




 本文介绍了2022年IJCAI论文《ConstitutiveElements-guidedChargePrediction(CECP)》的内容,该模型针对法律判决预测任务,利用强化学习自动抽取案件中的犯罪构成要件(CE)。CECP模型通过编码网络、强化学习模块和预测网络逐步学习句子与CE的匹配,以模拟司法鉴定过程。实验结果表明,CECP在罪名预测中表现出优越性能,与CEEN等其他方法相比,CECP更注重CE之间的逻辑顺序。此外,代码和数据已在GitHub上公开,可供研究者复现和进一步探索。
本文介绍了2022年IJCAI论文《ConstitutiveElements-guidedChargePrediction(CECP)》的内容,该模型针对法律判决预测任务,利用强化学习自动抽取案件中的犯罪构成要件(CE)。CECP模型通过编码网络、强化学习模块和预测网络逐步学习句子与CE的匹配,以模拟司法鉴定过程。实验结果表明,CECP在罪名预测中表现出优越性能,与CEEN等其他方法相比,CECP更注重CE之间的逻辑顺序。此外,代码和数据已在GitHub上公开,可供研究者复现和进一步探索。
论文名称:Charge Prediction by Constitutive Elements Matching of Crimes
IJCAI官方下载地址:https://www.ijcai.org/proceedings/2022/0627.pdf
官方GitHub项目:https://github.com/jiezhao6/CECP
本文是2022年IJCAI论文,作者来自西电。
本文关注charge prediction任务(属于LJP任务),使用强化学习的方法抽取案例中含有犯罪要素constitutive elements (CE) 的句子,以模拟现实场景中的指控鉴定过程。
本文提出 Constitutive Elements-guided Charge Prediction (CECP) 模型,无需人工匹配CE实例,而是使用强化学习模块逐步学习句子和CE的匹配,并评估其相关性。最终的预测结果基于选择出的句子和对应的CE生成。
上述逻辑很像同在2022年推出的LJP任务的论文Improving legal judgment prediction through reinforced criminal element extraction(模型叫CEEN,发在B刊Information Processing & Management上)。对两篇论文异同的解释,如有需求,可以看本文最后一节。
另外还有一篇也用到CE概念的论文《Element-Aware Legal Judgment Prediction for Criminal Cases with Confusing Charges》(2019年ICATI论文),这篇所说的CE其实比较靠近Few Shot一文中的特征概念。就是比较常规的把CE当成一个多任务学习目标(应该是直接在数据集中进行标注的),然后做的。
CE(犯罪要件)概念(来自1,这个具体顺序呢就是说在刑法界本身也有争议)的逻辑顺序:
以认定与处理犯罪的过程为标准,通说所主张的犯罪构成要件的排列顺序应修正为“犯罪客观要件—犯罪主体要件—犯罪主观要件—犯罪客体要件”(这也是CECP本文所使用的顺序)
文章目录
1. Background
传统罪名预测任务被视为文本分类任务,但是加上了法律知识(刑法法条文本或司法解释等)。两种主流使用法律知识的方式为:
- 评估事实描述和法条之间的关联,用以预测罪名234,这种做法粒度太粗,因为单个法条可能对应多条罪名,法条级别的差异对罪名识别仍有不足,不足以区分这些易混淆罪名之间的细微差别。
- 手动抽取legal attributes(如罪犯是否有暴力行为)567,这对专家人力要求很高,而且难以理解。
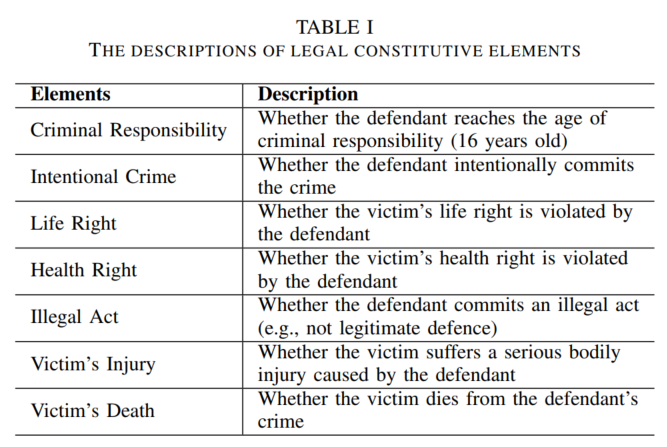
大陆法系的犯罪要素(CE8)是重要的司法解释(不在法条中)(作者官方GitHub给出了各罪名的CE原始数据:CECP/data/CEs at main · jiezhao6/CECP · GitHub),借以指导判决。
描述一个罪名的CE:
- subject element
- subjective element
- object element
- objective element
CE示例图(CE与对应的实例):

