 STAR:卫星视频目标跟踪的统一时空融合框架
STAR:卫星视频目标跟踪的统一时空融合框架





目录
项目地址:STAR
原文中文翻译
摘要:
卫星视频目标跟踪(SVOT)技术为地表观测提供了全时空维度的分析能力,但现有方法受限于数据稀缺性、模态局限性、范式差异性及多维特征利用不足等问题,导致性能瓶颈难以突破。本研究提出统一时空融合框架STAR以解决上述挑战:首先通过场景增强模块(SEM)生成优化的多模态表征;进而设计提取-关联-适配模块(ECAM),采用融合局部与全局关系建模的多模态分层Transformer架构,协同实现特征提取、关系学习与域适应;同时引入时序解码结构,通过注意力传播机制整合深层时间特征;最后构建惯性导航模块(INM)建模物理时序特征,包含用于评估跟踪置信度的感知选择器,以及管理异常干扰与连续轨迹的惯性导航方案。受提示学习机制启发,STAR仅需微调极少量参数即可在多个SVOT基准测试中取得竞争优势。实现细节与评估结果详见https://github.com/YZCU/STAR 。
关键词:多模态跟踪,目标跟踪,卫星视频,时空融合
I. 引言
卫星视频目标跟踪(SVOT)旨在在给定初始状态的情况下,准确确定后续帧中目标的状态,其应用涵盖交通分析、国家安全和海洋监测等领域。与通用设备拍摄的通用视频(GV)相比,SVOT具有独特的特征。如图1所示,由于低分辨率和长距离卫星拍摄,目标占据的像素较少,空间特征有限(即弱目标),使得精确定位变得困难。此外,卫星视频(SV)是从高速卫星平台上拍摄的。非静止背景中的小目标容易受到背景杂波(BC)、遮挡和密集相似性(DS)等异常干扰。由于以下几个因素,实现鲁棒的SVOT仍然具有挑战性。
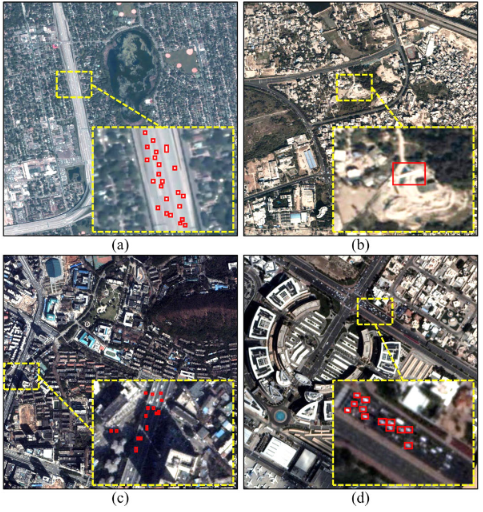
图1 卫星视频(SV)场景的可视化说明
a) 弱目标(Weak Objects)
b) 背景杂波(Background Clutter, BC)
c) 部分遮挡与完全遮挡(Partial Occlusion and Full Occlusion)
d) 密集相似性(Dense Similarity, DS)
由于以下几个因素,实现鲁棒的SVOT仍然具有挑战性。
数据稀缺:高质量SVOT数据集的稀缺性阻碍了鲁棒表示模型的发展,尤其是对于数据驱动的方法而言。
模态限制:弱目标更容易受到背景干扰的影响。依赖原始模态可能在具有挑战性的场景中失败,尤其是在低光场景下。
范式差距:SVOT方法主要采用相关滤波器和孪生网络的范式。近年来,基于Transformer的跟踪方法吸引了越来越多的关注,并设定了新的性能基准。
多维特征利用不足:空间和时间特征的利用不足限制了SVOT中对象的有效时空建模,阻碍了对关键帧内/帧间线索的捕捉。
为应对数据稀缺问题,一些数据驱动的方法如TATrans、SiamS2F和HRSiam在大规模通用图像/视频集(如ImageNet、COCO、LaSOT、GOT-10k和TrackingNet)上进行训练,然后在SVOT数据集上进行评估。然而,由于GV和SV场景之间的显著差异,这可能导致较差的泛化能力。其他方法如SiamTM和SiamMD在SVOT数据集上进行全微调。然而,全微调资源消耗大,并且相比提示微调,存在过拟合的风险。虽然现有的直接在原始SV模态上进行跟踪的方法取得了竞争性的结果,但仍有改进的空间。为缓解模态限制,方法如SATDark和MTE-ISVD在跟踪前通过视频增强调整SV对象。虽然这些方法显示出竞争性的结果,但在原始模态被丢弃时可能表现不佳,因为它们依赖增强算法在不同场景中的泛化能力。
范式差距在SVOT中仍然显著。传统的跟踪范式,如相关滤波器和孪生网络,已被广泛采用。例如,几个SVOT方法,包括HKCF、HMTS和CFME,都是基于KCF。其他如DF、CPKF、DOCPF和MACF则受到相关滤波器如CSK、DSST、STRCF、Staple和CPF的启发,取得了竞争性的结果。基于DiMP的最新追踪器(如HRLT和RRT)也展示了令人印象深刻的结果。对于基于孪生的追踪器,如REPS和SiamMDM扩展了SiamFC,而HRSiam和JSANet则建立在SiamRPN的基础上,平衡了准确性和速度。最近,基于Transformer的追踪器在GV跟踪中取得了显著进展。这些方法可以分为CNN-Transformer和全Transformer模型。受CNN-Transformer模型(如Stark和TrDiMP)的启发,包括SVLPNet、TATrans和TransMPP在内的几个SVOT算法设定了新的性能天花板。然而,依赖CNN进行特征提取会限制其完全捕捉全局表示的能力。
多维特征可以广泛地分为空间特征和时间特征。空间特征捕捉外观表示,使用手工特征和深度特征。手工特征如HOG、颜色名称、Gabor和颜色直方图被广泛用于捕捉SV对象的纹理和结构信息,如在MBLT、SATDark和CPKF中。深度外观特征在SVOT方法中常见,包括浅层编码低级信息的高空间分辨率以实现精确定位,以及深层捕捉对某些对象变化不变的高层语义信息。它在SVOT方法如SiamMDM、CSLT和SiamS2F中表现出色。然而,CNN可能限制帧内上下文中深度外观特征的有效表示。时间特征,包括物理和深度时间成分,对于捕捉SVOT中的帧间动态至关重要,尤其是在遮挡场景中。物理时间特征使用指数平滑、卡尔曼滤波、运动轨迹平均和高斯混合模型,已被集成到CFME、MACF、DOCPF和SATDark等方法中以分析运动模式。相比之下,深度时间特征虽然重要,但在SVOT方法中经常被低估,如REPS和SiamS2F更关注空间方面。为解决这一差距,一些追踪器已经结合了动态模板(如SiamMDM和TATrans)、时间关系学习(如RRT和HRLT)和时间传播(如TransMPP)。这些方法通过端到端训练实现空间和时间感知,但通常在手动更新策略和超参数(如更新阈值和间隔)方面存在困难。因此,在SVOT中,时空融合仍有很大的改进潜力。
受上述分析的启发,我们提出了STAR,一种统一的时空融合框架用于SVOT。STAR包含四个关键组件:场景增强模块(SEM)、提取-相关-适应模块(ECAM)、时间解码模块(TDM)和惯性导航模块(INM)。SEM通过估计像素级和高阶曲线来调整SV场景的动态范围,生成增强的多模态表示。ECAM在预训练和目标领域之间对齐特征分布,促进特征提取、关系学习和领域适应。TDM通过端到端的历史对象状态推理整合历史对象状态,通过深度时间特征集成来优化空间特征。最后,INM利用物理时间特征来解决深度时间特征在异常干扰(如全遮挡(FOC)和DS)期间的局限性,确保连续的SVOT。
本工作的主要贡献如下。
STAR,一种统一的时空融合框架,利用提示学习模式,以最小的可调参数数量缓解数据稀缺问题。它不仅确保了SVOT的高效性和适应性,还为下游视觉任务奠定了坚实的基础。SEM和ECAM协同工作,优化空间特征处理。SEM调整SV场景的动态范围并生成增强的多模态表示。ECAM进一步优化特征。通过其本地和统一的相关建模层,以及自调制优化适配器(SMRA),ECAM能够实现全面的特征提取、关系学习和领域适应,有效捕捉不同SVOT上下文中的空间信息。对于时间分析,TDM整合历史对象状态进行端到端推理,通过深度时间特征集成实现多维特征表示。通过建模物理时间特征,INM利用一个意识选择器来评估置信度-不确定性,并利用惯性导航方案来管理如遮挡等异常干扰(见图2)。在流行的SVOT基准测试中进行了广泛的实验,即SatSOT、SV248S和OOTB。尽管基准测试中的成像场景、分辨率、卫星平台和对象类别各不相同,STAR在相同配置下始终优于近50种SOTA,证明了其有效性和泛化能力。其余部分的结构如下。第二节回顾相关工作,第三节介绍方法,第四节详细说明结果,第五节总结关键发现和未来研究方向。
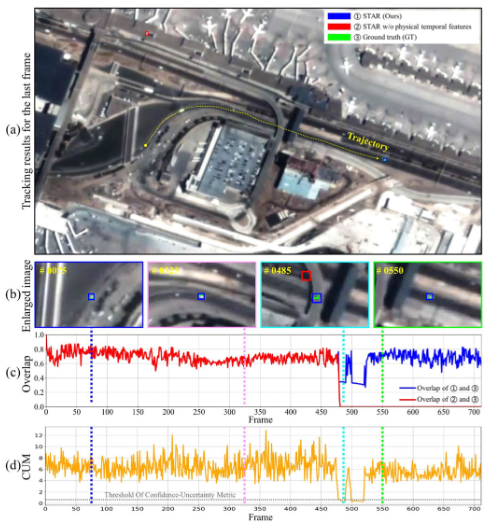
图2:时空融合跟踪性能分析
(a) 04_000004(SV248S)序列最后一帧的跟踪可视化
(b) 区域细节放大视图揭示深度时间特征的局限性
(c) 完全遮挡导致的时间连续性中断的跟踪重叠
(d) 监控过程中CUM的量化分析
II.相关工作
A. 普通视频(GV)目标跟踪
视觉跟踪方法一般分为两类:生成式方法和判别式方法。生成式方法通过建立目标模型并最小化损失函数来寻找匹配区域,其效果取决于目标表示(如高斯混合模型和基于核的方法),直接影响精度和速度。相比之下,判别式方法专注于区分目标与背景,核心范式包括相关滤波和孪生网络,因其简单和有效而受到重视。
基于相关滤波的跟踪器通常结合手工特征(如HOG、颜色名称、Gabor滤波器),通过自适应地最小化最小二乘损失来学习判别分类器。代表性方法包括 CFLB、BACF、SAMF、SRDCF、CSR-DCF、AutoTrack 和 GFS-DCF 等。
然而,手工特征往往不足以表示复杂场景。孪生网络方法则通过浅层卷积层获取精细的空间细节以实现精准定位,同时利用深层特征提供鲁棒的语义信息。它们采用双分支结构:一支用于模板(初始帧),另一支用于搜索图像(后续帧),共享网络以保证一致的特征提取。
SiamFC 是早期典型的孪生网络跟踪器,基于 AlexNet 微调,相比相关滤波方法表现更优。后续的 SA-Siam、DaSiamRPN、SINT 和 SiamRPN 也使用 AlexNet 作为特征提取器。但 AlexNet 过浅,限制了特征表达能力。于是更深的网络(如 ResNeXt、VGG、ResNet、GoogLeNet)被引入,并催生了更强的跟踪器(如 SiamRPN++、SiamDW 和 FEAR)。随着发展,跟踪器逐渐从 CNN-Transformer 混合(如 TransT、Stark、TrDiMP、E.T.Track)演化到双流两阶段全 Transformer(如 DualTFR、SwinTrack),再到单流单阶段全 Transformer(如 OSTrack、ARTrackV2、SBT、MixFormer、HiT),标志着 GV 跟踪的重要里程碑。
卫星视频跟踪(SVOT)的数据集(如 SatSOT、SV248S、OOTB)与无人机跟踪基准(如 UAV123、DTB70)有一些相似挑战,如小目标和复杂背景干扰。但 SVOT 还具有独特难题,如超低帧率、覆盖范围大、目标极小、时间连续性有限。因此,直接应用无人机领域的先进算法(如 AVTrack、SGLATrack、ORTrack)到卫星视频上往往效果欠佳,需大量适配。

图 3. STAR 跟踪器概览
整合了四个主要模块:
- SEM(场景增强模块) —— 用于生成多模态表示;
- ECAM(特征提取-关联-自适应模块) —— 用于实现特征提取、关系学习和域自适应;
- TDM(时间解码模块) —— 支持端到端的深度时间特征嵌入;
- INM(惯性导航模块) —— 用于缓解异常干扰。
要不要我帮您把这四个模块也画成一个 框架图(流程图),更直观展示 STAR 的整体架构?
