




 该博客介绍了AAAI2021会议上的一篇论文,研究如何利用GNN改进科学论文摘要生成。CGSum模型结合了文献内容和引用关系,通过BiLSTM和GAT构建encoder-decoder框架,处理文献引用图。实验表明,考虑引用关系能提升摘要质量。此外,文章还提供了公开数据集SSN和代码实现。
该博客介绍了AAAI2021会议上的一篇论文,研究如何利用GNN改进科学论文摘要生成。CGSum模型结合了文献内容和引用关系,通过BiLSTM和GAT构建encoder-decoder框架,处理文献引用图。实验表明,考虑引用关系能提升摘要质量。此外,文章还提供了公开数据集SSN和代码实现。
文章目录
论文下载地址:2104.03057.pdf
这篇是发在AAAI2021上的NLP领域的文章,使用了GNN的方法。因为我之前是学GNN的,所以这篇论文其实没太看懂,仅此记载概述。
1. 模型构造思路
本文的两大贡献在于:第一,发表了一个公开的文献引用数据集SSN,这个事情以后再说;第二,提出了一个结合引用与文本信息的文献摘要生成模型CGSum (citation graph-based summarization model),本文仅简单介绍一下这个。
传统document summarization方法往往将任务构建为sequence-to-sequence problem,即通过文本生成摘要。
但实际上,文献之间的引用关系也对摘要生成任务有价值:文献的相关research community能帮助我们理解文献中的domain-specific terms。如下图举例,在原论文中只出现了专业术语,但在其引用的文献中出现了对术语的解释和类似语句的不同表示方式:
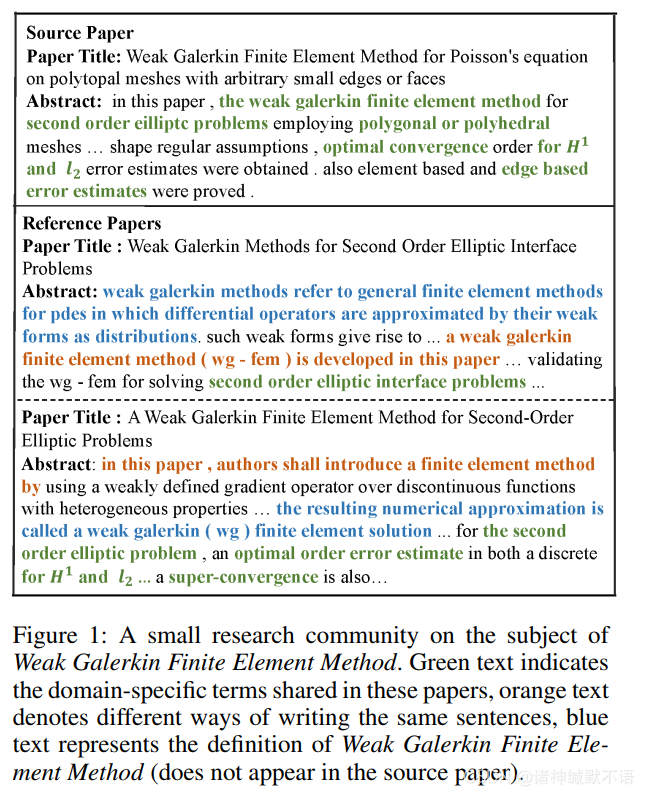
这个research community可以通过抽样出一个有source paper的subgraph得到。
模型将source paper的内容和subgraph的information分别encode,通过decoder得到abstract。神经网络模型使用的是BiLSTM和GNN。
评估指标用的是ROUGE credit method。
在本文中分别试验了transductive和inductive两种实验模式:

注意实验是将引用关系视为无向图进行的,但是抽取子图的时候是有边方向的(见模型介绍部分)。
2. Notation与模型介绍
2.1 Notation
略,待补。
2.2 CGSum
在理论上讲,作者要写摘要的时候,他肯定只能参考他引用的文章而非引用他的文章,所以在生成摘要任务中,要使用文献引用关系,也只能使用其reference而非citation。
所以在首先我们通过抽取子图生成一篇文献的research community(citation graph)时,对于某一节点(文献),我们生成一个它引用文献、引用文献再引用文献的图出来(这个图我一开始以为是树,后来想了一下,每一篇文献可能不只被research community中的一篇文献引用,所以不一定是树,反正就是一张有向图)。
建立citation graph的算法:

对每一个节点,我们利用其body text和citation graph中文献(不包括它自己)的abstract生成节点的abstract。
模型示意图如下:
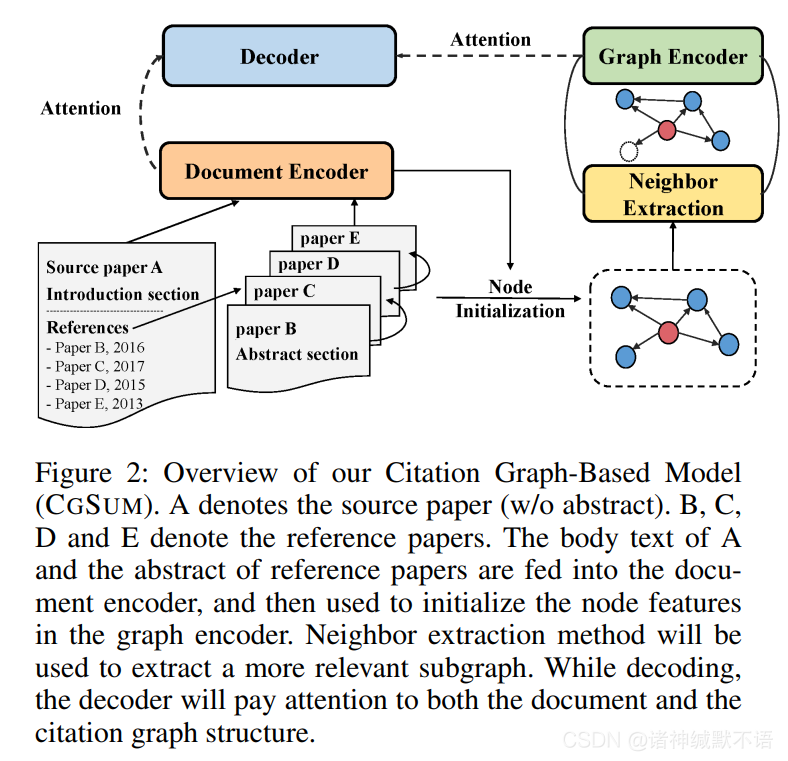
source paper的body text和reference paper的abstract传入document encoder(BiLSTM),通过池化隐藏层表示向量初始化节点特征,根据节点之间的salience score对邻居进行抽样

由于什么直接抽样会打断
f
f
f 中参数的训练的原因(为啥?因为没梯度可算了吗?)所以参考 Knowledge Graph-Augmented Abstractive Summarization with Semantic-Driven Cloze Reward.,将
s
s
s 视为information gate):

将图输入graph encoder(2层GAT,并在层间添加residual connections)。
将encoder得到的表示向量通过decoder(single-layer unidirectional LSTM)得到结果,两个encoder都对decoder有attention机制。
模型结果用ROUGE credit method进行评估。
其他略,有缘补。
3. 详细的数学推导和证明
略,待补。
4. 实验结果
4.1 baseline
略,待补。
4.2 数据集
略,待补。
4.3 实验设置
略,待补。
4.4 实验结果
略,待补。
5. 代码实现和复现
5.1 论文官方实现
虽然使用的DGL和FastNLP等包我没用过,但是看起来还是意外比较清晰的一个代码结构。学了之后应该可以过来看一下。
5.2 我自己写的复现
还没写,待补。


















 722
722

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











