




 本文介绍了2014年谷歌发表的关于Seq2Seq模型的开创性论文,包括其结构(编码器-解码器)、在机器翻译中的应用、长程依赖问题的解决方法(注意力机制)以及当时的实验挑战。作者还提到了模型的局限性和优化策略,如使用LSTM和Transformer的改进。
本文介绍了2014年谷歌发表的关于Seq2Seq模型的开创性论文,包括其结构(编码器-解码器)、在机器翻译中的应用、长程依赖问题的解决方法(注意力机制)以及当时的实验挑战。作者还提到了模型的局限性和优化策略,如使用LSTM和Transformer的改进。
诸神缄默不语-个人优快云博文目录
诸神缄默不语的论文阅读笔记和分类
论文名称:Sequence to Sequence Learning with Neural Networks
ArXiv下载地址:https://arxiv.org/abs/1409.3215
本文是2014年NeurIPS论文(那时候这个会还叫NIPS),作者来自谷歌。本文是seq2seq (sequence to sequence) 模型的开山之作,一般来说现在写到seq2seq模型的时候就会引用这篇论文。
1. Seq2Seq模型
Seq2Seq模型处理输入和输出都是一组序列的数据,在自然语言处理领域主要就是文本生成相关的任务,如机器翻译、文本摘要、问答等。
Seq2Seq 模型由两个主要的组成部分构成:编码器(Encoder)和解码器(Decoder),两部分都是RNN。编码器将输入序列转换为固定长度的上下文向量,然后解码器使用这个上下文向量来生成输出序列。
类似思路的工作之前也见:
(2013 EMNLP) Recurrent continuous translation models:这篇是用的CNN
(2014 EMNLP) Learning phrase representations using RNN encoder-decoder for statistical machine translation:关注于将RNN嵌入统计翻译模型。用纯RNN,因为长程依赖问题所以效果不好
(2015 ICLR) Neural machine translation by jointly learning to align and translate:在上一篇的基础上加入attention,试图解决长序列问题
原论文示例图:
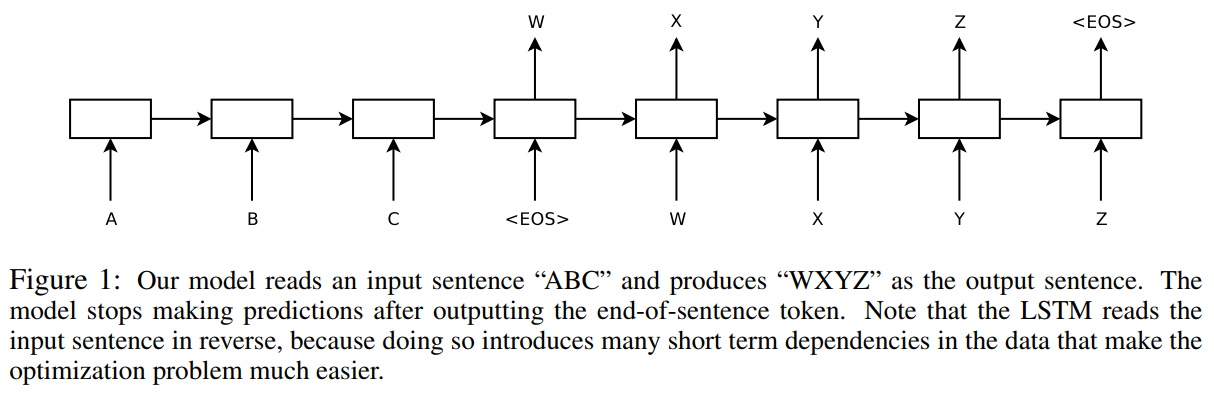
由4层LSTM(Long Short-Term Memory)将输入序列转换为固定维度的向量,再用另一个LSTM将向量解码为输出序列。本文是在机器翻译领域做的,但显然后来这个模型被扩展到了各种文本到文本的任务上。
用LSTM来对SOTA(SMT统计机器翻译模型)输出结果重排序(计算LSTM对hypothesis表征的对数似然作为LSTM得分,和原始得分求平均作为最终得分)后,可以提升BLEU指标。
本文还发现倒转输入序列顺序能提高模型效果。(一个trick)这个很奇怪,我也没太搞懂,我怀疑是因为RNN对最后的输入最敏感,但是语句就是最前面的最重要,所以就这样了。原文说是因为这么干能引入短程信息。
RNN:
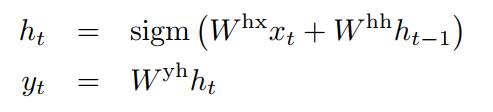
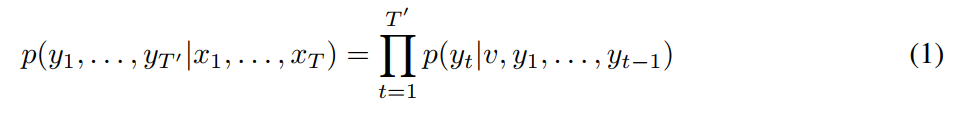
训练目标:
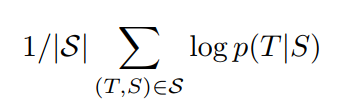