B. 基于提示学习的多模态跟踪
近年来,基于提示(prompt)的自适应方法显著提升了多模态跟踪能力。比如:
- ProTrack 通过基础模型对齐来增强跨模态整合;
- ViPT 引入模态特定提示机制;
- BAT 使用双向特征对齐加强模态间对应;
- TATrack 融入时间感知提示;
- SDSTrack 展示了小样本情况下的鲁棒性;
- QueryNLT 通过视觉-语言协同训练实现更强判别力。
不过,大多数研究集中于普通视频的多模态跟踪(如 RGB-E、RGB-T、RGB-L、RGB-D),对卫星视频的探索较少。而卫星视频存在弱特征、全遮挡(FOC)、高相似干扰(DS)等特殊困难。为此,本文提出了一个统一的时空融合框架(STAR),以缩小这一差距。
C. 基于时空融合的跟踪
时间上下文利用在视觉跟踪中变得至关重要。已有研究尝试通过不同方式实现:
- TCTrack++ 开发了动态 CNN-Transformer 混合;
- STMTrack 引入了带记忆的区域注意力机制;
- Stark 通过选择性模板更新实现时空建模;
- SeqTrack 和 UpdateNet 通过模板优化提升跨帧匹配精度;
- JTBP 利用时间一致性做前景-背景区分;
- MixFormer 结合预测模块优化模板;
- TATrack 采用双流网络获取全面时空感知;
- MCTrack 将轨迹模式与历史帧结合以增强关系建模。
此外,ODTrack、AQATrack 和 EVPTrack 等方法通过基于 token 的时间传播,避免了显式的时间更新限制。以上进展为本文提出的 STAR 奠定了理论基础,同时也表明有效的时空融合对 SVOT 至关重要。
III.方法
A. 架构概览
STAR 包含四个主要组件(见图 3):
1.SEM(场景增强模块):优化卫星视频搜索图像
X
∈
R
H
z
×
W
z
×
3
X \in \mathbb{R}^{H_z \times W_z \times 3}
X∈RHz×Wz×3和模板
Z
∈
R
H
z
×
W
z
×
3
Z \in \mathbb{R}^{H_z \times W_z \times 3}
Z∈RHz×Wz×3的动态范围,生成增强后的表示(搜索图像:
X
ˉ
\bar{X}
Xˉ,模板:
Z
ˉ
\bar{Z}
Zˉ)。
2.ECAM(特征提取-关联-自适应模块):采用分层多模态 Transformer,结合局部关系建模和统一关系建模,同时实现特征提取、关系学习与域自适应。
3.TDM(时间解码模块):通过深度时间特征的整合来优化空间特征,实现端到端的历史状态推理。
4.INM(惯性导航模块):引入置信度感知的物理时间建模,利用置信度选择器和惯性导航方案来缓解异常干扰(如全遮挡和密集相似)。
这一时空融合框架增强了连续监测场景下的鲁棒性。
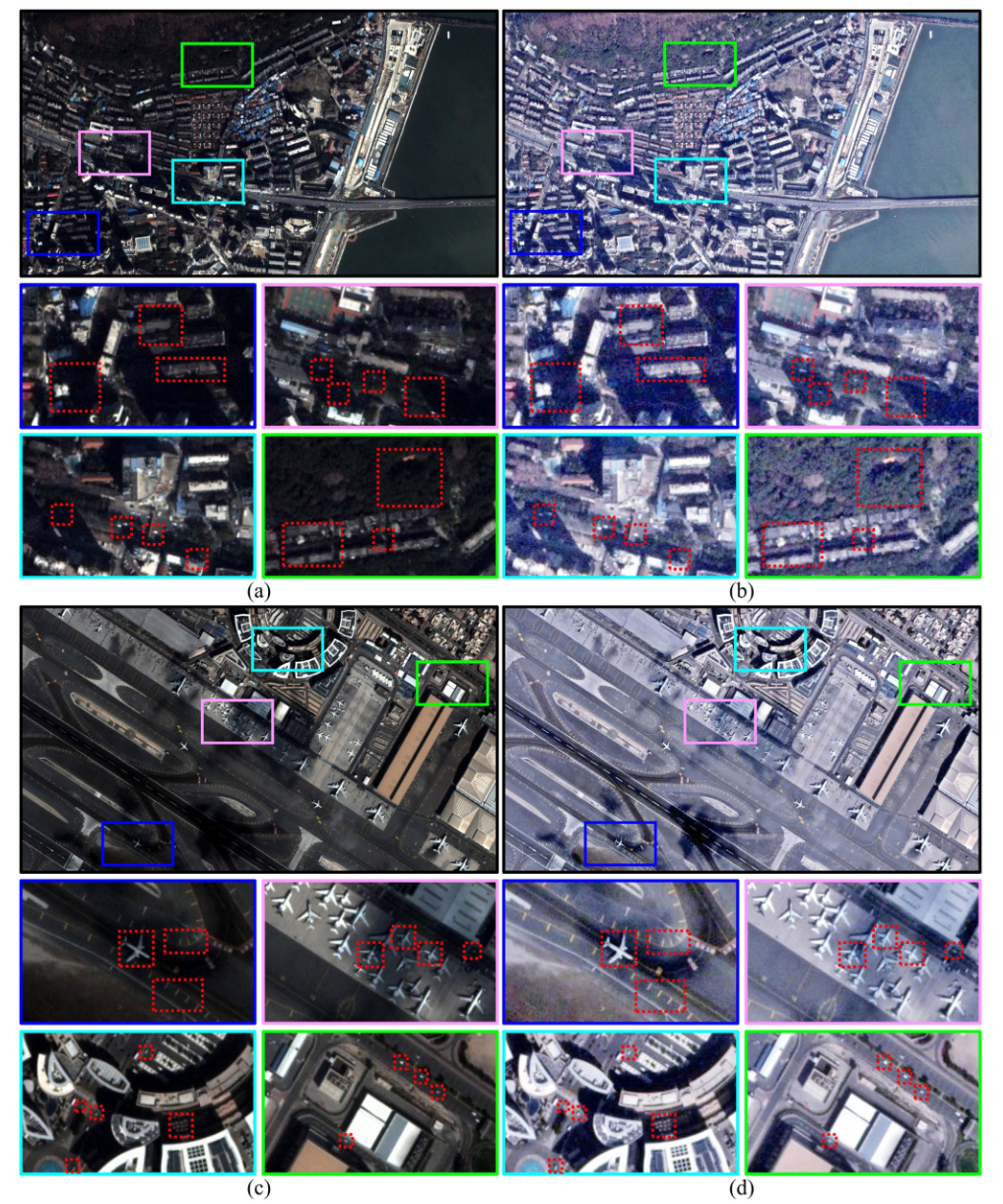
图 4. SES 处理前后效果对比
a 与 c 显示原始模态,b 与 d 显示经过 SES 处理后的结果。不同颜色的关键矩形区域被放大,并用红色虚线矩形标记,以展示增强后的目标和场景细节。
B. 场景增强结构(SES)
SVOT 在小目标、低对比度和复杂背景场景下具有较大挑战。这些目标常表现为特征模糊、易受干扰,而原始卫星视频模态低对比度和低分辨率的特点进一步限制了可判别特征。
以往研究(如 OOTB、SATDark)表明,场景增强能通过前景高亮和干扰抑制有效提升目标可见性,并保持实时处理能力。STAR 借鉴提示学习的思想,采用优化增强器实现卫星视频场景增强。
该轻量化网络通过自适应逐像素映射曲线实现:
E
(
x
)
=
E
n
−
1
(
x
)
+
ψ
(
x
)
E
n
−
1
(
x
)
(
1
−
E
n
−
1
(
x
)
)
E(x) = E^{n-1}(x) + \psi(x)E^{n-1}(x)\big(1 - E^{n-1}(x)\big)
E(x)=En−1(x)+ψ(x)En−1(x)(1−En−1(x))
其中,𝑥 表示像素坐标,迭代次数 n=3,𝜓为参数映射。
如图4实验表明,SES 显著提升了弱目标的可见性,同时保持结构完整性。增强后的多模态数据与原始模态一起输入后续模块,保证空间保真度的同时增强判别特征。
C. 特征提取-关联-自适应模块(ECAM)
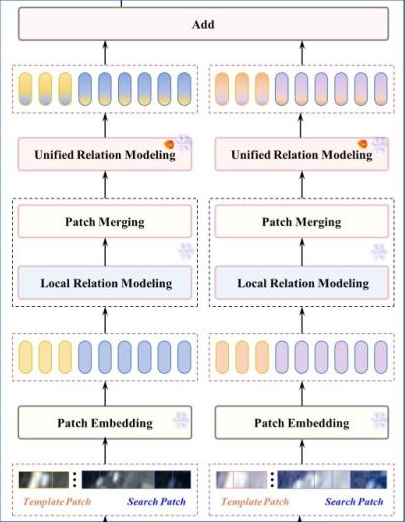
如图5所示,ECAM包含一个多模态层次Transformer架构,该架构针对浅层/深层处理阶段采用独立的层设计,集成本地关系建模和统一关系建模以及自调制精炼适配器(SMRA)。该架构实现了特征提取、关系学习和领域适应的同时进行。具体而言,初始阶段使用堆叠的本地关系建模层结合补丁合并,逐渐减少令牌数量同时扩展通道维度。值得注意的是,在此阶段,搜索图像和模板的处理保持分离。随后阶段实现统一关系建模,用于联合特征提取-相关-适应。ECAM通过嵌入SMRA的共享权重层,对增强模态(来自SES)和原始SV模态进行联合处理。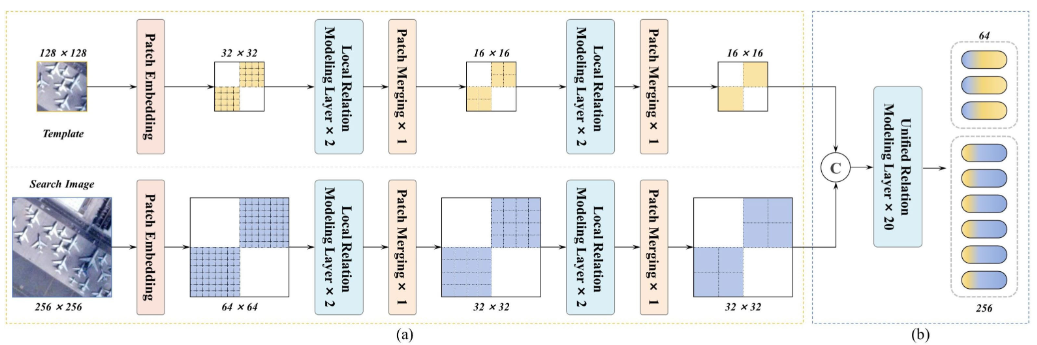
图5 ECAM 的结构配置
整合了两个基本结构:(a)局部关系建模和(b)统一关系建模。
- 局部关系建模(Local Relation Modeling):见图6a,在浅层阶段,,该结构用基于MLP的本地特征增强替换标准多头注意力。
F a t t = F ⊕ M L P ( L a y e r N o r m ( F ) ) , F ∈ F Z ˉ , F X ˉ F_{att} = F \oplus MLP(LayerNorm(F)), F \in {F_{\bar{Z}}, F_{\bar{X}}} Fatt=F⊕MLP(LayerNorm(F)),F∈FZˉ,FXˉ
F l o c a l = F a t t ⊕ M L P ( L a y e r N o r m ( F a t t ) ) F_{local} = F_{att} \oplus MLP(LayerNorm(F_{att})) \quad Flocal=Fatt⊕MLP(LayerNorm(Fatt))
其中 F Z ˉ F_{\bar{Z}} FZˉ和 F X ˉ F_{\bar{X}} FXˉ表示模板和搜索图像令牌(以增强模态为例),通过补丁嵌入、位置编码和重塑操作处理。 F l o c a l F_{local} Flocal是本地关系建模层的输出。通道维卷积补充浅层特征表达,为效率而阻塞跨图像建模。为了在保持特征层次的同时优化效率,浅层阶段配置了两个本地关系建模层,后接补丁合并操作。 - 统一关系建模(Unified Relation Modeling):统一建模层[见图6(b)]在单一架构中统一了图像内和图像间关系建模。该架构基于标准Transformer设计,集成了香草全局注意力机制和SMRA用于特征分布适应(见图6)。特别是,统一关系建模联合处理模板(
F
′
Z
ˉ
F'{\bar{Z}}
F′Zˉ)和本地关系建模后的搜索图像(
F
′
X
ˉ
F'{\bar{X}}
F′Xˉ。
F Z ˉ X ˉ = C A T ( F ′ Z ˉ , F ′ X ˉ ) ( 3 ) F_{\bar{Z}\bar{X}} = CAT(F'{\bar{Z}}, F'{\bar{X}}) \quad (3) FZˉXˉ=CAT(F′Zˉ,F′Xˉ)(3)
F Z ˉ X ˉ − a t t = F Z ˉ X ˉ ⊕ M H S A ( L a y e r N o r m ( F Z ˉ X ˉ ) ) F_{\bar{Z}\bar{X}-att} = F_{\bar{Z}\bar{X}} \oplus MHSA(LayerNorm(F_{\bar{Z}\bar{X}})) FZˉXˉ−att=FZˉXˉ⊕MHSA(LayerNorm(FZˉXˉ))
F Z ˉ X ˉ − o u t = F Z ˉ X ˉ − a t t ⊕ S M R A ( L a y e r N o r m ( F Z ˉ X ˉ − a t t ) ) F_{\bar{Z}\bar{X}-out} = F_{\bar{Z}\bar{X}-att} \oplus SMRA(LayerNorm(F_{\bar{Z}\bar{X}-att})) \quad FZˉXˉ−out=FZˉXˉ−att⊕SMRA(LayerNorm(FZˉXˉ−att))
其中 F Z ˉ X ˉ F_{\bar{Z}\bar{X}} FZˉXˉ和 F Z ˉ X ˉ − o u t F_{\bar{Z}\bar{X}-out} FZˉXˉ−out分别是统一关系建模层的输入和输出。SMRA(见图6)使用标准MLP结构处理输入令牌( F i n ∈ R N × C F_{in} \in \mathbb{R}^{N \times C} Fin∈RN×C),以估计局部细节,同时使用自调制结构探索非局部信息。MLP分支采用顺序线性变换和ReLU激活( δ \delta δ)来捕获局部模式
F m l p = L i n e a r ( δ ( L a y e r N o r m ( L i n e a r ( F i n ) ) ) ) F_{mlp} = Linear(\delta(LayerNorm(Linear(F_{in})))) \quad Fmlp=Linear(δ(LayerNorm(Linear(Fin))))
其中 F m l p F_{mlp} Fmlp表示捕获的局部细节。
同时,自调制分支通过深度卷积整合空间统计。我们计算重塑特征( R ( F i n ) R(F_{in}) R(Fin))的局部窗口方差( σ 2 \sigma^2 σ2)和自适应平均池化( p p p),随后通过以下方式结合它们
F s m = u ( δ ( D W C o n v ( σ 2 ( R ( F i n ) ) ⊕ p ( R ( F i n ) ) ) ) F_{sm} = u(\delta(DWConv(\sigma^2(R(F_{in})) \oplus p(R(F_{in})))) \quad Fsm=u(δ(DWConv(σ2(R(Fin))⊕p(R(Fin))))