嫌疑人的事实匹配了纵火罪的4个CE,所以被叛纵火罪。
9利用了objective和subjective信息(设计双层模型,用以可解释的罪名预测:先通过主观元素预测出一个candidate list,然后通过客观元素从中预测出最终charge),但完整利用4个CE也很重要。
CE的识别逻辑顺序:
- 损害事实(objective):火灾
- 原因(subject):火是否人造
- 罪犯是否有责任,有什么责任(subjective):当事人精神态度(区别蓄意纵火和失火罪)
- 什么社会关系(object)被破坏,罪名是否成立1:公众安全是否被损害,是否有人获罪
2. CECP模型
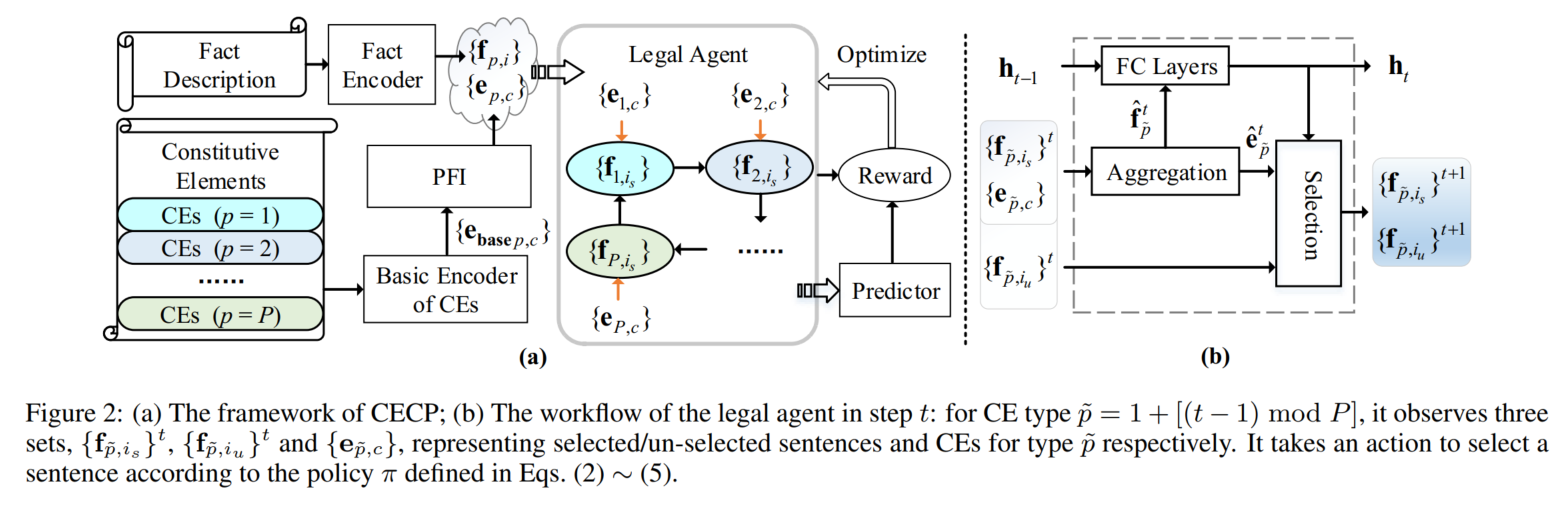
legal agent:自动挖掘CE实例(句子)
actor-critic框架
CE是词序列
用encoder network中得到的事实描述和CE的嵌入作为observations
按类型组合不同罪名的CE,依CE逻辑顺序循环迭代选取每一类最重要的实例(句子)
在每一时间步,加权聚合该类CE预先选出的句子,和该类CE本身,权重由二者间的relevance estimation计算得到
这相当于提供了选出句子的摘要表征和与实例、罪名最相关的CE
然后agent基于这个CE的摘要表征和历史表征(编码以前对所有CE类选出的句子,强调高相关权重的句子)选出一个未选过的句子,这个历史表征表示“以前识别出的重点”,由当前类选出句子的摘要表征更新。
最后用选出句的摘要表征和所有CE类的CE来预测罪名。
reward function基于预测结果和各类CE被选出句子的重复程度设计。
强化学习我不太懂,也未作更多了解。
2.1 Encoder Network
(在句子级别上)编码事实描述和CE
- Fact Encoder
GRU + scaled dot-product attention + 最大池化(没看懂这个公式其实,总之大约是这个意思)
每个CE类构建一个GRU - CE Encoder:类似同上模型 → Pivotal Feature Identification (PFI) layer(去掉罪名表征间方差较小的维度)
这个GRU的细节看附件
2.2 Reinforcement Learning Module
自动抽取事实描述文本中对应的CE实例(遵循CE逻辑顺序,循环迭代)将事实描述文本拆成4部分
legal agent
policy
action
value(选出的句子过全连接层)
输入:事实描述和CE的表征(observation),按CE类组合不同罪名的CE
- Aggregation:分别加权聚合(先最大池化,然后计算attention)已选句子和CE集合(environment)(权重根据其间的relevance estimation计算得到)(就是attention,类似bi-directional attention10)(具体巴拉巴拉的没看懂)
- 用加权聚合后的已选句子来更新history embedding (一种hidden state的感觉)(根据该类CE最相关的选出句子):记忆之前所有步骤中最相关的句子
- 基于每个未选择句子与加权聚合后的CE、history embedding的交互,计算未选择句子上的概率分布,选择一句(基于当前步的CE和之前所有已选句子来选择新句子)
在选中句子的数目达到预先设定的阈值后,停止迭代。
Reward Function(这块也没看懂,略)
2.3 Prediction Network
把4部分事实描述,和对应的4组CE(每个CE类都已根据选出句子与CE的relevance estimation聚合过)
2.4 训练过程
这一部分见附件。
交替优化3个模块。
encoder和predictor用交叉熵,并预训练。RL模块用A3C算法。
因为我不太懂RL,所以别的略。
3. 实验
3.1 数据集
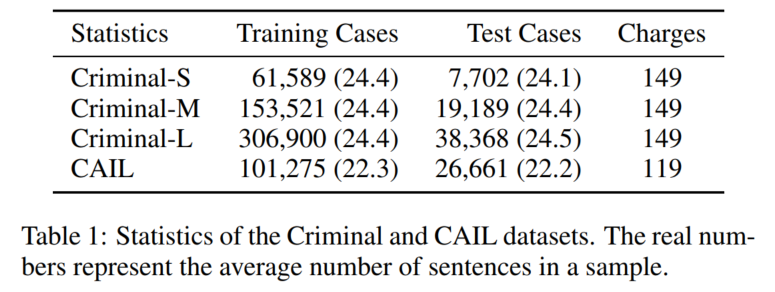
Criminal: Few-shot charge prediction with discriminative legal attributes
CAIL: CAIL2018: A large-scale legal dataset for judgment prediction
(两个应该都是里面的small数据集)
3.2 baseline