当时应该还没有系统性总结为encoder-decoder架构,一个encoder-decoder架构更清晰的示意图见:(我后来又看了一下,之前的参考文献里就有了,但是s2s这篇没有按照这种格式来画)
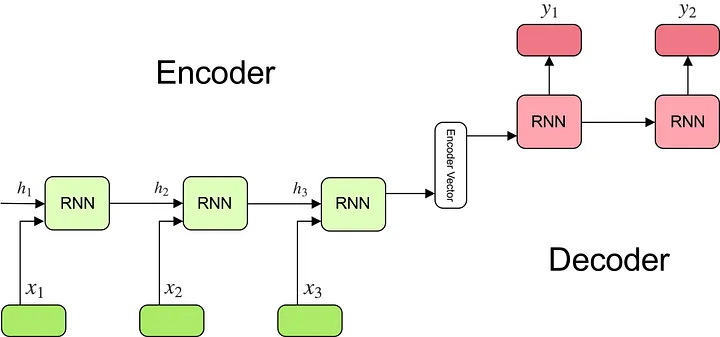
原始Seq2Seq有显著的长程依赖问题,后续研究提出注意力(attention)机制减缓这一问题。
transformer还有一个idea就是RNN不能并行,所以直接用矩阵乘法实现并行,然后改进了编码方式,来将token的位置信息编码进模型。
2. 实验
当年条件还是很艰苦的,要用C++手写代码,一个4层LSTM模型要分到8个GPU上并行,一次要跑10天……

当年论文也是不需要超过SOTA的。
句子向量可视化:
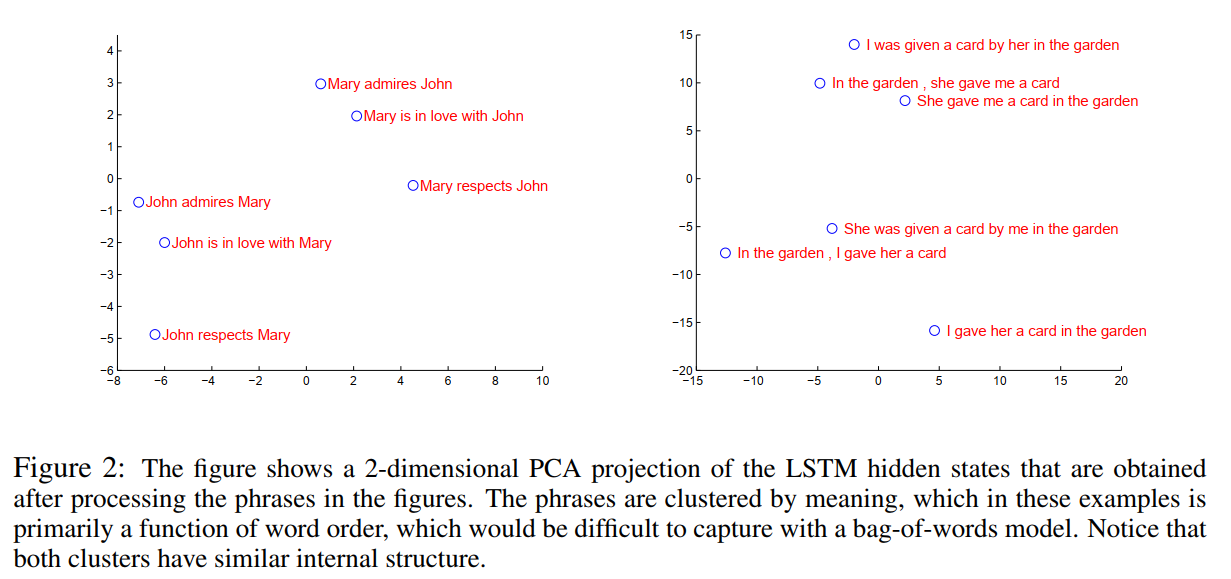
案例分析:

长度对模型效果的影响和少见词语对模型效果的影响:
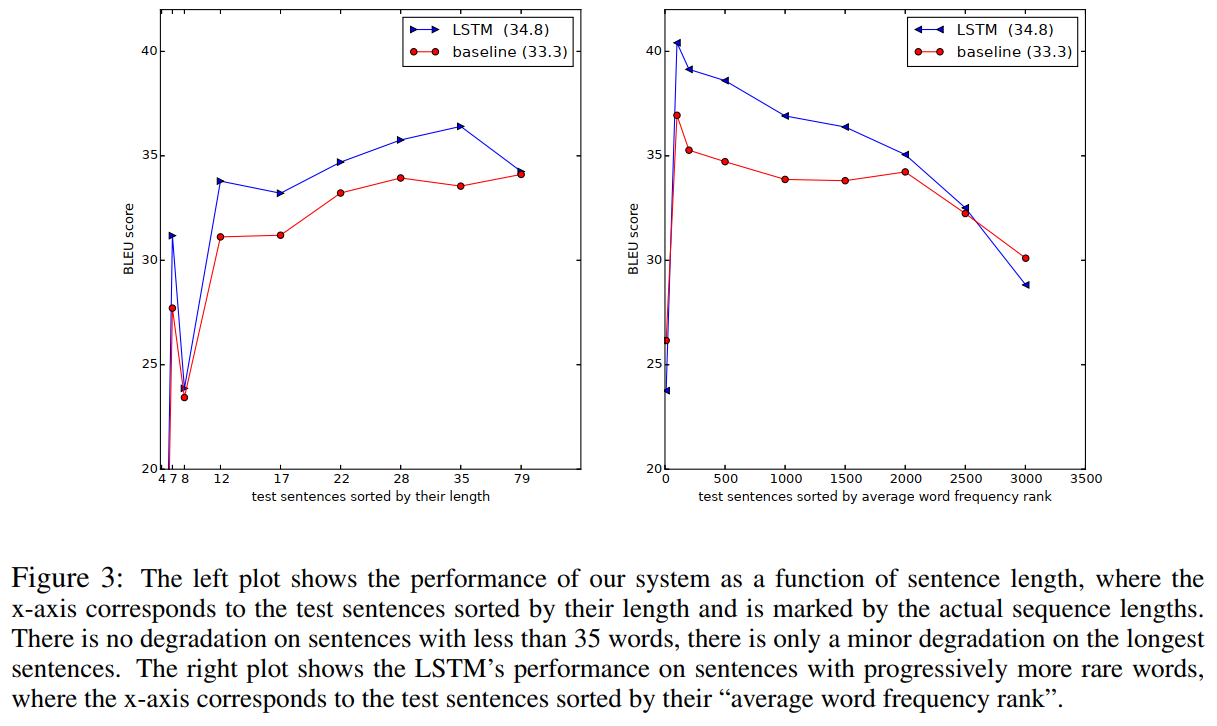


















 2657
2657

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