其中 R R R表示重塑操作,DWConv表示深度1-D卷积。 F s m F_{sm} Fsm表示调制特征,通过以下方式促进有效的信息聚合
F m − o u t = R ( P W C o n v ( F i n ⊗ F s m ) ) F_{m-out} = R(PWConv(F_{in} \otimes F_{sm})) \quad Fm−out=R(PWConv(Fin⊗Fsm))
其中PWConv对应像素级卷积。最后,层次特征融合机制通过 ( F m l p ⊕ F m − o u t ) (F_{mlp} \oplus F_{m-out}) (Fmlp⊕Fm−out)结合局部精度和全局上下文,建立统一的特征关系框架。
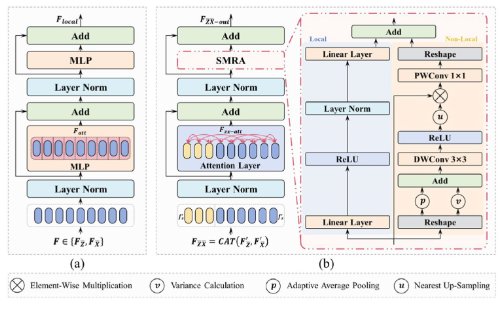
图6 (a) 局部关系建模层和 (b) 统一关系建模层的详细示意图,其中显示了 SMRA。
其中
F
Z
ˉ
X
ˉ
F_{\bar{Z}\bar{X}}
FZˉXˉ和
F
Z
ˉ
X
ˉ
−
o
u
t
F_{\bar{Z}\bar{X}-out}
FZˉXˉ−out分别是统一关系建模层的输入和输出。SMRA(见图6)使用标准MLP结构处理输入令牌(
F
i
n
∈
R
N
×
C
F_{in} \in \mathbb{R}^{N \times C}
Fin∈RN×C),以估计局部细节,同时使用自调制结构探索非局部信息。MLP分支采用顺序线性变换和ReLU激活(
δ
\delta
δ)来捕获局部模式
F
m
l
p
=
L
i
n
e
a
r
(
δ
(
L
a
y
e
r
N
o
r
m
(
L
i
n
e
a
r
(
F
i
n
)
)
)
)
F_{mlp} = Linear(\delta(LayerNorm(Linear(F_{in})))) \quad
Fmlp=Linear(δ(LayerNorm(Linear(Fin))))
其中
F
m
l
p
F_{mlp}
Fmlp表示捕获的局部细节。
同时,自调制分支通过深度卷积整合空间统计。我们计算重塑特征(
R
(
F
i
n
)
R(F_{in})
R(Fin))的局部窗口方差(
σ
2
\sigma^2
σ2)和自适应平均池化(
p
p
p),随后通过以下方式结合它们
F
s
m
=
u
(
δ
(
D
W
C
o
n
v
(
σ
2
(
R
(
F
i
n
)
)
⊕
p
(
R
(
F
i
n
)
)
)
)
F_{sm} = u(\delta(DWConv(\sigma^2(R(F_{in})) \oplus p(R(F_{in})))) \quad
Fsm=u(δ(DWConv(σ2(R(Fin))⊕p(R(Fin))))
其中
R
R
R表示重塑操作,DWConv表示深度1-D卷积。
F
s
m
F_{sm}
Fsm表示调制特征,通过以下方式促进有效的信息聚合
F
m
−
o
u
t
=
R
(
P
W
C
o
n
v
(
F
i
n
⊗
F
s
m
)
)
F_{m-out} = R(PWConv(F_{in} \otimes F_{sm})) \quad
Fm−out=R(PWConv(Fin⊗Fsm))
其中PWConv对应像素级卷积。最后,层次特征融合机制通过
(
F
m
l
p
⊕
F
m
−
o
u
t
)
(F_{mlp} \oplus F_{m-out})
(Fmlp⊕Fm−out)结合局部精度和全局上下文,建立统一的特征关系框架。
D. 时序解码模块(TDM)
仅进行空间分析不足以解决持续跟踪挑战,如动态运动模式。因此,STAR引入TDM(见图3),通过注意力传播整合深度时序特征。TDM包含一个时序解码层,用于从序列数据中提炼时序模式,以及一个时空融合层,用于结合空间-时序特征。TDM监控对象状态演化和运动模式转换,已处理的token随后被导向预测网络进行定位。
E. 惯性导航模块(INM)
虽然TDM可以处理部分遮挡(POC)场景,但其在FOC期间的有效性会减弱。为此,我们设计了INM,利用视觉和运动信息来增强鲁棒性。它建模物理时序特征,包括一个意识选择器来评估跟踪置信-不确定性,以及一个惯性导航方案来管理异常干扰。对于每一帧,首先利用视觉和深度时序特征来定位对象,随后通过整合物理时序特征来精炼位置,当视觉线索不足时。
1) 意识选择器(Awareness Selector)
我们提出了一种意识选择器,用于动态评估跟踪的置信度-不确定性,以感知异常干扰。置信度-不确定性可以从响应图(response map)的特征中推断出来。精确匹配通常会产生一个明显的峰值,且周围波动较小;而不准确的检测则会产生不稳定的模式(见图 7)[22, 23]。基于这一观察,我们引入了基于峰值强度和峰旁瓣比(peak-to-sidelobe ratio)的置信度-不确定性度量(CUM)[6]。意识选择器根据响应图计算 CUM:
C
U
M
(
R
M
)
=
(
M
a
x
(
R
M
)
−
A
v
g
(
R
M
)
)
∗
M
a
x
(
R
M
)
/
S
t
d
(
R
M
)
CUM(RM) = (Max(RM)-Avg(RM))*Max(RM)/Std(RM)
CUM(RM)=(Max(RM)−Avg(RM))∗Max(RM)/Std(RM)
其中,Max、Avg 和 Std 分别表示响应图 RM 的最大值、平均值和标准差。
对于当前帧
t
t
t,令
CUM
t
avg
(
RM
)
\text{CUM}_{t}^{\text{avg}}(\text{RM})
CUMtavg(RM) 表示最近
k
k
k 个可靠帧的平均 CUM。使用 CUM 阈值
τ
\tau
τ 来判断是否激活惯性导航方案,条件为:
C
U
M
t
(
R
M
)
/
C
U
M
t
a
v
g
(
R
M
)
<
τ
CUM_t(RM)/CUM^{avg}_{t}(RM)<τ
CUMt(RM)/CUMtavg(RM)<τ
图 7 展示了在卫星视频目标跟踪过程中 CUM 的变化,说明了其在识别干扰和维持准确目标轨迹方面的作用。
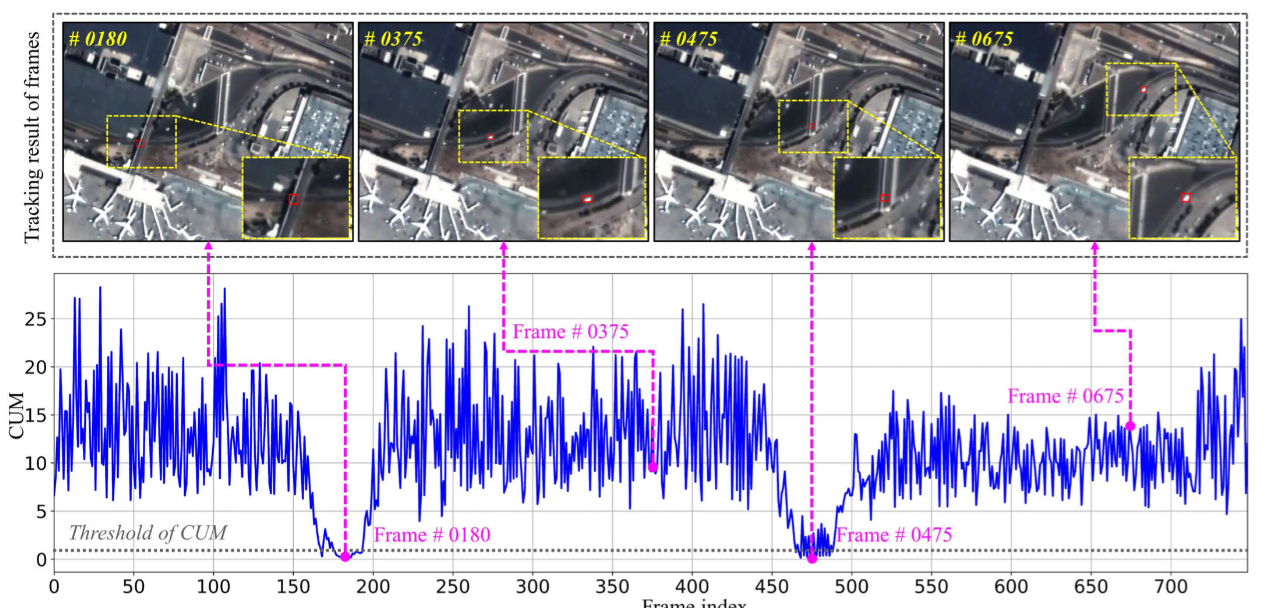
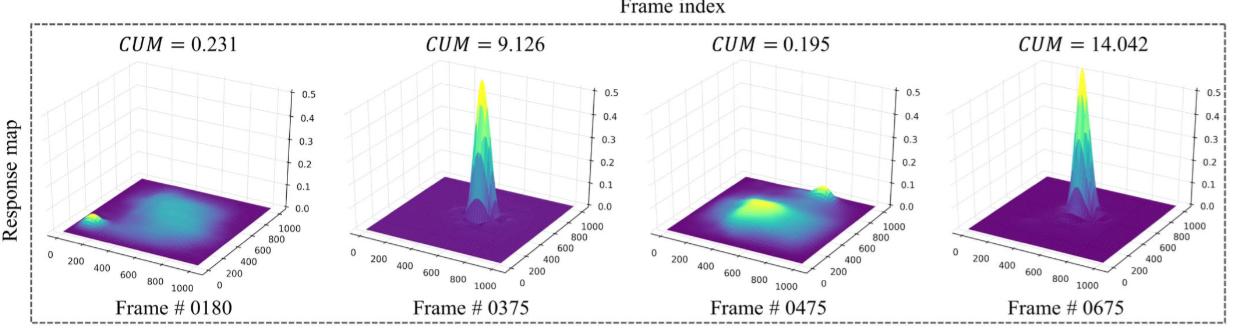
图7 通过car_01(SatSOT)序列进行的CUM分析。显著的CUM减少表明惯性导航方案的激活。追踪结果显示在顶部,并且放大了黄色边界区域的视图。中间部分展示了CUM,以灰色虚线标记的阈值τ。相应的响应图在底部可视化。观察表明在帧#0180和#0475处存在空间特征不稳定,这归因于完全遮挡。在这种情况下,响应图展示了扁平的多峰分布,导致CUM值降低。因此,通过CUM评估可以识别出异常干扰。
2) 惯性导航方案(Inertial Navigation Scheme)
当满足公式 (9) 的条件时,惯性导航方案将被激活。在卫星视频中,由于鸟瞰视角,目标通常表现出平滑的运动轨迹 [24, 6]。高阶模型或自适应滤波器(如粒子滤波器)理论上可以捕捉更复杂的运动,但可能会引入额外的计算开销,从而限制在卫星视频中的实时应用。因此,我们使用非线性回归来建模运动模式并预测目标位置 [22]。设
(
t
i
,
φ
i
)
,
i
=
1
,
2
,
3
,
…
,
p
(t_i, \varphi_i), i = 1, 2, 3, \ldots, p
(ti,φi),i=1,2,3,…,p 表示目标在
p
p
p 帧中的
x
x
x 轴坐标。使用二次函数对平滑轨迹进行建模:
$ \varphi_i = \beta_0 + \beta_1 t_i + \beta_2 t_i^2 $
其中, β 0 \beta_0 β0、 β 1 \beta_1 β1 和 β 2 \beta_2 β2 通过最小二乘法确定:
$ \min \sum_{i=1}^{p} \left( \beta_0 + \beta_1 t_i + \beta_2 t_i^2 - \varphi_i \right)^2 $
求解 [ β 0 , β 1 , β 2 ] T [\beta_0, \beta_1, \beta_2]^{\text{T}} [β0,β1,β2]T 即可得到轨迹方程。 y y y 轴坐标的计算方式类似,从而得到最终位置。值得注意的是,在使用惯性导航方案时,CUM 保持不变,因为无法获得实际测量值。相反,CUM 可以被更新,从而提高卫星视频目标跟踪的准确性。
F. 头部网络与损失函数 (Head and Loss)
STAR 通过将搜索区域令牌(search region tokens)转换为一个二维空间表示来供头部网络(head network)处理。该头部网络包含:一个用于初始目标定位的分类分支(classification branch)、一个用于精确中心调整的局部偏移分支(local offset branch)、以及一个用于预测边界框大小的尺寸估计分支(size estimation branch)。
共有三个输出:
一个指示目标存在概率的概率图(probability map),
一个用于中心校正的偏移图(offset map),
一个用于确定大小的尺度图(scale map)。
这些输出通过一个多任务学习框架进行优化,其中概率图提供粗略定位,而偏移图和尺度图则提高定位精度。优化过程使用 Focal Loss ( L cls L_{\text{cls}} Lcls) 用于分类任务 [110],并结合 L1 Loss ( L 1 L_{1} L1) 和 广义IoU Loss ( L giou L_{\text{giou}} Lgiou) 用于回归任务 [111]。复合损失函数 ( L total L_{\text{total}} Ltotal) 整合了这些组件用于模型训练:
L total = L cls + φ L 1 L 1 + φ giou L giou L_{\text{total}} = L_{\text{cls}} + \varphi_{L_{1}} L_{1} + \varphi_{\text{giou}} L_{\text{giou}} Ltotal=Lcls+φL1L1+φgiouLgiou
其中, φ L 1 \varphi_{L_{1}} φL1 和 φ giou \varphi_{\text{giou}} φgiou 是正则化系数,其值分别设定为 5.0 和 2.0。
IV.实验与讨论
A. 实验设置
1)实施细节:STAR 使用 PyTorch 实现,并在配备 NVIDIA RTX 4090 GPU(24 GB 内存)的工作站上进行评估。该框架采用 AdamW 优化器,其设置如下:权重衰减为 0.0001,批量大小为 64,初始学习率为 0.001,并通过余弦退火策略进行衰减。训练在包含 90 个 epoch 的 LaSOT 、GOT-10k 和 TrackingNet 数据集上进行。骨干网络采用 HiViT-Base ,输入模板和搜索区域大小分别调整为 128×128和 256×256像素。训练期间应用了数据增强技术,包括旋转、颜色抖动和运动模糊。所有比较方法均使用其官方实现和推荐参数在相同硬件和软件环境下进行测试,以确保公平性。
2)评估基准:STAR 在三个主流卫星视频基准上进行了全面评估:SatSOT 、SV248S 和 OOTB 。这些基准在成像场景、空间分辨率、卫星平台和对象类别方面存在显著差异。SatSOT 主要包含地面对象(例如汽车、火车),SV248S 包含地面和海上对象(例如汽车、船只),而 OOTB 则包含地面、海上和空中对象(例如汽车、船只、飞机)。这种多样性有助于验证 STAR 的泛化能力。评估遵循标准的单对象跟踪协议,其中初始帧提供真实边界框,跟踪器需要在后续帧中预测对象状态。
3)评估标准:跟踪性能通过一次性评估(one-pass evaluation)使用精确度图(precision plot)和成功率图(success plot)进行量化。精确度图量化了中心位置误差低于指定像素阈值(1–50)的帧比例。相反,成功率图计算了重叠分数超过预定义阈值(0–1)的时间段。算法排名遵循两个标准:5 像素精确度指标(precision rate, PR)和成功率曲线下面积(area under the curve, AUC, success rate, SR)。特别是,OOTB 采用了官方验证协议,结合了 PR、归一化精确度(normalized PR, NPR)和 SR 进行综合分析。推理速度以 FPS(每秒帧数)报告。更高的 PR、NPR、SR 和 FPS 表明更优的跟踪能力。
B. SatSOT 上的性能比较
1)SatSOT 概述:SatSOT 包含 105 个测试场景,共 27664 帧,为 SVOT 提供了帧级水平边界框(HBB)标注。它将主要对象分为四类:65 辆汽车、26 列火车、9 架飞机和 5 艘船只,反映了多样的空间尺度和显著挑战。卫星视频(SV)片段时长可变,平均 263 帧(范围:120–750 帧)。它源自三个商业卫星平台(Skybox、Jilin-1 和 Carbonite-2),并包含 11 个不同属性用于系统评估跟踪器:光照变化(IV)、背景干扰(BC)、背景抖动(BJT)、形变(DEF)、部分遮挡(POC)、完全遮挡(FOC)、旋转(ROT)、相似物体(SOB)、低质量(LQ)、纵横比变化(ARC)和微小物体(TO)。
2)与 GV 跟踪器的比较分析:所提出的方法与最先进的(SOTA)GV 方法进行了比较评估。如表 I 和图 8 所示,STAR 在 PR 和 SR 方面均取得了最佳性能。值得注意的是,基于相关滤波器的跟踪器(如 Staple 和 BACF)利用手工特征,在 SVOT 中表现出竞争力。然而,这些方法在表示复杂场景时存在局限性。基于 Siamese 网络的方法(如 SiamRPN++ 和 SiamCAR)利用深度外观特征,实现了更高的判别能力。最近的基于 Transformer 的跟踪器(如 Stark 和 OSTrack)在 GV 跟踪方面显示出显著进步。然而,由于 GV 和 SV 场景之间的显著差异,它们在 SVOT 基准测试中的性能下降,凸显了领域适应性挑战。STAR 通过其统一架构解决了这些问题,在 PR 和 SR 方面分别比第二名(SiamCAR)高出 1.5% 和 6.0%。
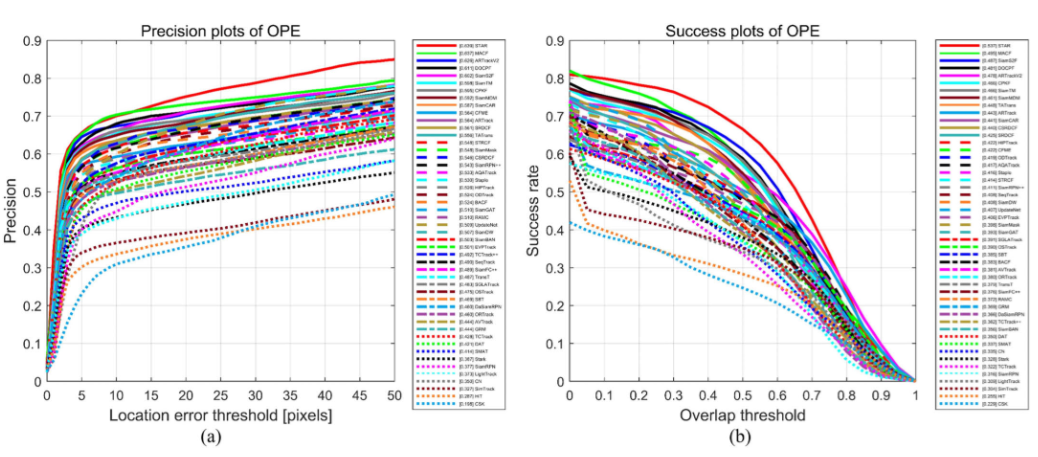
图8 与GV和SV跟踪器在SatSOT上的性能比较。(a) 精度图。(b) 成功图。
3)与 SV 跟踪器的比较分析:表 III 和图 8 总结了主流 SVOT 方法的性能指标。STAR 在 PR 和 SR 方面均排名第一,分别达到 0.639 和 0.537。与专门为 SV 场景设计的 SOTA 跟踪器相比,STAR 显示出持续改进。具体来说,它比 SiamS2F、SiamTM 和 SiamMDM 在 PR 上分别高出 3.7%、4.1% 和 4.7%,在 SR 上分别高出 5.0%、7.1% 和 7.6%。这些比较突显了 STAR 在处理 SV 挑战方面的有效性。
4)属性性能分析:图 9 展示了 SatSOT 上 11 种不同属性的属性性能分析。STAR 在 7 种属性(BC、SOB、POC、FOC、ROT、ARC、TO)中排名第一,在其余 4 种属性(IV、BJT、DEF、LQ)中排名前三。这些结果证明了 STAR 在应对 SV 跟踪中普遍存在的各种挑战方面的鲁棒性。
C. SV248S 上的性能比较
1)SV248S 概述:SV248S 包含来自 248 个序列的 48181 帧,这些序列跨越四个国家(美国、巴林、利比亚和土耳其)和五个城市地区(旧金山、明尼阿波利斯、穆哈拉格、德尔纳和阿达纳)。定义了四个主要对象类别:车辆、大型车辆(L-vehicle)、飞机和船只。十个 SV 特定属性被系统分类:自然干扰(ND)、短期遮挡(STO)、长期遮挡(LTO)、尺寸变化(DS)、背景变化(BCH)、光照变化(IV)、慢速运动(SM)、连续遮挡(CO)、背景聚集(BCL)和面内旋转(IPR)。每个序列被分为三个难度级别:简单、正常和困难。为了标准化评估,所有对象都用多边形掩码进行标注,并转换为 HBB 表示。
2)与 GV 跟踪器的比较分析:所提出的方法与 SOTA GV 方法进行了评估。如表 II 和图 10 所示,STAR 获得了 PR/SR 分数 0.774/0.523,确保了顶级位置。Staple 跟踪器依赖相关滤波器并结合各种手工特征,在比较方法中实现了竞争性能。然而,一方面,传统的手工特征和相关滤波器可能会限制跟踪性能。相比之下,深度外观特征,常用于 SVOT 方法,包含一个浅层,编码具有高空间分辨率的低级信息以进行精确定位,以及一个深层,捕获对某些对象变化不变的高级语义信息。我们的方法另一方面,设计了一个带有 SMRA 的多模态 Transformer 架构,以促进特征提取、关系学习和领域适应,实现了有竞争力的结果。它在 PR/SR 上比 Staple 分别提高了 2.4%/4.2%,验证了显著的结果。

图10 与GV和SV跟踪器在SV248S 上的性能比较。(a) 精度图。(b) 成功图。
3)与 SV 跟踪器的比较分析:主流 SVOT 方法的性能指标列于表 III 和图 10。最近的方法,如 SiamS2F,通过特征细化设计了一个连体的光谱-空间-帧相关网络。然而,由于缺乏运动模拟和干扰感知能力,它难以预测对象的位置。相比之下,所提出的方法结合了深度和物理时间特征,以实现连续轨迹建模并处理像 DS 和 LTO 这样的异常,从而产生卓越的性能。STAR 在 PR 上分别超过了 SiamS2F、SiamTM、SVLPNet 和 SiamMDM 1.7%、2.8%、8.6% 和 6.3%,在 SR 上分别超过了 1.7%、3.6%、5.2% 和 7.0%。这些比较突显了 STAR 在 SV 跟踪中的有效性。
4)类别性能分析:表 IV 展示了 SV248S 上不同对象类别的性能分析。STAR 在飞机和船只类别中表现出色,分别取得了最高的 PR/SR 分数 0.943/0.728 和 0.992/0.632。这可以归因于这些对象通常具有更大的尺寸和更简单的运动模式,使得跟踪更加简单。在这种情况下,所提出的方法也产生了有竞争力的结果,PR 和 SR 分别为 0.864 和 0.765。相反,大多数跟踪器在车辆类别中表现出次优性能,强调需要增强的小物体跟踪解决方案。STAR 在这个具有挑战性的类别中取得了领先的 PR/SR 分数 0.751/0.490,强调了其在基于 SV 的小物体应用中的鲁棒性。
5)难度性能分析:表 IV 展示了 SV248S 上各种方法跨跟踪难度的性能分析。关于精确度指标,STAR 表现出卓越的性能,在三个难度类别中的两个(正常和困难)中排名第一,同时在简单类别中保持竞争地位,最终确保获得 OVE 首要位置。在 SR 评估中,STAR 在所有难度级别中始终排名前三。
6)属性性能分析:如表 V 详细所示,STAR 在 SV248S 基准测试的所有十个属性中均排名前三,实现了最高的 OVE 性能。其模块化架构能够稳健处理复杂的 SVOT 场景,为跟踪应用建立了基准。
D. OOTB 上的性能比较
1)OOTB 概述:OOTB 包含来自 110 个 SV 序列的 29890 帧,涵盖四个对象类别:汽车、船只、火车和飞机。每个序列都用定向边界框(oriented bounding boxes)进行标注,并标记了 12 个属性:形变(DEF)、面内旋转(IPR)、部分遮挡(POC)、完全遮挡(FOC)、光照变化(IV)、运动模糊(MB)、背景干扰(BC)、超出常规(OON)、外观相似(SA)、纹理稀少(LT)、各向同性运动(IM)和各向异性运动(AM)。该基准 (https://github.com/YZCU/OOTB) 采用了严格的评估协议以确保公平性和全面性。