常规文本分类模型ordinary text classification (OTC):
- TextCNN
- DPCNN
- HARNN
- BERT
- SAttCaps: Learning to Predict Charges for Legal Judgment via Self-Attentive Capsule Network(这玩意能算OTC吗)
基于法律知识的文本分类模型 legal knowledge based (LKB):
- FewShot
- FLA
- LADAN
3.3 实验设置
这部分写到附件里了,我看了一遍,感觉没有特别突出值得强调的地方,所以略。
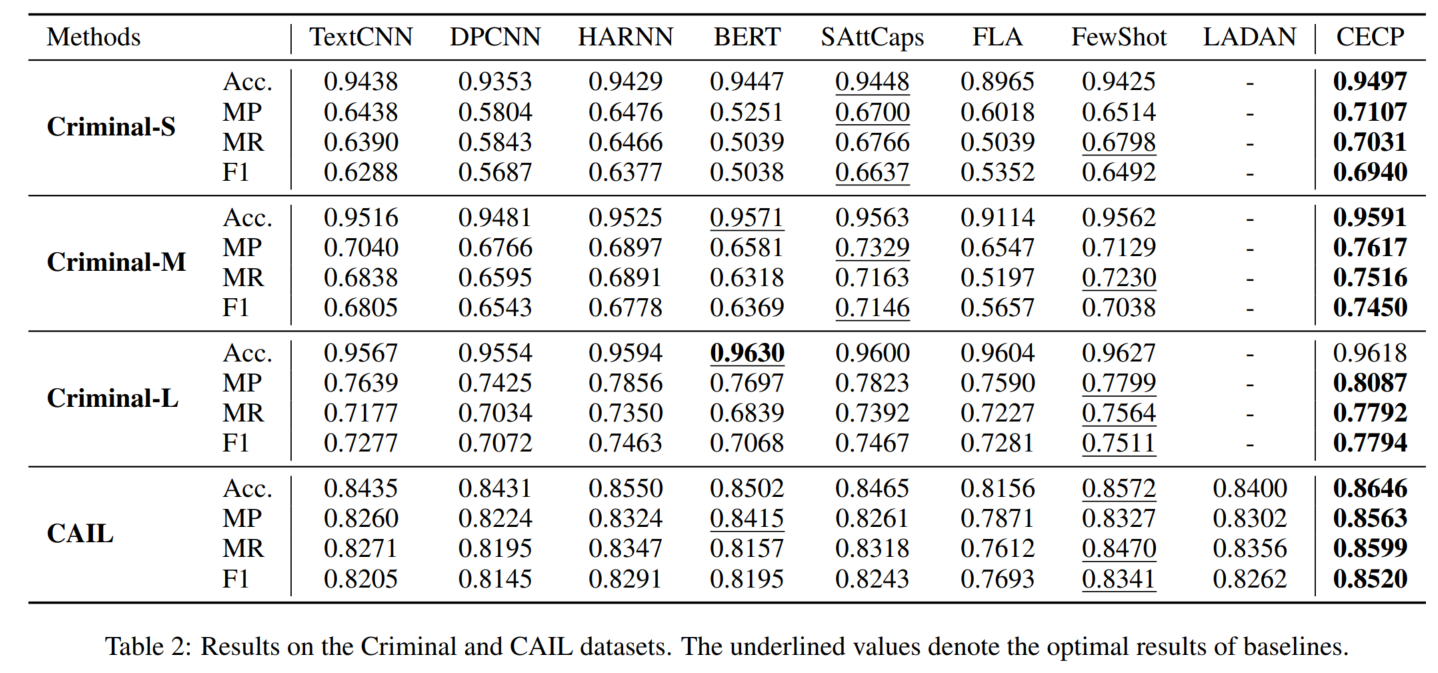
3.4 主实验结果
3.5 模型分析
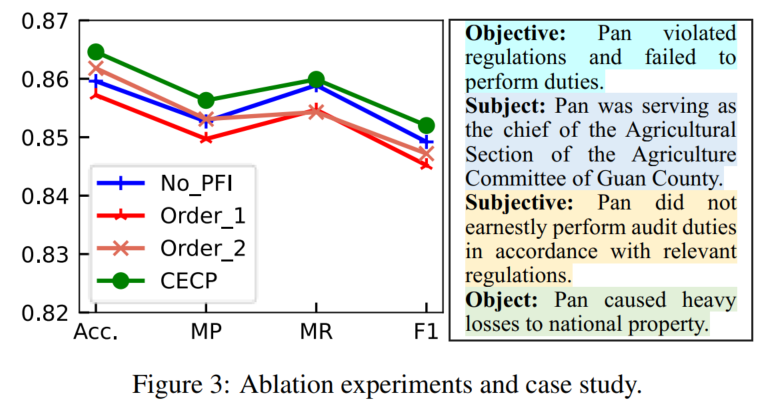
ablation study:
- the PFI layer
- RL模型的逻辑顺序(换了2种变体)
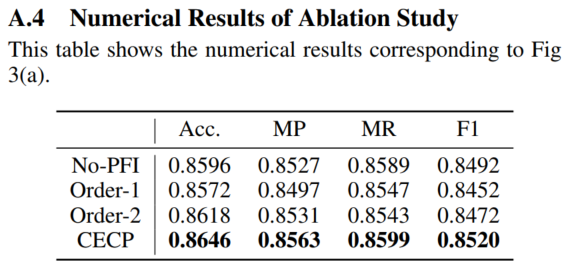
案例分析的罪名是滥用职权abuse of power (AP)(案例中每个CE类型的aggregation weights最大的句子)
(这里还毫无意义地提了一下ethical问题,得出的结论是这依然是个open problem……听君一席话,如听一席话)
4. 代码复现
4.1 数据
- Criminal:GitHub项目里给了处理后的下载地址(
describes the fact descriptions and corresponding constitutive elements by the wordID and the pre-trained word embedding,具体信息我还没看):https://pan.baidu.com/s/1pk8-h-UYGKfl31pMqmdsFA?pwd=itmd - CAIL:处理方式可参考(这个就需要用LADAN4的那个预训练词向量矩阵了):
small数据:
punctuations='。:();:“”,,' #用这些标点符号作为分句指标,并且不保留这几个标点符号本身
max_sent_num=64
max_sent_len=32 #这两个是CECP原本的设置
for k in ['train','valid','test']:
x=[]
y=[]
sent_num=[]
sent_len=[]
path='/data/cail_ladan/legal_basis_data_small/'+k+'_processed_thulac_Legal_basis.pkl'
with open(path, 'rb') as f:
original_data=pk.load(f)
sample_num=len(original_data['fact'])
print(sample_num)
for i in range(sample_num):
word_list=original_data['fact'][i].split() #每个样本分词后的词语列表
this_x=[]
this_sent_len=[]
current_sentence=[]
for j in word_list:
if j in punctuations:
this_sent_len.append(len(current_sentence))
if len(current_sentence)<max_sent_len: #补全本句
for _ in range(max_sent_len-len(current_sentence)):
current_sentence.append(word2id_dict['BLANK'])
this_x.append(current_sentence)
if len(this_x)==max_sent_num: #到达此样本最大句数
break
current_sentence=[]
else:
if len(current_sentence)==max_sent_len: #到达此句最大词数
continue
if j in word2id_dict:
current_sentence.append(word2id_dict[j])
else:
current_sentence.append(word2id_dict['UNK'])
