




 该博客介绍了2021年ACL会议上的一篇论文,关注从刑事听证会记录中抽取事实信息的任务。研究对比了无监督、弱监督以及预训练模型(如DistilBERT和Longformer)在信息抽取方面的效果。数据集是加利福尼亚州假释听证会的自由形式对话,并针对11个特征进行了部分标注。实验中还涉及了基于Snorkel的无监督方法和使用BERT进行任务特定微调的分类模型。F1值在计算时对Date和numerical特征进行了分箱处理。
该博客介绍了2021年ACL会议上的一篇论文,关注从刑事听证会记录中抽取事实信息的任务。研究对比了无监督、弱监督以及预训练模型(如DistilBERT和Longformer)在信息抽取方面的效果。数据集是加利福尼亚州假释听证会的自由形式对话,并针对11个特征进行了部分标注。实验中还涉及了基于Snorkel的无监督方法和使用BERT进行任务特定微调的分类模型。F1值在计算时对Date和numerical特征进行了分箱处理。
论文名称:Challenges for Information Extraction from Dialogue in Criminal Law
论文ACL官方下载地址:https://aclanthology.org/2021.nlp4posimpact-1.8/
本文是2021年ACL论文,任务是从听证会记录文本中抽取事实信息factual information(11个手动挑选出的特征),分别测试了无监督方法、弱监督方法和使用预训练模型的方法在这一任务上的效果。
数据集是自制数据,是free-form dialogue of California parole hearings,一部分数据被标注了11个特征。
本文使用的算法为:
- an unsupervised data programming paradigm extended to weak supervision:无监督 Snorkel,有监督 WSLF(逻辑回归)
- pretrained question answering models based on DistilBERT and Longformer:QA1-2
- classification models based on BERT each fine-tuned to predict a single task:Task-FT
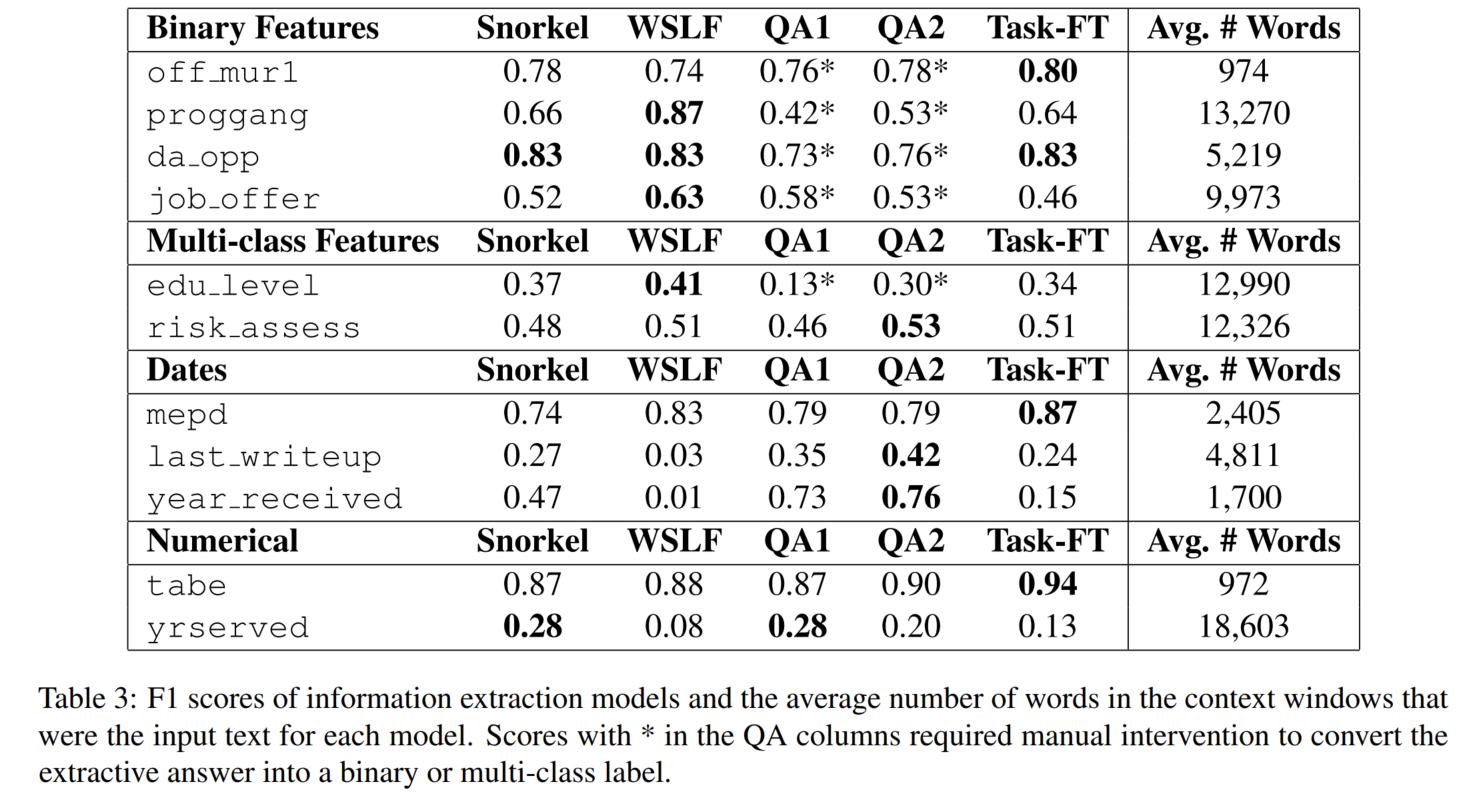
F1值在计算时,Date和numerical经过了分箱。


















 1189
1189

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