2)与 GV 和 SV 跟踪器的比较分析:STAR 与 SOTA GV 和 SV 跟踪器进行了评估。表 VI 和图 11 总结了结果。STAR 以 PR/NPR/SR 分数 0.846/0.826/0.678 超越了 SOTA 跟踪器,展现出卓越的鲁棒性。
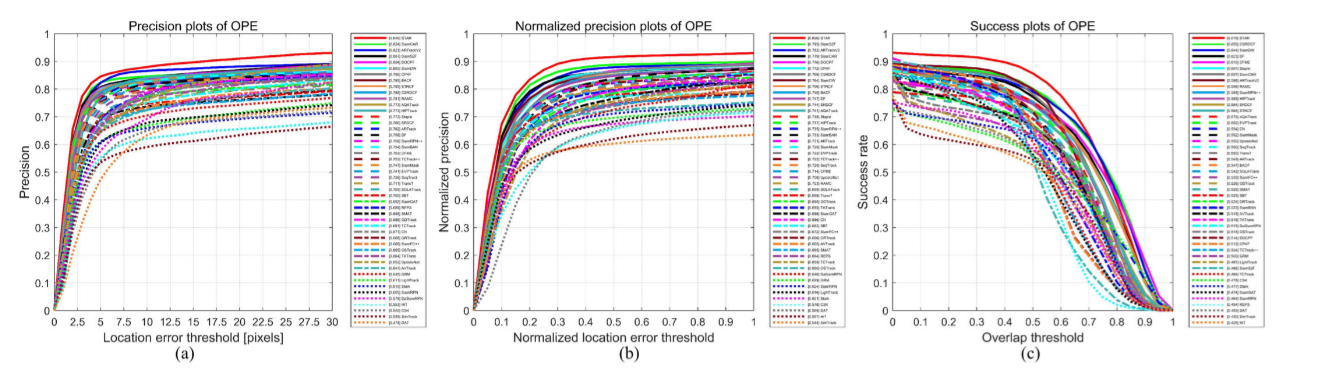
图11 与GV和SV跟踪器在OOTB 上的性能比较。(a) 精度图。(b) 标准化精度图。©精度图。
3)类别性能分析:分析了 OOTB 的四个对象类别。表 VII 和 VIII 总结了主要的 NPR 和 SR 结果。STAR 在三个类别(汽车、船只和火车)中获得了领先的 NPR 位置,并在所有四个对象类别的 SR 中排名前二。
4)属性性能分析:跨各个属性系统地评估了跟踪鲁棒性。如表 VII 和 VIII 所记录,STAR 在所有 12 个属性的 NPR 和 SR 指标中均确保了前三的位置。
E. 可视化展示
1)定性分析:图 12 展示了在具有挑战性的场景下多个跟踪器的定性比较。像 Staple、SBT、AQATrack、HIPTrack 和 CFME 这样的跟踪器在旋转和完全遮挡场景下表现出早期的跟踪漂移,如在 car_01 (SatSOT) 中所证明的那样。相比之下,提出的 STAR 可以在整个序列中保持连续的轨迹。当处理极低分辨率的对象(例如 SV248S 中的 05_000035)时,STAR 表现出卓越的判别能力,即使在存在显著背景干扰的情况下也能保持稳定的跟踪。此外,在 OOTB 的 ship_10 序列中,STAR 有效地处理了剧烈的尺度变化和面内旋转,而其他跟踪器则失败或漂移。这些可视化结果验证了 STAR 在复杂 SV 场景中的有效性和鲁棒性。


图12 视觉分析,从上到下排列:car_01 (SatSOT),car_61 (SatSOT),03_000036 (SV248S),04_000003 (SV248S),05_000035 (SV248S),ship_10 (OOTB),以及 train_1 (OOTB)。
2)失败案例分析:尽管 STAR 具有整体鲁棒性,但在某些极端条件下仍面临挑战。图 15 展示了失败案例。在 train_25 (SatSOT) 序列中,对象经历了完全遮挡、剧烈的光照变化和外观变化。STAR 在长时间遮挡后失去了对对象的跟踪。在 04_000018 (SV248S) 序列中,对象被建筑物严重且长时间遮挡,导致跟踪失败。这些观察结果强调了未来研究需要增强对长期遮挡和剧烈外观变化的处理能力。

图15 失败案例可视化,从上到下排列:train_25 (SatSOT), 04_000018 (SV248S), and 05_000008 (SV248S)。
F. 消融实验
进行了广泛的消融实验,以分析 STAR 中各个组件的贡献。结果总结在表 IX、X 和 XI 中。
1)整体消融研究:表 IX 展示了 STAR 及其变体在 SatSOT 和 SV248S 上的性能。Model-1 代表仅使用原始 SV 模态的基线 HiViT 跟踪器。添加 SEM (Model-2) 在 PR 和 SR 上带来了一致的改进,验证了场景增强的有效性。引入 ECAM (Model-3) 进一步提高了性能,展示了其强大的特征提取和关系建模能力。结合 INM (STAR) 带来了最显著的性能提升,特别是在 SR 上,突出了物理时间特征在管理异常干扰方面的重要性。
2)ECAM 消融研究:表 X 调查了在 ECAM 的不同深度插入 SMRA 层的影响。结果表明,在所有层中插入 SMRA (Model-9, Model-10) 会导致性能下降,表明潜在过拟合。选择性地在特定层(例如 [5, 10, 15])插入 SMRA 可获得最佳结果 (STAR)。
3)SEM 消融研究:SEM 通过估计像素级和高阶曲线来调整 SV 场景的动态范围,生成增强的多模态表示。如表 IX 所示,比较 Model-1 和 Model-2 显示,添加 SEM 在 OVE PR 和 SR 上分别带来了 4.6% 和 4.7% 的改进。同样,比较 Model-3 和 Model-4 揭示了 0.8% 和 3.7% 的改进。这些结果验证了 SEM 在优化 SV 场景方面的有效性。
4)TDM 消融研究:表 XI 中的消融实验评估了 TDM 的贡献。Model-11 从我们的 STAR 中排除了 TDM,证明了该模块的重要性。通过深度时间提示,STAR 在 OVE PR 和 SR 上分别实现了 0.8% 和 0.4% 的改进。图 14 提供了重叠曲线和跟踪样本,验证了所提出方法的时空融合的有效性。

图14 重叠曲线和STAR在各种场景中的跟踪样本:(a) car_12 (SatSOT),(b) train_20 (SatSOT),© 01_000029 (SV248S),(d) 03_000008 (SV248S),(e) 05_000013 (SV248S),(f) car_21 (OOTB),(g) ship_14 (OOTB),和(h) plane_4 (OOTB)。预测结果用红色边框表示,实际标注用蓝色显示。这一全面的分析验证了STAR的适应性。
5)INM 消融研究:INM 对物理时间特征进行建模,包括一个感知选择器来评估跟踪置信度-不确定性,以及一个惯性导航方案来管理异常干扰。如表 IX 所示,Model-2 和 Model-4 之间的比较揭示了由于包含 INM 而带来的 4.8% 和 2.6% 的 OVE PR 和 SR 增强。类似地,从 STAR 中移除 INM 会导致 PR 和 SR 分别降低 7.1% 和 4.4%,如 Model-3 和 STAR 之间的比较所示。一致的趋势在其他模型对中也很明显(Model-5 和 Model-7,Model-6 和 Model-8,以及 Model-9 和 Model-10),如表 X 详细所示,进一步证实了 INM 的有效性。
6)CUM 阈值敏感性分析:我们探讨了 CUM 阈值 (τ) 的敏感性。表 XII 展示了 τ从 0 到 1.0 范围的详尽实验,其中值颜色从蓝色(低)编码到红色(高)。结果表明,性能随着 τ的增加先提高后下降,在 τ=0.40处观察到最佳结果。
G. 局限性与讨论
尽管 STAR 具有整体(OVE)鲁棒性,但在复杂场景中仍遇到挑战。如图 15 所示,在 train-25 (SatSOT) 序列中,火车具有较小的纵横比。当受到遮挡、相似干扰和极端光照变化(IV)时,所提出的方法会出现跟踪漂移。具体来说,在严重和长时间的完全遮挡场景中,该方法可能会丢失对小物体的跟踪,如 05_000008 (SV248S) 序列所示。这里,一个小物体被桥梁长时间严重遮挡并改变其轨迹,导致时间跟踪失败。上述案例突显了处理长期遮挡(LTO)和突然运动的局限性。此外,SV 对象通常表现出复杂的运动模式,例如加速和突然转向。二次回归对于建模此类动态可能不足。为了提高轨迹连续性,未来的工作应探索更高阶的运动模型和自适应滤波技术(例如,粒子滤波器)。集成物理信息神经网络也可能实现端到端的运动模式学习,增强跨多样化场景的泛化能力。
V. 结论
本研究提出 STAR,一个用于卫星视频目标跟踪(SVOT)的统一时空融合框架。通过引入场景增强模块(SEM),STAR 优化卫星视频(SV)场景,生成增强的多模态表示。它还设计了提取-关联-自适应模块(ECAM),该模块包含具有局部和统一关系建模的多模态分层 Transformer 架构,共同实现特征提取、关系学习和领域自适应。时间解码模块(TDM)整合历史对象状态,通过注意力传播增强具有深度时间特征的空间特征。此外,惯性导航模块(INM)对物理时间特征进行建模,包括一个评估跟踪置信度-不确定性的感知选择器,以及一个管理异常干扰(例如完全遮挡(FOC)和尺寸变化(DS))并确保连续轨迹的惯性导航方案。受提示学习模式启发,STAR 引入最少数量的可调参数,却在各种 SVOT 基准上实现了具有竞争力的性能。
主要的贡献总结如下:
- STAR 作为一个统一时空融合框架,利用提示学习模式以最少的可调参数缓解数据稀缺性。它不仅确保了 SVOT 中的高效率和适应性,还为下游视觉任务奠定了坚实基础。
- SEM 和 ECAM 协同优化空间特征处理。SEM 调整 SV 场景的动态范围并生成增强的多模态表示。ECAM 进一步细化特征。凭借其局部和统一关联建模层以及自调制细化适配器(SMRA),ECAM 实现了全面的特征提取、关系学习和领域自适应,有效捕获了不同 SVOT 上下文中的空间信息。
- TDM 通过注意力传播整合深度时间特征以增强空间特征,实现端到端的历史状态推理。
- 通过建模物理时间特征,INM 利用感知选择器评估置信度-不确定性,并利用惯性导航方案管理异常干扰(参见图 2)。
- 在流行的 SVOT 基准(即 SatSOT 、SV248S 和 OOTB )上进行了广泛的实验。尽管各基准在成像场景、分辨率、卫星平台和对象类别上存在差异,STAR 在相同配置下始终优于近 50 个 SOTA 方法,证明了其有效性和泛化能力。
实验证明,STAR 在多个 SVOT 基准上优于 SOTA 方法,为卫星视频分析提供了一个稳健的解决方案。值得注意的是,在处理小物体和长期遮挡等极端情况时仍存在挑战。未来的研究将探索更高阶的运动模型和自适应滤波技术(例如粒子滤波器)以提高轨迹连续性。集成物理信息神经网络可能实现运动模式的端到端学习,增强跨多样化场景的泛化能力。
属于我自己的理解与思考
Q1. 论文的内容摘要:
论文领域为计算机视觉,卫星视频物体跟踪。提出了一种名为STAR的统一时空融合框架,旨在解决:数据稀缺、模态限制、范式差距以及多维特征利用不足等问题。
框架引入了:场景增强模块(SEM)、ECAM提取-相关-适应模块(ECAM)、时序解码模块(TDM)、惯性导航模块(INM)。STAR优化了卫星视频场景,生成增强的多模态表示,并结合多模态分层Transformer架构进行特征提取、关系学习和域适应。同时,它整合了深度时序特征和物理时序特征,以处理异常干扰(如全遮挡和密集相似性),并通过提示学习模式引入少量可调参数,在各种SVOT基准测试中实现竞争性性能。
1.这是新问题还是旧问题?
