




 本文介绍如何遵循robots.txt协议抓取特定网站数据,如豆瓣《小王子》评论,利用requests库处理不同格式响应,结合beautifulsoup或正则表达式高效提取结构复杂数据。
本文介绍如何遵循robots.txt协议抓取特定网站数据,如豆瓣《小王子》评论,利用requests库处理不同格式响应,结合beautifulsoup或正则表达式高效提取结构复杂数据。
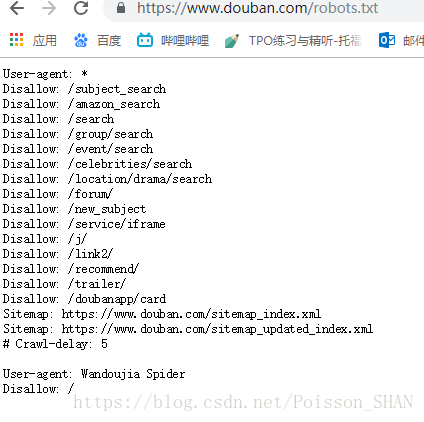
有的网站会提供一个爬虫协议文件robots.txt
例如豆瓣的爬虫协议:https://www.douban.com/robots.txt
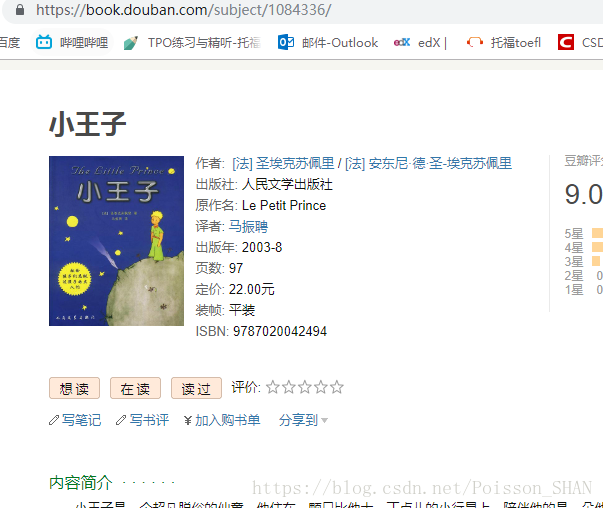
这里我们要对《小王子》的豆瓣评论进行抓取,需要用到的是subject这个目录,在豆瓣网页的爬虫协议中,并没有禁止这项操作。
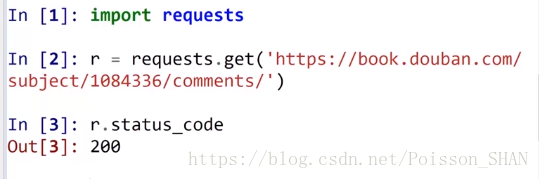
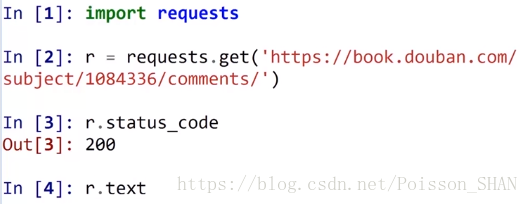
200表示一切正常
抓取源代码:
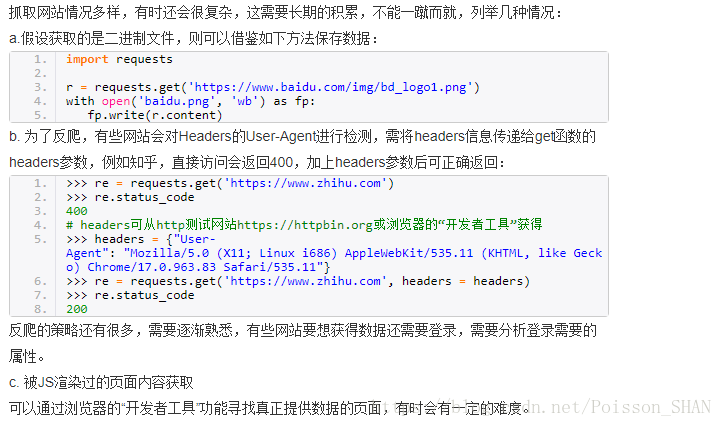
注:
1、响应内容是二进制,要用r.content 来解码(比如抓取图片时,生成的数据是二进制码)
2、如果网页格式是json格式,要用可以用requests库中内置的json解码器来解码:r.json()
3、r.text可以自动推测文本编码并进行解码
4、通过encoding这个属性去修改文本编码,常用encoding = ‘utf-8’
利用beautifulsoup或正则表达式提取数据
对于数据结构比较复杂的数据提取,更适合使用正则表达式模块


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