sent_num.append(len(this_x))
if len(this_x)<max_sent_num:
for _ in range(max_sent_num-len(this_x)):
this_x.append([word2id_dict['BLANK'] for _ in range(max_sent_len)]) #补全本样本的所有句子
x.append(this_x)
y.append(original_data['accu_label_lists'][i])
sent_len.append(this_sent_len)
x=np.array(x)
y=np.array(y)
print(x.shape)
print(y.shape)
print(len(sent_num))
print(len(sent_len)) #list不变
to_path='/data/cecp_data/cail_small_'+k+'.pkl'
with open(to_path, 'wb') as f:
pk.dump({'x':x, 'y':y,'sent_num':sent_num,'sent_len':sent_len}, f)
big数据(这个代码实际上无法直接运行,因为数据太大了,会报OverflowError: cannot serialize a bytes object larger than 4 GiB。我看网上对这个问题倒是也有解决方案,但是我看CECP原论文里也没做big数据,所以不整了:Python Pickle报:OverflowError: cannot serialize a bytes object larger than 4 GiB的解决方法_蛐蛐蛐的博客-优快云博客_overflowerror: cannot serialize a bytes object lar)(对于没有验证集,我的解决方案是从训练集中抽出1/10样本作为验证集。变量命名参考了CTM项目的代码):
import pickle as pk
import random
import thulac
model=thulac.thulac(seg_only=True)
import numpy as np
with open('github_projects/LADAN/data_and_config/data/w2id_thulac.pkl', 'rb') as f:
word2id_dict = pk.load(f)
punctuations='。:();:“”,,' #用这些标点符号作为分句指标,并且不保留这几个标点符号本身
max_sent_num=64
max_sent_len=32 #这两个是CECP原本的设置
random.seed(20230215)
dataset_path='cail_ladan/legal_basis_data_big/'
with open(dataset_path+'train_processed_thulac_Legal_basis.pkl', 'rb') as f:
R_train_total=pk.load(f)
sample_length=len(R_train_total['fact'])
print('原始训练集中含有'+str(len(R_train_total['fact']))+'个样本')
sample_index=list(range(sample_length))
random.shuffle(sample_index)
sample_index1=sample_index[:int(0.9*sample_length)]
R_train={key:[R_train_total[key][i] for i in sample_index1] for key in R_train_total.keys()}
print('最终使用的训练集中含有'+str(len(R_train['fact']))+'个样本')
sample_index2=sample_index[int(0.9*sample_length):]
R_valid={key:[R_train_total[key][i] for i in sample_index2] for key in R_train_total.keys()}
print('最终使用的验证集中含有'+str(len(R_valid['fact']))+'个样本')