卫星图像追踪算在追踪领域内,属于一个长期课题了,但是作者指出:现有方法多数继承自通用视频/无人机追踪范式,在卫星场景下存在“范式差(paradigm gap)”与时空特征利用不充分等缺陷,因此 STAR 作为“统一的时空融合框架”在思想上是对已有问题的一种新整合/改进(不是提出一个全新任务,而是提出一个更系统、更专门针对 SVOT 的解决方案)。
2.如果是旧问题,该方法如何更好?
与现有方法相比,STAR通过统一时空融合框架解决了数据稀缺(使用提示学习减少参数调整)、模态限制(生成增强多模态表示而非丢弃原始模态)、范式差距(采用全Transformer架构避免CNN的局部限制)和多维特征利用不足(整合深度和物理时序特征处理异常干扰)。它在基准测试(如SatSOT、SV248S和OOTB)上超越了近50个SOTA方法,实现了更高的精度和鲁棒性,同时保持高效(少量参数调整,避免过拟合)。
Q2. 作者的主要贡献与新颖点是什么?
核心贡献(逐条):
- 提出 STAR 框架(SEM、ECAM、TDM、INM)——把空间增强、多模态特征对齐、深时序推理和物理运动建模统一在一个管线里。
- 在空间端:用 SEM 等轻量曲线增强方法生成“增强模态”,配合 ECAM 的多尺度 Transformer + 自调制微调器(SMRA)同时做特征提取、关系建模与域适配(缓解模态受限与数据稀缺)。
- 在时间端:TDM 提出“深时序 prompts / temporal decoding”把历史目标状态内嵌到端到端推理中;INM 则引入物理时序建模(CUM 置信选择 + 二次轨迹回归)以应对完全遮挡 / 离散异常。
- 工程/范式层面:以 prompt-learning 思路只调少量参数(可迁移/少数据适配),并在多个 SVOT 基准上取得领先(并对各模块做了详尽消融)。
这些点的新颖性主要在“把深时序(Transformer)与物理时序(惯性/回归)系统性结合,并在多模态提示/自适配上做了轻量设计”,这比单纯只做外观更新或只做简单运动预测更全面。
Q3. 作者为什么提出这个方法?
动机:数据稀缺、原始模态(卫星影像)本身弱(低分辨、低对比、目标很小)、现有追踪范式(Siamese、CF 等)和 GV(generic video)方法直接迁移效果差、深时序特征未被充分利用等。作者认为需要同时改进空间表示、跨模态对齐与时序建模。
现有方法如何解决这些问题?有什么不足?
传统 SVOT 常用物理运动滤波(卡尔曼、指数平滑、轨迹平均)来处理运动,但对复杂遮挡和深度语义变化能力不足。
基于Transformer的方法在GV上效果很好,但直接应用到卫星图像往往忽视物理运动/置信度判断,且需大量数据/手动更新策略,在SVOT上泛化不足。
结论:现有方法各有偏重,缺乏一个把空间增强、多模态对齐、深度时序推理、物理轨迹恢复结合的统一方案。
Q4. 方法的整体框架是什么?
从输入输出来看:
输入:原始template
Z
∈
R
H
z
∗
W
z
∗
3
Z ∈ R^{H_z*W_z*3}
Z∈RHz∗Wz∗3 和 search image
X
∈
R
H
z
∗
W
z
∗
3
X ∈ R^{H_z*W_z*3}
X∈RHz∗Wz∗3 (论文训练时使用template128X128,search256X256)。
输出:bounding box(通过head的分类概率图、offset map与scale map 综合得到),以及轨迹/置信度(用于INM的连续跟踪)。
工作流水线(粗略):
- 场景增强模块SEM(Scene Enhancement Module):对原始影像做像素级、迭代的曲线增强,生成增强模态 X ˉ \bar{X} Xˉ, Z ˉ \bar{Z} Zˉ(补强弱目标)。
- 提取-相关-适应模块ECAM(Extraction-Correlation-Adaptation Module):层级多模态 Transformer(浅层用局部关系建模 MLP 强化细节,深层用统一关系建模并嵌入 SMRA 做域适配),输出空间特征表示。
- 时序解码模块TDM(Temporal Decoding Module):将历史帧/历史模板状态通过 temporal prompts 和 attention propagation 融入当前推理,输出深时序增强的特征。
- 惯性导航模块INM(Inertial Navigation Module):基于物理时间特征(置信-不确定性选择器 CUM + 二次轨迹回归)在出现异常(FOC、DS 等)时提供轨迹补偿/延续。
- Head(检测回归头):分类分支 + center-offset 分支 + size 分支,损失为 focal loss + L1 + GIoU(有权重系数)。
总体上是一个“先增强,再提取/对齐,再时序融合,再物理补偿”的四阶段流水线。
Q5. 方法细节
此部分按模块介绍:
SEM(场景增强):
核心思想:用轻量的像素级迭代映射曲线增强低对比/弱目标区域,不破坏结构。
E
(
x
)
=
E
n
−
1
(
x
)
+
ψ
(
x
)
E
n
−
1
(
x
)
(
1
−
E
n
−
1
(
x
)
)
E(x) = E^{n-1}(x) + \psi(x)E^{n-1}(x)\big(1 - E^{n-1}(x)\big)
E(x)=En−1(x)+ψ(x)En−1(x)(1−En−1(x))
如公式所示:这里
x
x
x表示像素坐标,
ψ
(
x
)
\psi(x)
ψ(x)是像素相关的参数图,初始
E
(
0
)
(
x
)
E^{(0)}(x)
E(0)(x)是原始像素值,该公式类似于logistic增益项,会把中暗像素推亮,接近0或1时收敛。效果是生成一个“brightening auxiliary modality”以补强弱目标。生成的可学习参数图
ψ
\psi
ψ对速度影响小,适合帧率受限的SVOT。
为什么要用这个方式?是由于目的决定的,既然要增强,那就是要考虑到图像哪里要增强,也就是暗的地方变亮,增加对比度。
对应公式中
E
(
1
−
E
)
E(1-E)
E(1−E)部分在中间灰度处最大,意味着增强对中间暗度更敏感。
class DCE_Net(nn.Module):
def __init__(self, scale_factor=8):
super(DCE_Net, self).__init__()
self.relu = nn.ReLU(inplace=True)
self.scale_factor = scale_factor
self.upsample = nn.UpsamplingBilinear2d(scale_factor=self.scale_factor)
number_f = 32
#七层深度可分离卷积
self.e_conv1 = 优快云_Tem(3, number_f)
self.e_conv2 = 优快云_Tem(number_f, number_f)
self.e_conv3 = 优快云_Tem(number_f, number_f)
self.e_conv4 = 优快云_Tem(number_f, number_f)
self.e_conv5 = 优快云_Tem(number_f * 2, number_f)
self.e_conv6 = 优快云_Tem(number_f * 2, number_f)
self.e_conv7 = 优快云_Tem(number_f * 2, 3)
def enhance(self, x, x_r):
#8次迭代的曲线增强,对应论文中的迭代公式
for _ in range(8):
x = x + x_r * (torch.pow(x, 2) - x)
return x
def forward(self, x):
# 1.尺寸对齐
h = (x.shape[2] // self.scale_factor) * self.scale_factor
w = (x.shape[3] // self.scale_factor) * self.scale_factor
x = x[:, :, :h, :w]
# 2.下采样降低计算量
x_down = F.interpolate(x, scale_factor=1 / self.scale_factor, mode='bilinear') if self.scale_factor != 1 else x
# 3.特征提取
x1 = self.relu(self.e_conv1(x_down))
x2 = self.relu(self.e_conv2(x1))
x3 = self.relu(self.e_conv3(x2))
x4 = self.relu(self.e_conv4(x3))
# 4.特征融合
x5 = self.relu(self.e_conv5(torch.cat([x3, x4], 1)))
x6 = self.relu(self.e_conv6(torch.cat([x2, x5], 1)))
x_r = F.tanh(self.e_conv7(torch.cat([x1, x6], 1)))
# 5.恢复原始尺寸
if self.scale_factor != 1:
x_r = self.upsample(x_r)
# 6.曲线增强算法
return self.enhance(x, x_r)
具体的中间特征图执行流程如下
原始图像 [B,3,H,W]
↓ (下采样8倍)
低分辨率 [B,3,H/8,W/8]
↓ (编码器)
特征图 [B,32,H/8,W/8] (x1,x2,x3,x4)
↓ (解码器+Skip)
残差图 [B,3,H/8,W/8]
↓ (上采样8倍)
增强残差 [B,3,H,W]
↓ (曲线增强)
最终结果 [B,3,H,W]
按照项目中的enhancer源码来看,采用的是卷积的方式提取特征,最后通过这个增强算法公式迭代增强,然后保持原尺寸输出。
这样,在进入下一个模块前就得到了原始图像和增强图像的双流输入。
ECAM (核心)
ECAM 是 STAR 的核心——负责把(原始模态,增强模态)转成可用于匹配的 token 表示,同时做局部细节建模与全局跨图关系建模,并通过 SMRA 做域分布自适应(prompt/adapter 风格)。论文把 ECAM 分成两类层:浅层的 Local Relation Modeling(保留高分辨的局部细节)和深层的 Unified Relation Modeling(联合模板与搜索图,做 MHSA + SMRA)。
(1)LRM局部关系建模(浅层):
先看代码
class BlockWithRPE(nn.Module):
def __init__(self, input_size, dim, num_heads=0., mlp_ratio=4., qkv_bias=True, qk_scale=None,
drop=0., attn_drop=0., drop_path=0., rpe=True,
act_layer=nn.GELU, norm_layer=nn.LayerNorm):
super().__init__()
self.dim = dim
self.num_heads = num_heads
self.mlp_ratio = mlp_ratio
# 标准的自注意力机制
with_attn = num_heads > 0.
