=1 if shape x\bf{x}x and shape y\bf{y}y belong to same category and a=−1a=-1a=−1 otherwise。所以对于全部的train shape,有a(b−d(x,y))>1a(b - d(\bf{x},\bf{y})) > 1a(b−d(x,y))>1。其中b 是一个阈值,d(x,y)>bd(\bf{x},\bf{y})>bd(x,y)>b 就认为shape x\bf{x}x 和shape y\bf{y}y 是same category,b也是一个需要学习的参数。所以目标函数如下:
argminW,b∑x,ymax[1−a(b−d(x,y;W)),0]\arg \mathop {\min }\limits_{{\bf{W}},b} \sum\limits_{{\bf{x}},{\bf{y}}} {\max [1 - {\rm{a}}(b - d({\bf{x}},{\bf{y}};{\bf{W}})),0]}argW,bminx,y∑max[1−a(b−d(x,y;W)),0]
(单独训练or与CNN一起训练?,猜测是用classification训练一个可以得到descriptor的网络,然后直接用这个网络得到的descriptor去训练这个W{\bf{W}}W和bbb)
https://www.robots.ox.ac.uk/~vedaldi/assets/pubs/simonyan13fisher.pdf

















 766
766

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