with open(dataset_path+'test_processed_thulac_Legal_basis.pkl', 'rb') as f:
R_test=pk.load(f)
data_map={'train':R_train,'valid':R_valid,'test':R_test}
for k in ['train','valid','test']:
x=[]
y=[]
sent_num=[]
sent_len=[]
original_data=data_map[k]
sample_num=len(original_data['fact'])
print(sample_num)
for i in range(sample_num):
word_list=original_data['fact'][i].split() #每个样本分词后的词语列表
this_x=[]
this_sent_len=[]
current_sentence=[]
for j in word_list:
if j in punctuations:
this_sent_len.append(len(current_sentence))
if len(current_sentence)<max_sent_len: #补全本句
for _ in range(max_sent_len-len(current_sentence)):
current_sentence.append(word2id_dict['BLANK'])
this_x.append(current_sentence)
if len(this_x)==max_sent_num: #到达此样本最大句数
break
current_sentence=[]
else:
if len(current_sentence)==max_sent_len: #到达此句最大词数
continue
if j in word2id_dict:
current_sentence.append(word2id_dict[j])
else:
current_sentence.append(word2id_dict['UNK'])
sent_num.append(len(this_x))
if len(this_x)<max_sent_num:
for _ in range(max_sent_num-len(this_x)):
this_x.append([word2id_dict['BLANK'] for _ in range(max_sent_len)]) #补全本样本的所有句子
x.append(this_x)
y.append(original_data['accu_label_lists'][i])
sent_len.append(this_sent_len)
x=np.array(x)
y=np.array(y)
print(x.shape)
print(y.shape)
print(len(sent_num))
print(len(sent_len)) #list不变
to_path='/data/cecp_data/cail_big_'+k+'.pkl'
with open(to_path, 'wb') as f:
pk.dump({'x':x, 'y':y,'sent_num':sent_num,'sent_len':sent_len}, f)
- 另外GitHub项目中还给出了CE:CECP/data/CEs at main · jiezhao6/CECP
每个罪名就是长成这样(有所省略):
放火罪&是指……行为。&本罪的主体为……。&本罪在主观方面……。&本罪侵犯的客体是……。&本罪在客观方面表现为……
也就是罪名&定义&subject&subjective&object&objective
(有些样本没有“定义”这一项)
另给出我参考的做CAIL上elements数据的代码(big数据集和small数据集差不多,略):
#这个是负责弄elements文件的
import thulac
model=thulac.thulac(seg_only=True)
import pickle as pk
import numpy as np
#标签数字到文本的对应见这个:
id2charge=open('small/new_accu.txt').readlines()
#然后CE文本是这两个:
CE1=open('github_projects/CECP/data/CEs/CEs.txt',encoding='gbk').readlines()
CE2=open('github_projects/CECP/data/CEs/CEs_supp.txt').readlines()
CE=CE1+CE2
charge_num=len(id2charge)
print(charge_num)
with open('github_projects/LADAN/data_and_config/data/w2id_thulac.pkl', 'rb') as f:
word2id_dict = pk.load(f)
def get_num(text:str):
"""输入未分词的文本,分词(LADAN官方预处理代码是不去除停用词的)→转换为数值,返回数值列表"""
word_list=[a for a in model.cut(text,text=True).split(' ')]
num_list=[]
for word in word_list:
if word in word2id_dict:
num_list.append(word2id_dict[word])
else:
num_list.append(word2id_dict['UNK'])
return num_list
def tab_num_list(num_list:list,length:int,blank_token:int=word2id_dict['BLANK']):
"""将指定列表截断或tab到指定长度"""
if len(num_list)<length:
num_list.extend([blank_token]*(length-len(num_list)))
else:
num_list=num_list[:length]
return num_list
num2charge={}
ele_subject=[]
ele_subjective=[]
ele_object=[]
ele_objective=[]
for charge_id in range(charge_num):
charge=id2charge[charge_id].strip()
if charge=='走私普通货物、物品':
charge='走私普通货物物品'
for ce in CE: #从CE集合中,找这个罪名对应的CE
if ce.startswith(charge):
#这就是那个CE
#将CE拆为罪名和4个部分
parts=[x.strip() for x in ce.split('&')]
#5或6个元素。第一个元素是罪名,然后倒数4个分别是subject-subjective-object-objective
num2charge[charge_id]=parts[0]
ele_subject.append(tab_num_list(get_num(parts[-4]),100))
ele_subjective.append(tab_num_list(get_num(parts[-3]),100))
ele_object.append(tab_num_list(get_num(parts[-2]),200))
ele_objective.append(tab_num_list(get_num(parts[-1]),400))
break
to_path='cecp_data/elements_cail_small.pkl'
with open(to_path, 'wb') as f:
pk.dump({'num2charge':num2charge,'ele_subject':np.array(ele_subject),'ele_subjective':np.array(ele_subjective),
'ele_object':np.array(ele_object),'ele_objective':np.array(ele_objective)}, f)
4.2 模型
4.2.1 环境
官方使用的环境看代码。我使用的环境是:
Ubuntu 7.5.0
Python 3.8.13
PyTorch 1.11.0
thulac 0.2.1
numpy 1.23.5
(只写了CECP官方标注的几个,比较重要的)
4.2.2 代码
我不太懂RL,所以大部分代码没看懂其实。等我看懂了再说