self.norm1 = norm_layer(dim) if with_attn else None
self.attn = Attention(
input_size, dim, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale,
attn_drop=attn_drop, proj_drop=drop, rpe=rpe,
) if with_attn else None
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
# 标准的MLP
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
def forward(self, x, rpe_index=None, mask=None, return_attention=True):
# 单核处理,保持局部细节
if self.attn is not None:
x1, x_att = self.attn(self.norm1(x), rpe_index, mask, return_attention=return_attention)
x = x + self.drop_path(x1)
x = x + self.drop_path(self.mlp(self.norm2(x)))
if self.attn is not None:
if return_attention:
return x, x_att
else:
return x
else:
return x
首先,从代码来看,这一结构采取的是单流处理,即原始图像流和增强图像流分别独立处理。这一部分也是浅层,浅层token数多、分辨率高,用标准MHSA(多头注意力机制)会抹掉局部精细信息,因此用MLP + 残差替代浅层 attention 来做局部增强(效率更高且保留细节)。
直观来看,MLP 做的是局部非线性变换 + 残差稳定梯度;相比attention,它不会平均掉位置信息,适合小目标的细节保存。
(MLP神经网络属于前馈神经网络的一种。在网络训练过程中,需要通过反向传播算法计算梯度,将误差从输出层反向传播回输入层,用于更新网络参数。)
(2)URM统一关系建模(深层):
与上面相比,此处是双流处理,先把 template 与 search 的浅层输出拼接(CAT),再进入 MHSA(multi-head self-attention)全局建模,随后通过 SMRA 做自适应细化。
SMRA 细节(关键):SMRA 有两支路——MLP 分支用于捕获局部细节,自调制(self-modulation)分支用于非局部/统计性自适应。其中,Self-modulation 分支(统计 + DWConv)先计算窗口方差
δ
2
\delta^2
δ2与均值池化
p
(
⋅
)
p(⋅)
p(⋅),拼接后过 depth-wise conv 与激活,再生成 modulation map
F
s
m
F_{sm}
Fsm,然后把 modulation 与原输入做逐元素乘并经 PWConv(pointwise conv)映射回 token shape。最后,把
F
m
l
p
⊕
F
m
−
o
u
t
F_{mlp}\oplus F_{m-out}
Fmlp⊕Fm−out融合成SMRA输出,再与attention输出做残差连接。
代码如下:
class BlockWithRPE_YZCU(nn.Module):
def __init__(self, input_size, dim, num_heads=0., mlp_ratio=4., qkv_bias=True, qk_scale=None,
drop=0., attn_drop=0., drop_path=0., rpe=True,
act_layer=nn.GELU, norm_layer=nn.LayerNorm):
# 相同的注意力机制用于双流
super().__init__()
self.dim = dim
self.num_heads = num_heads
self.mlp_ratio = mlp_ratio
with_attn = num_heads > 0.
self.norm1 = norm_layer(dim) if with_attn else None
self.attn = Attention(
input_size, dim, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale,
attn_drop=attn_drop, proj_drop=drop, rpe=rpe,
) if with_attn else None
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
# 关键:使用RefineMLP替代标准MLP
self.mlp = RefineMLP(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
def forward(self, x0, x1, rpe_index=None, mask=None, return_attention=True):
# 双流并行处理 (x0: 原始流, x1: 增强流)
if self.attn is not None:
x00, x0_att = self.attn(self.norm1(x0), rpe_index, mask, return_attention=return_attention) # 原始流MHSA
x11, x1_att = self.attn(self.norm1(x1), rpe_index, mask, return_attention=return_attention) # 增强流MHSA
x0 = x0 + self.drop_path(x00)
x1 = x1 + self.drop_path(x11)
# 使用RefineMLP进行统一关系建模
x0 = x0 + self.drop_path(self.mlp(self.norm2(x0)))
x1 = x1 + self.drop_path(self.mlp(self.norm2(x1)))
return (x0, x1, x0_att, x1_att) if return_attention else (x0, x1)
重点在于:在网络深层进行高级语义特征的交互,以及通过RefineMLP实现模板与搜索图的统一关系建模。其中,双流融合同时处理原始图像流(x0)与增强图像流(x1)。
MLP分支类似于常见的FFN,用于补充attention可能忽视的局部纹理;self-modolation通过局部方差+均值,产生一个空间性权重图,再用卷积提炼尺度信息,最后乘回原特征,起到按区域增强或抑制的作用。(这个过程很像SE / FiLM 类型的自调制,但把统计信息嵌入 depth-wise conv 捕获局部上下文)
SMRA的作用:SMRA是一种参数高效的 domain adapter → 保持大模型权重不变,只注入小模块做分布对齐(与 prompt/adapters 思路一致),因此对数据稀缺场景友好。
TDM时序解码模块(把历史照进现实)
以“深时序 prompts / temporal decoding”形式把历史帧的深层表示引入当前推理,做到端到端的历史状态推理(不是简单的模板替换)。论文中 TDM 包含 temporal decoding layer 与 spatiotemporal fusion layer,用 attention 传播捕获时间演化特征。
核心组件代码:
A.
class Transformer_dec(nn.Module):
def __init__(self, d_model=512, nhead=8, num_encoder_layers=6,
num_decoder_layers=6, dim_feedforward=768, dropout=0.1,
activation="relu", normalize_before=False,
return_intermediate_dec=False, divide_norm=False):
super().__init__()
# 构建解码器层
decoder_layer = TransformerDecoderLayer(d_model, nhead, dim_feedforward, dropout, activation, normalize_before,
divide_norm=divide_norm)
decoder_norm = nn.LayerNorm(d_model)
self.decoder = TransformerDecoder(decoder_layer, num_decoder_layers, decoder_norm,
return_intermediate=return_intermediate_dec)
self._reset_parameters()
self.d_model = d_model
self.nhead = nhead
self.d_feed = dim_feedforward
def _reset_parameters(self):
for p in self.parameters():
if p.dim() > 1:
nn.init.xavier_uniform_(p)
def forward(self, feat, tgt, feat_len_s, pos, query_embed):
memory = feat #来自backbone的特征
hs = self.decoder(tgt, memory, pos=pos, query_pos=query_embed)
return hs
B.
class TransformerDecoderLayer(nn.Module):
def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1,
activation="relu", normalize_before=False, divide_norm=False):
super().__init__()
# 自注意力机制 - 用于时序建模
self.self_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout)
# 交叉注意力机制 - 用于与encoder特征交互
self.multihead_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout)
self.linear1 = nn.Linear(d_model, dim_feedforward)
self.dropout = nn.Dropout(dropout)
self.linear2 = nn.Linear(dim_feedforward, d_model)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.norm3 = nn.LayerNorm(d_model)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
self.dropout3 = nn.Dropout(dropout)
self.activation = _get_activation_fn(activation)
self.normalize_before = normalize_before
self.divide_norm = divide_norm
self.scale_factor = float(d_model // nhead) ** 0.5
def with_pos_embed(self, tensor, pos: Optional[Tensor]):
return tensor if pos is None else tensor + pos
def forward_post(self, tgt_all, memory,
tgt_mask: Optional[Tensor] = None,
memory_mask: Optional[Tensor] = None,
tgt_key_padding_mask: Optional[Tensor] = None,
memory_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None,
query_pos: Optional[Tensor] = None):
tgt_q = tgt_all[0] # 当前帧查询
tgt_kv = tgt_all[1] # 历史帧键值对
q = tgt_q
k = tgt = tgt_kv
# 时序自注意力
tgt2 = self.self_attn(q, k, value=tgt, attn_mask=tgt_mask,
key_padding_mask=tgt_key_padding_mask)[0]
tgt = tgt_q + self.dropout1(tgt2)
tgt = self.norm1(tgt)
# 与encoder特征的交叉注意力
tgt2 = self.multihead_attn(query=self.with_pos_embed(tgt, query_pos),
key=self.with_pos_embed(memory, pos),
value=memory, attn_mask=memory_mask,
key_padding_mask=memory_key_padding_mask)[0]
tgt = tgt + self.dropout2(tgt2)
tgt = self.norm2(tgt)
tgt2 = self.linear2(self.dropout(self.activation(self.linear1(tgt))))
tgt = tgt + self.dropout3(tgt2)
tgt = self.norm3(tgt)
return [tgt, tgt_all[1]]
时序处理逻辑核心代码如下
def forward(self, template: torch.Tensor,
search: torch.Tensor,
return_last_attn=False,
training=True,
tgt_pre=None,
):
# backbone特征提取
for i, batch in enumerate(batches):
if len(batch) == 0:
continue
tgt_all = [torch.zeros_like(query_embeding) for _ in range(num_search)]
for j, input in enumerate(batch):
pos_embed = self.position_encoding(1)
tgt_q = tgt_all[j] # 当前帧查询
tgt_kv = torch.cat(tgt_all[:j + 1], dim=0) # 累计的键值对
# 关键:使用历史帧信息进行时序解码
if not training and len(tgt_pre) != 0:
tgt_kv = torch.cat(tgt_pre, dim=0)
tgt = [tgt_q, tgt_kv]
# 调用TDM进行时序解码
tgt_out = self.transformer_dec(input.transpose(0, 1), tgt, self.feat_len_s, pos_embed, query_embeding)
x_decs.append(tgt_out[0])
tgt_all[j] = tgt_out[0]
历史状态管理机制:
# 维护历史3帧的解码器状态
if not training:
if len(tgt_pre) < 3:
tgt_pre.append(tgt_out[0]) # 添加新状态
else:
tgt_pre.pop(0) # 删除最旧状态
tgt_pre.append(tgt_out[0]) # 添加最新状态
TDM的设计在于弥补了纯跟踪的“短视”,在真实卫星视频里,目标可能短暂消失、变小、变暗。如果只靠当前帧,容易漂移或丢失。而TDM 用深度时序解码器,把“历史状态 token”输入当前推理,做到 时序信息的端到端融合,而不是简单模板替换。
而具体的设计中,包含以下几部分细节:
- 通过 自注意力(Self-Attention) 捕捉历史帧之间的动态依赖;在时序维度里,回答“历史哪些帧对当前帧有帮助?”,结果就是当前帧学会从历史帧里挑有用的特征。这等于一个“动态加权的记忆检索机制”。
- 通过 交叉注意力(Cross-Attention) 把历史时序信息与当前空间特征对齐;这是把“历史运动趋势”对接到“当前视觉场景”。
- 通过 滑动窗口机制 高效地管理历史记忆(比如只保留最近 3 帧)。
- Transformer 本身不理解“顺序”,所以要加一个位置向量。在 TDM 里,它帮助模型区分:这是“第几帧”,而不是无序的 token。
INM惯性导航模块(惯性的力量)
在 STAR 框架里,INM 的作用就是 “兜底”: 当网络的视觉预测不可靠(例如完全遮挡、噪声、模糊)时,用运动学的惯性模型维持目标轨迹的连续性。它解决的是最糟糕的情况,即完全遮挡、干扰目标、低对比度与弱信号等。
核心实现代码:
class MotionModel:
def __init__(self):
self.trajectory_length = 1
self.history_x, self.history_y, self.history_factor = [], [], []
def calculate_apce(self, response_map):
R_max, R_min = np.max(response_map), np.min(response_map)
return R_max
def compute_cur_his_confidence(self, response_map):
"""计算当前帧置信度和历史可靠置信度"""
R_max = np.max(response_map)
peak_idx = np.unravel_index(np.argmax(response_map), response_map.shape)
side_lobe = np.delete(response_map.flatten(), np.ravel_multi_index(peak_idx, response_map.shape))
R_mean, R_std = np.mean(side_lobe), np.std(side_lobe)
# PSR (Peak-to-Sidelobe Ratio) 计算
psr = 0 if R_std == 0 else (R_max - R_mean) / R_std
# 计算当前帧置信度
cur_confid = psr * R_max
# 计算历史可靠置信度
his_reliable_confid = np.mean(self.history_factor) if self.history_factor else cur_confid
return cur_confid, his_reliable_confid
def fit(self, data, degree=2):
"""多项式拟合预测下一帧位置"""
if len(data) < 2:
return data[-1] if data else 0
return np.poly1d(np.polyfit(range(len(data)), data, degree))(len(data))
def update_pos(self, new_x, new_y):
self.history_x.append(new_x)