但是能跑。
主要要改:
- main.py的argparse的nclass和config.py的num_charges,改为罪名标签数
- 加载数据部分前面介绍数据怎么处理了,然后改一下就行
- 预训练词向量我用的是LADAN提供的,加载部分的代码:
with open('github_projects/LADAN/data_and_config/data/w2id_thulac.pkl', 'rb') as f:
word2id_dict = pickle.load(f)
embedding_file_path='cail_help/ladan_files/cail_thulac.npy'
embedding_weight=np.load(embedding_file_path)
embedding_dim=embedding_weight.shape[1] #200,与CECP的相同
embedding_weight[word2id_dict['BLANK']]=[0 for _ in range(embedding_dim)]
- 另外我还改了一下
get_train_parameters()函数中储存ckpt的位置
另外还有个比较神奇的bug,就是代码运行结束之后会报一串的BrokenPipeError: [Errno 32] Broken pipe
看报错信息,显然是报在多线程上了。这不就要亲命了吗,我哪会多线程这么高级的debug东西。
但是代码跑完了,进程也结束了,我问了作者,作者说不影响算法。嘛所以我也不管了:

5. 其他
本文与CEEN有所相似之处这一部分,CECP作者解释了一下相关的区别:(我还没认真看CEEN)
- 两篇文章确有相似之处,如基于sentence-level的表示、用到强化学习等。
- 但是两篇文章其实方法上还是完全不一样的:
- CEEN还是属于CECP论文中提到的第二类主流使用法律知识的方式“手动抽取legal attributes”,因为它没有明确引入CE知识
- 两篇文章虽然都用到了强化学习,但是所做的顺序决策逻辑是完全不一样的,CECP主要利用的不同CE之间的逻辑顺序。
The logic order of constitutive elements of crime:这是一篇中文论文:赵秉志.论犯罪构成要件的逻辑顺序[J].政法论坛,2003(06):17-25. ↩︎ ↩︎
Re7:读论文 FLA/MLAC/FactLaw Learning to Predict Charges for Criminal Cases with Legal Basis ↩︎
Legal Article-Aware End-To-End Memory Network for Charge Prediction ↩︎
Re27:读论文 LADAN Distinguish Confusing Law Articles for Legal Judgment Prediction ↩︎ ↩︎
Automatically classifying case texts and predicting outcomes ↩︎
Few-Shot Charge Prediction with Discriminative Legal Attributes ↩︎
Iteratively Questioning and Answering for Interpretable Legal Judgment Prediction ↩︎
On the rationality of quadrilateral essentials of crime composition and stick to china’s criminal legal system,也是中文论文:高铭暄.论四要件犯罪构成理论的合理性暨对中国刑法学体系的坚持[J].中国法学,2009,No.148(02):5-11.DOI:10.14111/j.cnki.zgfx.2009.02.009. ↩︎
Charge prediction modeling with interpretation enhancement driven by double-layer criminal system ↩︎


















 432
432

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