self.history_y.append(new_y)
if len(self.history_x) > self.trajectory_length:
self.history_x.pop(0)
self.history_y.pop(0)
def update_confidence(self, cur_confid):
if cur_confid is not None:
self.history_factor.append(cur_confid)
def predict(self):
return self.fit(self.history_x), self.fit(self.history_y)
def get_corrected_pos(self, frame_id, response_map, occlusion_threshold=0.0, trajectory_length=10000):
"""INM的核心逻辑:检测遮挡并提供惯性导航"""
self.trajectory_length = trajectory_length
cur_confid, his_reliable_confid = self.compute_cur_his_confidence(response_map)
# 前30帧不进行INM处理
if frame_id < no_process_frame_num:
return cur_confid, None, None, False
# 关键:遮挡检测与惯性导航
if cur_confid / his_reliable_confid < occlusion_threshold:
predicted_x, predicted_y = self.predict() # 惯性预测
return None, predicted_x, predicted_y, True
return cur_confid, None, None, False
跟踪流程中的体现:
# 调用INM进行遮挡检测和位置修正
cur_confid, correct_x, correct_y, is_abnormal = self.motion_model.get_corrected_pos(self.frame_id, respons_map,
occlusion_threshold=self.params.occlusion_threshold,
trajectory_length=self.params.cfg.TEST.TRAJECTORY_LENGTH)
# 如果检测到遮挡,使用INM预测的位置
if is_abnormal:
self.state = [correct_x, correct_y, self.state[2], self.state[3]]
# 更新历史轨迹和置信度
self.motion_model.update_pos(*self.state[:2])
self.motion_model.update_confidence(cur_confid)
工作机制具体:
A.置信度计算
PSR(Peak-to-Sidelobe Ratio,峰值旁瓣比)
# PSR (Peak-to-Sidelobe Ratio) 算法
psr = (R_max - R_mean) / R_std
cur_confid = psr * R_max
其中, R m a x R_{max} Rmax是响应图最大值, R m e a n R_{mean} Rmean和 R s t d R_{std} Rstd来自非峰值部分。作用是衡量“目标信号是否清晰”。如果响应图是尖峰,PSR 高 → 置信度强;如果平坦或噪声大,PSR 低 → 不可靠。
B.遮挡检测
当前帧置信度 / 历史平均置信度 < 阈值(比如 0.4) → 判断为异常。这是 归一化检测,避免仅靠绝对值(因为不同帧、不同视频的响应强度分布不同)。
# 置信度比值判断
if cur_confid / his_reliable_confid < occlusion_threshold:
# 检测到遮挡,启动惯性导航
C.轨迹预测
用最近轨迹点拟合一个二次函数
p
(
t
)
=
β
0
+
β
1
t
+
β
2
t
2
p(t)=\beta_0+\beta_1t+\beta_2t^2
p(t)=β0+β1t+β2t2。这个方式可以描述直线运动(一次项)和加速/减速(平方项)。
# 二次多项式拟合
np.poly1d(np.polyfit(range(len(data)), data, degree=2))(len(data))
为什么不是更高阶?因为高阶容易过拟合噪声;二次是平衡复杂度和拟合力的折中。
Head与Loss
- Head 的输出与它们的语义
Head有三条并行分支:
- Center branch(1 通道置信度图):输出表示每个下采样格点(token)为中心点的概率或热力值(center heatmap)。 作用:把目标定位问题转成密集分类 / 概率图的形式,便于处理小目标与多实例、减少 anchor 设计。
- Offset branch(2 通道):输出表示在网格坐标基础上的亚像素偏移 Δ x , Δ y Δx,Δy Δx,Δy。 作用:补偿下采样带来的离散误差,实现亚像素级中心定位。
- Size branch(2 通道):输出表示目标宽高(例如 w , h w,h w,h 或对数尺度)。作用:预测 bbox 的尺度信息,用于从中心恢复出边框。
class CenterPredictor(nn.Module, ):
def __init__(self, inplanes=64, channel=256, feat_sz=20, stride=16, freeze_bn=False):
super(CenterPredictor, self).__init__()
self.feat_sz = feat_sz
self.stride = stride
self.img_sz = self.feat_sz * self.stride
# 三个分支网络
# 1. 中心点分支 (Center Branch)
self.conv1_ctr = conv(inplanes, channel, freeze_bn=freeze_bn)
self.conv2_ctr = conv(channel, channel // 2, freeze_bn=freeze_bn)
self.conv3_ctr = conv(channel // 2, channel // 4, freeze_bn=freeze_bn)
self.conv4_ctr = conv(channel // 4, channel // 8, freeze_bn=freeze_bn)
self.conv5_ctr = nn.Conv2d(channel // 8, 1, kernel_size=1)
# 输出: 1个通道的置信图
# 2. 偏移分支 (Offset Branch)
self.conv1_offset = conv(inplanes, channel, freeze_bn=freeze_bn)
self.conv2_offset = conv(channel, channel // 2, freeze_bn=freeze_bn)
self.conv3_offset = conv(channel // 2, channel // 4, freeze_bn=freeze_bn)
self.conv4_offset = conv(channel // 4, channel // 8, freeze_bn=freeze_bn)
self.conv5_offset = nn.Conv2d(channel // 8, 2, kernel_size=1)
# 输出: 2个通道的偏移图
# 3. 尺寸分支 (Size Branch)
self.conv1_size = conv(inplanes, channel, freeze_bn=freeze_bn)
self.conv2_size = conv(channel, channel // 2, freeze_bn=freeze_bn)
self.conv3_size = conv(channel // 2, channel // 4, freeze_bn=freeze_bn)
self.conv4_size = conv(channel // 4, channel // 8, freeze_bn=freeze_bn)
self.conv5_size = nn.Conv2d(channel // 8, 2, kernel_size=1)
# 输出: 2个通道的尺寸图
for p in self.parameters():
if p.dim() > 1:
nn.init.xavier_uniform_(p)
def forward(self, x, gt_score_map=None):
score_map_ctr, size_map, offset_map = self.get_score_map(x)
if gt_score_map is None:
bbox = self.cal_bbox(score_map_ctr, size_map, offset_map)
else:
bbox = self.cal_bbox(gt_score_map.unsqueeze(1), size_map, offset_map)
return score_map_ctr, bbox, size_map, offset_map
Head的网络构建:
def build_box_head(cfg, hidden_dim):
stride = cfg.MODEL.BACKBONE.STRIDE
if cfg.MODEL.HEAD.TYPE == "MLP":
mlp_head = MLP(hidden_dim, hidden_dim, 4, 3)
return mlp_head
elif "CORNER" in cfg.MODEL.HEAD.TYPE:
feat_sz = int(cfg.DATA.SEARCH.SIZE / stride)
channel = getattr(cfg.MODEL, "NUM_CHANNELS", 256)
print("head channel: %d" % channel)
if cfg.MODEL.HEAD.TYPE == "CORNER":
corner_head = Corner_Predictor(inplanes=cfg.MODEL.HIDDEN_DIM, channel=channel,
feat_sz=feat_sz, stride=stride)
else:
raise ValueError()
return corner_head
elif cfg.MODEL.HEAD.TYPE == "CENTER":
in_channel = hidden_dim # 512
out_channel = cfg.MODEL.HEAD.NUM_CHANNELS # 256
feat_sz = int(cfg.DATA.SEARCH.SIZE / stride) # 256/16 = 16
center_head = CenterPredictor(inplanes=in_channel, channel=out_channel,
feat_sz=feat_sz, stride=stride)
return center_head
else:
raise ValueError("HEAD TYPE %s is not supported." % cfg.MODEL.HEAD_TYPE)
损失函数
STAR的损失函数是用的多种组合,包含GIoU、L1、Focal、分类损失等。
其中权重比为2.0:5.0:1.0:1.0。
def compute_losses(self, pred_dict, gt_dict, return_status=True):
gt_bbox = gt_dict['search_anno'].view(-1, 4)
# 1.生成高斯热力图作为Ground Truth
gts = gt_bbox.unsqueeze(0)
gt_gaussian_maps = generate_heatmap(gts, self.cfg.DATA.SEARCH.SIZE, self.cfg.MODEL.BACKBONE.STRIDE)
gt_gaussian_maps = gt_gaussian_maps[-1].unsqueeze(1)
pred_boxes = pred_dict['pred_boxes']
if torch.isnan(pred_boxes).any():
raise ValueError("Network outputs is NAN! Stop Training")
num_queries = pred_boxes.size(1)
# 2.GIOU LOSS计算
pred_boxes_vec = box_cxcywh_to_xyxy(pred_boxes).view(-1, 4)
gt_boxes_vec = box_xywh_to_xyxy(gt_bbox)[:, None, :].repeat((1, num_queries, 1)).view(-1, 4).clamp(min=0.0,
max=1.0)
try:
giou_loss, iou = self.objective['giou'](pred_boxes_vec, gt_boxes_vec)
except:
giou_loss, iou = torch.tensor(0.0).cuda(), torch.tensor(0.0).cuda()
# 3.L1 LOSS计算
l1_loss = self.objective['l1'](pred_boxes_vec, gt_boxes_vec)
# 4.Focal LOSS计算(中心点定位)
if 'score_map' in pred_dict:
location_loss = self.objective['focal'](pred_dict['score_map'], gt_gaussian_maps)
else:
location_loss = torch.tensor(0.0, device=l1_loss.device)
# 5.总损失加权求和
loss = self.loss_weight['giou'] * giou_loss + self.loss_weight['l1'] * l1_loss + self.loss_weight[
'focal'] * location_loss
if return_status:
mean_iou = iou.detach().mean()
status = {"Loss/total": loss.item(),
"Loss/giou": giou_loss.item(),
"Loss/l1": l1_loss.item(),
"Loss/location": location_loss.item(),
"IoU": mean_iou.item()}
return loss, status
else:
return loss
具体的损失函数详细介绍:
A.Focal Loss 中心点定位损失
作用:解决中心点检测中的正负样本不平衡问题
def __init__(self, alpha=2, beta=4):
super(FocalLoss, self).__init__()
self.alpha = alpha # 难易样本调节参数
self.beta = beta # 负样本权重调节参数
def forward(self, prediction, target):
# 计算正样本损失
positive_index = target.eq(1).float()
# 计算负样本损失(加权)
negative_index = target.lt(1).float()
negative_weights = torch.pow(1 - target, self.beta)
prediction = torch.clamp(prediction, 1e-12)
positive_loss = torch.log(prediction) * torch.pow(1 - prediction, self.alpha) * positive_index
negative_loss = torch.log(1 - prediction) * torch.pow(prediction,
self.alpha) * negative_weights * negative_index
num_positive = positive_index.float().sum()
positive_loss = positive_loss.sum()
negative_loss = negative_loss.sum()
if num_positive == 0:
loss = -negative_loss
else:
# 平衡正负样本
loss = -(positive_loss + negative_loss) / num_positive
return loss
B. GIoU Loss 边界框回归损失
作用: 提供更精确的边界框回归监督信号
def generalized_box_iou(boxes1, boxes2):
assert (boxes1[:, 2:] >= boxes1[:, :2]).all()
assert (boxes2[:, 2:] >= boxes2[:, :2]).all()
iou, union = box_iou(boxes1, boxes2)
# 计算最小外接矩阵
lt = torch.min(boxes1[:, :2], boxes2[:, :2])
rb = torch.max(boxes1[:, 2:], boxes2[:, 2:])
wh = (rb - lt).clamp(min=0)
area = wh[:, 0] * wh[:, 1]
# GIoU = IoU - (A_c - U) / A_c
return iou - (area - union) / area, iou
C.高斯热力图生成
def generate_heatmap(bboxes, patch_size=320, stride=16):
gaussian_maps = []
heatmap_size = patch_size // stride # 320/16=20
for single_patch_bboxes in bboxes:
bs = single_patch_bboxes.shape[0]
gt_scoremap = torch.zeros(bs, heatmap_size, heatmap_size)
classes = torch.arange(bs).to(torch.long)
bbox = single_patch_bboxes * heatmap_size
wh = bbox[:, 2:]
centers_int = (bbox[:, :2] + wh / 2).round()
# 使用CenterNet 的高斯核生成热力图
CenterNetHeatMap.generate_score_map(gt_scoremap, classes, wh, centers_int, 0.7)
gaussian_maps.append(gt_scoremap.to(bbox.device))
return gaussian_maps
上述的Loss中,Focal Loss专注于难分类样本,解决中心点检测中的类别不平衡;GIoU Loss考虑边界框间的几何关系,比传统IoU更准确;L1 Loss: 提供直接的坐标回归监督;多重监督从分类、定位、回归三个角度全面优化。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









